-
Modeling in Custom Instruments
Custom instruments make it possible to profile your app your way, telling the story of what your app is doing at runtime. At the center of each custom instrument is a modeler. Find out how to build your own modelers that translate from signpost output to the data you want to show in your instrument. Learn how the Instruments rules engine works and how to optimize your instrument for maximum efficiency. This session builds on Creating Custom Instruments from WWDC 2018.
Resources
- Creating custom modelers for intelligent instruments
- Instruments Developer Help
- Presentation Slides (PDF)
Related Videos
WWDC19
WWDC18
-
Search this video…
Thank you.
Alright, good afternoon. My name is Chad Woolf. I'm a performance tools engineer for Apple and this is session 421, we'll talk about modeling in Custom Instruments.
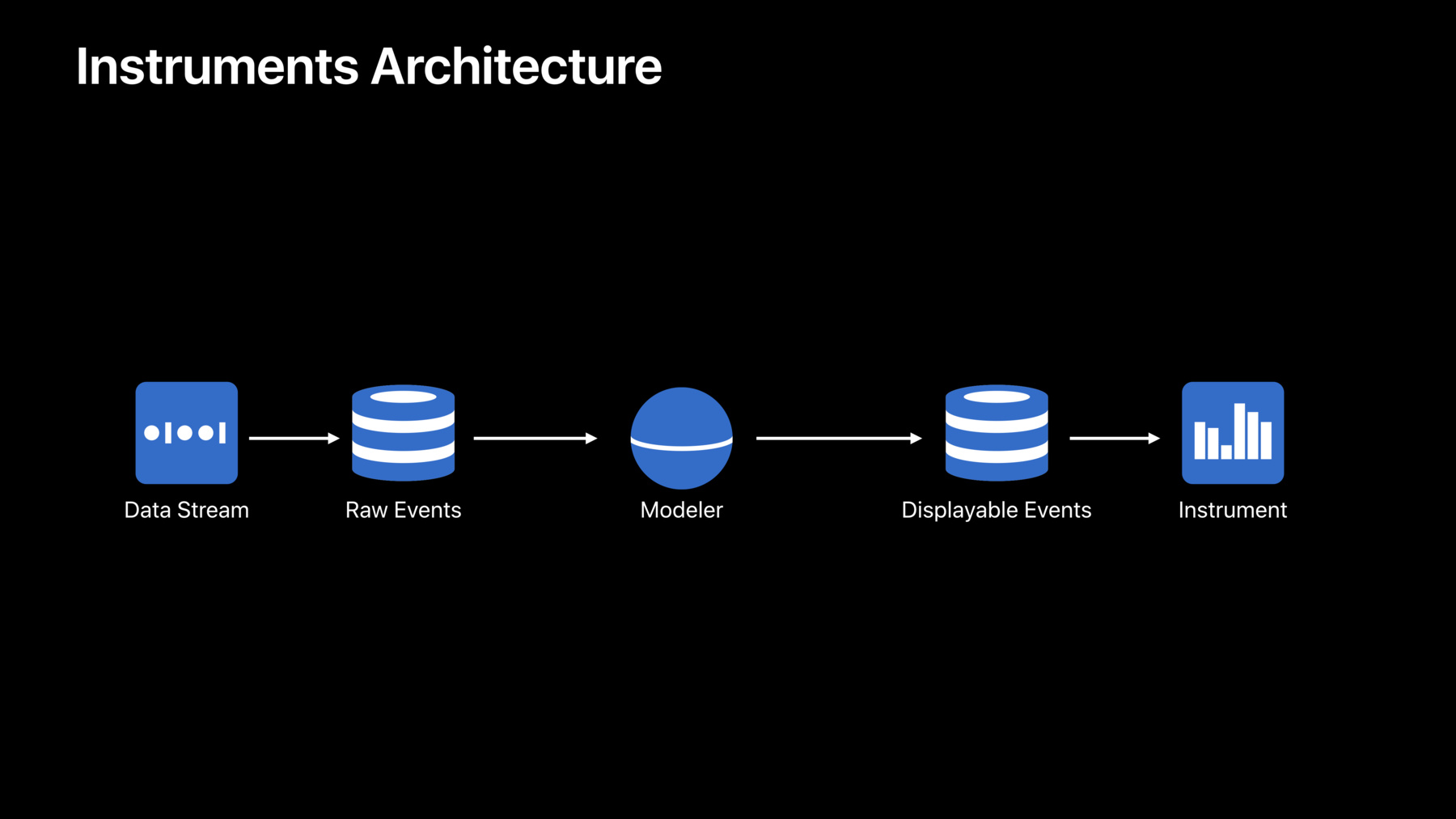
Now, within the Custom Instruments Architecture, modeling is done by this piece in the middle here called a modeler, and the modeler's job is really to reason about the raw events that are being recorded by the operating system, perform some transformations, and create the displayable events or the input to another modeler for instruments in the Air Instruments UI.
Now, this architecture was covered in its entirety in our 2018 session, Creating Custom Instruments. So in this session, what we're going to do really is just take sort of a spotlight focus on this piece in the middle, called a modeler.
Now modelers are important to all of our instruments including the Time Profiler up here.
Now in the Time Profiler, the data that you're seeing presented in the UI is not exactly the same as being recorded by the kernel.
We use a modeler to do some transforms.
So now when the kernel takes a sample of what your thread is doing, it creates or captures what's called a primitive backtrace, and it puts that into the time sample table, which is then picked up by the Time Profiler modeler, which is then transformed into a more displayable form of the backtrace, which goes into the Time Profiler table, which is ultimately viewed by the Time Profiler instrument. Now, the reason we do this is because it's a lot simpler and thus more efficient to capture these primitive backtraces, and then we can fix them up in user space later inside of our modeler and therefore we keep that recording side in the kernel very efficient.
Now, another kind of optimization that's made by the kernel is if the kernel samples a thread that it knows hasn't moved since the last time it samples it, instead of taking a full back trace, it just puts a placeholder backtrace into the time sample table and then our time profiler modeler picks that up, takes the last known backtrace for that, and replicates that into the Time Profile table that's viewed by the Instrument.
Now, this does two things. It saves a ton of space in the kernel's recording buffer, especially if your threads are mostly idle. And it also keeps the UI efficient, because the UI doesn't need to know about this placeholder convention because that's all been normalized by our modeler.
So, you're going to see these themes repeat in today's session. And that is basically to take the complexity of your custom instrument and absorb that in the modeling layer. And that will promote simplicity in other areas, specifically when it comes to the tracing code that you embed inside your logic and also the UI that you use in Instruments. So, today's session looks like this. We're going to review some modeling basics and then we're going to walk you through the process of building a custom modeler.
When you get to build a custom modeler, sometimes it's tough when you do it from scratch. So, this year we have sample code attached to this year's session, so you can follow along with that, or use that as the basis for your own modelers. Now, in the process, we're also going to talk about execution and the rules engine, Cliff's rules engine. And also an important topic called speculation. So, let's start with reviewing some modeling basics. Now, when you create a modeler, you also have to define the other pieces of that architecture as well. So, you also have to define the schemas that will glue all this together in the Instrument, which will ultimately view the output of your Instrument. And that all gets built into an Instrument's distribution package, which can then be installed inside of Instruments and tested.
Now, at this point we're going to assume that you already have one of these projects set up in Xcode. And really, what you're looking to do is add a custom modeler or you're going to be working from our sample code that's attached to the session this year, and you're going to have that project already set up. Now, when do you need to create a custom modeler? It's true that Xcode will generate modelers for you, in some cases specifically when you're using OS Signpost as your input. But these modelers are really meant to get you an Instrument up and running quickly. They're not really there to expose the entire feature set to you that you can do with custom modelers.
Such as being able to fuse data from multiple input tables. That's something that you can do with a custom modeler. You can't do it in the generated case.
And more importantly, maintain a working memory. This allows your modeler to keep some running totals. To track open intervals. And perform some more extensive calculations using the modeler's working memory. Now, another thing that you can do is create custom graphs. If there's a graph that you'd like to create but Instruments doesn't do it natively, you can synthesize the data inside your modeler. For example, maybe you can compute a running average or something as sophisticated as a Calvin filter. It's really, it's up to you and you can do all of that in a custom modeler. Now, ultimately the goal here is really to build smarter and smarter instruments so that the instruments know what's going on in your code. And it's to even reach a point where the people who are working with your code will turn to your Instruments first before they turn to you for trouble shooting, and that'll kind of free you up to work on the next great thing.
Now, a modeler is basically a rules engine that is bound to a set of input tables and a set of output tables.
The Instrument's analysis core takes on the task of time ordering the input tables and injecting them into the modeler's working memory. Now, objects in the working memory are called facts. And the way that you reason about the changes to the working memory and these facts is by defining a rules system in the CLIPS language. Now, CLIPS is an open source language. It's been around since the '80s, so there's lots of great examples and documentation to help you get started and there's a lot of great examples in our sample code and also in our slides today.
Now, ultimately when your modeler discovers something that it wants to output, there are functions in the modeler as well to write to the bound output tables. Now, to get started writing a modeler from scratch, we have a three-step process that starts with basically deciding what you want to model. Now, this means understanding the technology you're creating a Custom Instrument for. And it also means knowing how the Custom Instrument's infrastructure works and how to really get the most out of it. In our 2019 session, Developing a Great Profile Experience, our team will walk you through the process of trying to tell a story of what's going on with your code using Custom Instruments, so that's a great place to start with understanding what your'e trying to model. All right, so now that you have the output defined for your modeler, it's going to need some input. And the best way to get input into instruments from your code is through the OS Signpost API. This is an API that you can sprinkle throughout your code to basically trace what's happening in your code and pass argument data, gives your modeler something to reason about in your input stream. Now, once you have your inputs and your outputs, then it's time to start defining your rule system and start writing your rules. Now, we know that steps two and three are going to be iterative. So, as you write your rules, you may discover that you need to go back and add more Signposts or that you need to change your Signposts, which is totally fine. You can do that. But keep in mind that your Signposts re going to really form the boundary between what's going on in your code and your Instrument. So, at some point you're going to want to, like, make sure that you comment those Signpost invocation calls and let people know that that's really a contract and it'll break your instrument if you modify it. All right, now we think that this process is probably best understood with a practical example. So, I would like to now turn it over to our modeling expert, Alejandro Lucena, to walk us through.
All right. Good afternoon, everybody, and thank you, Chad. So, what I'd like to do is I'd like to go through this thought process that Chad just highlighted and apply it to an example so we can see how all these pieces fit together.
And to do that, I want to start off with this demo app. And full disclosure, this is probably the coolest thing I have ever worked on and it's a list of goats, right? Now, these different goats don't just have themselves displayed on this app. The app also lets me sort the list. Now, the sorting is implemented using something we call the mobile agent pattern.
And this pattern has a lot of parallels to different patterns that you may be using such as futures and promises or operation queues. So, whenever you hear the term mobile agent, when we're talking about it, you can mentally substitute that in for whichever pattern you're using. But we'll stick with the mobile agent pattern for the purposes of this session.
So, as the name implies, the mobile agent pattern has a very important concept which is that of a mobile agent.
And we'll visualize the mobile agent as this circle in the upper lefthand corner.
Now, the goal of an agent is to take a task such as sorting a list and really breaking it down into a few subtasks such as obtaining the initial list and then sorting it, and then committing the results, with each of those subtasks being executed at what we call stops.
And stops can provide the agent with some sort of dependencies or execution context for it to achieve its subgoal.
So I want to take a look at how we can implement something like sorting using this mobile agent pattern.
Now, what we'll do is when we click the sort in the upper lefthand corner, the agent is going to move over to its very first stop. In this case, the stop is hosted by a UI and it will execute its first subtask of obtaining the list.
Now, once the list is obtained, it can move over to a different stop, such as one hosted by a dispatch queues. And at that dispatch queues stop, it can then perform the actual sorting.
And once the sorting is complete, it can move back to the UI to end up populating the list with those sorted results.
And finally, it can park itself back at the sort button for future use.
So, what we just saw is that the mobile agent pattern, or really the agents can be in one of two primary phases. They can either be executing at a stop, or they can be moving over to a stop. And this is what we're interested in modeling. And more specifically, we're interested in seeing the duration of these things, how long they take and the interactions between them.
And to better visualize this, I want to go through the sorting example again but put these intervals into perspective. So, what I'm going to do is I'm going to move this device over to the lefthand side because we'll need some space.
So again, when we click the sort button, the agent is moving over to that UI stop.
And as soon as that movement happens, we want to see an interval with maybe some descriptive string or something telling us what happened.
Next, we know that at the stop, the agent is going to perform its first subtask, which is getting the list. And we see that in a different interval here. Next, the agent is going to move over to a dispatch queues, and that'll be represented by its own interval.
At the dispatch queues, the agent will perform some sorting, and we see it; it's executing in the sorting mode.
Before it finally moves back over to the UI stop and we have a final movement interval, moving back to the UI. And at that stop, it will execute the next, or the last, subtask of filling in the list with the sorted results.
So, with these intervals, we can really think of the beginning of the interval as being the time at which the activity started, either execution or movement. And the end of the interval being the time at which that activity ended.
And with these intervals in mind, we can have or we can design some instrument that we'd like to see, and that's precisely what I have behind me now.
Here in the topmost track, I have al these intervals together and we can see the different movements and executions.
And beneath that very topmost track, we have the different stops that were active during the trace.
Now, on top of the visual aspect of the instrument, we also want to see a detail view. And the detail view will give us some more information about what happened at each stop, such as the time that it started, how long it took, which agent was there, and so forth.
Now, at this point, we should notice these columns at the top. Because these columns are how we define what we're interested in modeling.
Here, the columns tell us that this is a start time and a duration and an agent kind, but more generally we specify these columns in our Instrument's package files written in XML.
And these columns collectively form our output tables.
Which brings us to our very first checkpoint. And that is that with these columns, we define what it is that we're trying to store. And that fulfills the first goal of deciding what it is that we want to model. And now that we have that, the next thing we need to do is get data from our application into Instruments, and we'll accomplish this by using OS Signpost.
So, let's take a look at our intervals again.
We have these.
And we do have an API that utilizes OS Signpost, that is natively built for intervals.
But we want to take it one step further and specifically I want to use event Signposts. And each of these event Signposts will be emitted at the borders between the activity intervals. And the reason for doing this is not only because we get to save roughly 50% of the amount of Signposts we would otherwise emit. But this is actually a more accurate representation of the mobile agent pattern.
Specifically, when an agent is done with the current activity, it will immediately begin another one, and so we can just emit a single Signpost that tells us that it's moving on to the next thing. And in order to accomplish this, here we have an execute stop function that is part of the mobile agent class. And before we perform the actual internal logic of executing whatever it is that we're doing at that stop, we have a Signpost that has a name, a specific Signpost ID and a message that we'd like to embed.
In addition to that, we have the same sort of OS Signpost setup within this visit next stop function, which implements the logic of moving an agent from one stop over to the next. And again, before we perform the movement, we title it appropriately such as mobile agent moves, then we give it another Signpost ID and a message.
But now we've really got to focus on this middle piece which is the modeler, and the modeler is what's going to transform those Signposts that we just put into our app into the usable intervals that we want to see in the output table. So, I'd like to give you an example. Here we have a modeler, and this modeler starts off with a blank view of working memory, because it doesn't really know anything about the state of the application yet.
But what we do know, however, is that the modeler interacts very closely with the OS Signpost table. And the OS Signpost table is populated from our application.
So, let's consider the case of the modeler trying to detect a mobile agent from the Signpost.
While when we click the Sort on our demo app, the modeler is going to receive an OS Signpost. And the modeler will represent that Signpost by a fact. And that fact has its slots filled out according to however we made the OS Signpost call. Now, at this point the modeler sees that the OS Signpost fact is actually advertising a lot of information about a mobile agent. And so the modeler can use that OS Signpost fact to deduce the agent and introduce it into working memory by asserting a fact. In this case, it's asserting that it knows that there's a sorting agent that's moved to the background. Next, the modeler should determine the activity that the agent was doing, such as what it was actually, you know, trying to do as well as the time.
So, the modeler can look at the facts already and say, or it knows that it has a mobile agent that was moving. And it sees the Signpost fact and that it started at time 42. And the modeler can again make note of that by introducing another fact into working memory that tells us that it started at time 42. Now, at this point the Signpost facts go away but that's okay, because we kept all the relevant information in the facts that we asserted into working memory ourselves.
So, I'll move these facts up a little bit, because we need some space. And the last thing that the modeler has to do here is determine the full interval of the activity. Right now we only have the start time. We don't really know the entire interval. But we know that at some point our demo app is going to emit another Signpost. And again, when the modeler receives it, it will represent it as a fact accordingly.
And because we structured our Signposts such that they were emitted at the borders between these intervals, the modeler now knows that when it receives another Signpost, it can look at any open interval facts that it previously had open and close them.
In this case, the modeler is going to look at these values from the facts that it has, and it has enough to determine the full interval. And to do that, it'll summon the output table and then remove that open interval fact that it had to replace it with a full interval. In this case, moving it to the background.
And use that interval to populate the output table. All right.
Now, before delving into some CLIPS code that actually goes through all this, I think it's important to understand how an API call from our application code translates to a fact within CLIPS.
Specifically, when we call OS Signposts with a particular name, that name becomes the same name slot in the OS Signpost fact.
Furthermore, the type of Signposts that we have, in this case event, becomes the event-type slot within the OS Signpost fact. And lastly, the Signpost ID becomes the identifier value within the OS Signpost fact as well as a message. The message that we embed also takes on the message value within the OS Signpost fact.
So, now that we know that, we can try to look at some rules to detect a mobile agent. Here we have a rule written in CLIPS, and the first thing that it's trying to do is to detect the presence of an OS Signpost that has a particular name such as mobile agent moved.
And what we'll do is we're going to capture the value that's held within the identifier slot in this instance variable.
Additionally, we can perform some parsing on the message to extract any useful information that we see from there.
And now in the second part, we have one more condition that we'd like to express, which is that we're trying to match against the absence of a mobile agent that has already been identified by the Signpost. Signpost is what we're going to use to identify mobile agents, but we don't want to introduce any duplicates. So, here with the knot keyword, we're telling the modeler only do this if you don't already have a mobile agent that has been identified with this instance variable. And if that's the case, the modeler can go ahead and assert that mobile agent into working memory.
Likewise, when we're trying to detect what the mobile agent was doing, we match against the OS Signpost fact again, because we'll need that to determine some properties.
But in this case, we omit the use of the knot keyword, because we really do want the presence of this agent fact to live in our working memory. So, we know that we have already parsed the agent and we can do something more with it.
Specifically, once we do have these two facts present, we can assert or introduce that movement fact so that the modeler can keep track of what the agent was actually doing. All right, so we've seen some examples of how we can write CLIPS code to detect agents and activities that they were doing, but we need to learn a little bit more about the underlying execution to help us structure our modeler a little bit better. And in order to do that, I want to invite Chad back onto the stage to talk to us about rule execution.
All right, so let's talk about rules execution in the CLIPS language in Rules Engine.
All right, when we define Rules in CLIPS, they're defined with a lefthand side and a righthand side separated by a production operator. Now, lefthand side is really the declarative part of the language. So, this is where you define a pattern that you want the rules engine to find in the working memory of facts.
And when the Rules Engine identifies a set of facts that satisfies that pattern on the lefthand side, it creates what's called an activation. Now, for each activation, it will fire the righthand side of the rule. Now, the righthand side of the rule is really the imperative part of the language. This is where you have access to functions like retract, which allows you to remove a fact from working memory.
Or assert, which allows you to add a fact into the working memory.
And also some specialized functions that allow you to write to the output tables of your modeler so you can write the output.
Now, let's talk about facts for a minute. When we assert a fact into the working memory, we use our assert function. And each new fact is assigned what's called a fact address, and they're identified with a lowercase f, dash, and then some unique number.
Now when we want to modify a fact in the working memory, we also have a modify function which takes the fact address and the slots that we'd like to change on that piece of the working memory.
Now, this is actually implemented as a combination of a retraction and an assertion. So what happens here is we first retract the fact from the working memory, make the change, and then reassert it back into the working memory with the updated fields or updated slots.
Now, this is important because when you reassert something into the working memory, it will refire and potentially reactivate some of those rules, which exactly what you want in most cases because that's how your rules system is going to react to the changes you're making to the working memory.
However, this can lead in some cases to a complication I like to refer to as a logical loop. So, let's see how we might have accidently created a logical loop in our code. So, we have this pretty small rule here. And what it's designed to do is to count the number of mobile agents-- mobile agent instances that have appeared in the working memory.
So, it starts off with a counter fact, with a slot that's initially zero.
And for each mobile agent that gets placed into the working memory, it will fire the righthand side of the rule which simply modifies the counter by bumping the count slot up by one. Now, this sounds pretty straightforward.
However, let's look at it when it actually executes.
So first thing, we start off with our counter in working memory with an initial count of zero.
And let's say at some point in the future a mobile agent is asserted into the working memory. Now we have enough on the lefthand side to fire the righthand side. So, that will call our modify function which will first do a retraction of that fact.
It'll modify by increasing the count value, and then it will reassert it back into the working memory. Now when we do this, notice that it refired that same rule.
So now for that same mobile agent instance, it's going to count two, three, four, five, six, seven, right. It's going to keep going on and on and on until eventually the trace stops and instruments tells you this was a fatal error and that the rules engine appears to be stuck.
Now, in the Instruments Inspector in the console of your modeler, you'll see trace, which indicates all the events and activations that were happening during that loop. So, that'll give you a head start on how to debug that and get out of it. Now, the easiest way, in my experience, to get out of a logical loop is to do what I call a little bit of goal-oriented programming.
So instead of modifying the counter fact directly, what we do is we create a goal fact to bump the counter for us. And now this time when we detect a mobile agent instance, we assert a goal fact to count that instance. And then in our counting rule, we capture the counter and the goal and we retract the goal because now it's being satisfied when we bump the counter. And that's going to keep that rule from coming back through and that's how we've broken out of that logical loop.
All right, now let's talk about the firing order of our rules and how that might change the outcome of our modeler.
So, let's return back to our execute stop function. This is what's called right before a mobile agent goes into its executing stage. And now you'll notice here in our OS Signpost, that first argument in our first version of the code, we're actually using the agent's type string.
Which in this case would be sorting agent or it's about 14 bytes of data that has to be logged into the trace buffers. Now, we think we can improve on that by changing it from a string over to a type code. Now, this is only going to be a four byte integer which is going to save us about 10 bytes per event. And if these things are coming in by the thousands, which they are, it's going to save 10s of thousands of bytes in the tracing buffer.
Now in order to do that, we're going to have to create some mapping inside of our modeler that coverts that code over to that string, and so we're going to use facts to do that.
And this time, in our detection rule, we're going to capture the agent's type code and when we assert our mobile agent, we're going to assert it with a kind slot that's the symbol sentinel. It's going to indicate we haven't set the full string yet.
Because on a second rule, what we're going to do is look for any mobile agent that has a kind of sentinel and we're going to find for that corresponding type code, the type string map that you saw on the previous slide. And once we have those two pieces, we'll modify the kind slot, changing it from the symbol sentinel to a real string.
Now, this whole design really relies on this second lookup rule, firing immediately after we perform the assertion.
But what happens if another rule in our system, for example our agent parked rule, which also references the mobile agent and captures and uses the kind slot. What if it happens to slip in there between the assertion and the lookup rule? Well, it's going to see a kind of sentinel. And since this is a change we're making to our rule system, it might not be ready for that. We have a whole new set of bugs now.
So, one way to work around this is to add a restriction to that rule that says as long as the kind is not equal to sentinel and that effectively delays the rule firing until that lookup rule does change the agent's kind from something, from sentinel to something real. Now, you can certainly do this but you're going to have to do this to all of the rules. And so that could be a little bit of a maintenance problem if you already have an existing rule set that assumes that will never be sentinel.
So, let's look at another alternative way to do that. Now, really what we're trying to do is get that lookup rule to fire immediately after we perform that assertion. And one of the ways that we can do that is by telling CLIPS that that specific rule is more important than or more salient than the default salience of zero.
Now, as long as that rule is the most salient rule in the system, as soon as our first rule finishes, that second rule is going to be the one that fires. Now, if you're using salience in other locations, you're going to have to go through your code and make sure that 100 is still the highest salience value, but that's another way to ensure that. Now, there is a little bit more direct way to control the rule ordering and the rule firing, but that requires that we learn a little bit more about activations.
So, a reminder, an activation is basically a combination of facts in the working memory that satisfies the lefthand side of our pattern. And for each activation, we fire the righthand side of the rule.
Now, we don't fire the righthand side of the rule immediately. Instead, what we do is the activation is logged to a data structure called the agenda, or an agenda.
Now, an agenda is basically a list of activations that have resulted from a working memory update, and so all the rules engine needs to do is start from the top of that list and work its way down, firing the rules in that particular pattern. So, here we've fired the first rule, now we come down to the second rule. Now, this data structure is dynamic, so if rule 99 here were to retract fact 17, and fact 17 is being referenced by these other two activations, CLIPS will first retract those activations before moving forward, and then thus the agenda will look like this when execution resumes. Now the agendas are ordered by salience, so that's where salience comes into play. The higher salience, the higher it appears on the agenda.
But the more important part here is that there isn't a single agenda on your modeler. There's actually one per module that's defined. And we take advantage of that in the analysis core by defining a couple of standard modules for you.
The first one being the modeler module, and this is where you're going to want to put your pure reasoning logic and your reasoning rules in this module, by prefacing the rule name with modeler colon colon. And we defined a second module called a recorder module that, this is where you're going to want to put your output writing rules, by prefacing those with recorder colon colon. And the reason you're going to want to do that is because when we execute these rules, we execute everything that's on the modeler's agenda first until it's completely empty before moving over to the recorder's module. And so what that allows you to do is have confidence that when you're having an output writing rule, you're not looking at working memory that's in the process of being reasoned in the modeler module.
Now, you can take advantage of this yourself by defining your own custom modules in CLIPS. And so let's take a look at how we could do that to better adjust our lookup rule execution. So the first thing we want not do is define the module for our lookup module.
Now we want to place our lookup rule inside that module by prefacing it with lookup colon colon.
Now, when we assert a mobile agent fact, immediately the next thing that we do is tell CLIPS to focus on the lookup agenda. Basically run all of the activations that are in the lookup agenda before returning back to the modeler's agenda and thusly executing the next set of modeling rules. So, that's a great way to slip rules in between execution in the execution order.
All right, so that gives us enough information now and we can start taking a look at how to start debugging and profiling. And in order to do that, I'd like to ask Alejandro to come back up to the stage and walk us through that.
All right, thank you Chad.
What I'd like to do is talk about some of the debugging and profiling primitives we have available to us when we're building these models.
Starting off with logging.
Now, the logging primitives that we have available to us are very similar to print f, in that we can specify a format string, format flags as well, and the variables that we'd like to represent those types.
Now, unlike print f or just normal use of print f, through the Instruments Inspector, we actually have the ability to dynamically enable or disable these log statements, and we'll see an example of this very shortly.
Now, how do I actually get these logging statements into my rules? Well, there's a function in CLIPS which is log narrative. And log narrative works, as I mentioned, very similarly to print f in that we can specify a string, such as resolve agent kind code, and then we specify the format type using percent and then the actual engineering type, in this case UN 64 and then a percent sign to string, followed by the variables that we'd like to take on those data types.
Now, likewise, we can also enable different type of primitive here which is profiling through the Instruments Inspector, and the profiling primitive gives us things such as rule activation counts so we can see how many times certain rules fired as well as a time distribution so we can see how much time in seconds and percentage wise we spent activating certain rules.
Now, to put all this in context, I'd like to switch over to a demo and I'll show you how all these things work together.
So here with me I have the sample code that is again available to download. And within the sample code we have many different targets that you can use.
But the one that I like to start with first is this plot templates modeling target that we can see over here.
So, this will actually open up instruments when I build and run it.
Looks like the build succeeded.
And we can open up instruments accordingly.
Now what I'll do here is I actually have the goats app already pulled up, so I won't maximize the screen, because we're going to need to keep this in mind here.
Initially what I'll do is I'll go to the blank template and in the upper righthand corner, I can select an instrument that I'd like to add. And so to do that, I'll go ahead and go here and start searching for the mobile agents target that we just built. Now within here, again I mentioned the log narratives can be enabled or disabled dynamically via the Instruments Inspector. So using command i, I can open up the Instruments Inspector and here in the login tab, by default it's set to none. Butt I can switch that over to narrative, and that will enable these log narrative statements.
So, I'll go ahead and close this. And instead of all processes, I'm going to switch it over to this goat list app.
So, I'll start recording. And here in the goat list I can perform some actions such as sorting the different list of goats. And I see some activity popping up here in instruments.
I can click it again and we'll see some more activity popping up, but I think that's enough to demonstrate the purpose here.
First I'd like to zoom in and show the different intervals that we were talking about previously such as activating and the movements and everything.
But to see the actual log narrative statements, again, I'll open up the Instruments Inspector using command i.
And we got something new. We got this modeler log table. And in this modeler log table, that's where all of our log narrative statements will live, such as this resolving agent kind code that we saw in this example of how we use log narrative. In addition to many other ones that we have in our rules. Now, how do we switch over from using log narrative over to profile. Well again, in this login tab, I can switch over to something like profile 1, and I'll close out of the Instruments Inspector and try running Instruments again. I'll re-record the trace.
Now I realize that this is already sorted but we can still get some activity happening from the mobile agents. And that should be enough again to demonstrate the purposes.
So, I'll stop and I'll open up the Instruments Inspector again.
There is no more modeler log table because we don't have any log narratives to show.
But if, however, I go to this modeler's tab up here, I can actually see a very nice descriptive view of these different profiling values, such as this rule, this lookup unknown stop for execution got 7 entries in the amount of time that it took and percentage wise as well, in addition to many of the other rules that I've specified in my modeling. Now, before closing this out, I did notice something particularly interesting. I'm going to rerun the trace once more because I want to capture it one more time.
I'll start the sort and I see these different activities coming up.
But then if I sort again, I notice that I get these long orange intervals coming in after the fact. They don't really follow the same live description or the live rendering that I expect with this Instrument.
Now, there is a reason why this happens and in order to talk us through it and how we can find a solution for this, I want to bring Chad back on to talk about speculation.
Hi. Thank you, Alejandro. All right, so to describe the phenomenon that Alejandro was seeing, or work around it, we have to introduce a concept called speculation. And now what happened with those intervals? What makes them unique is first they're long intervals. They appear over or they extend over a period of several seconds, so it's more obvious, more visible.
But secondly, the real problem is that the only record of these intervals that exists is sitting in the working memory of your modeler. Now, your UI is actually looking at the output tables in your modeler, so it's not able to see those. And we can't really write those intervals into the output table until we know, you know, when they're going to close. And that's what you're seeing in that particular case.
Now, what we really want to do is be able to write like temporary or placeholder rows into the output tables of our modeler. And to do that, we've introduced a concept called Speculation mode.
Now, Speculation mode in your modeler really says if this were your last chance to write to the output tables, what would you write right now? So, let's look at an example here.
Let's say our modeler has processed all the data up until this white line here, which we call the event horizon. The event horizon is a point in time after which the modeler has no visibility. Now, that could be due to the fact that the trace just ended, or it could be that the analysis core hasn't filled in that portion of the trace yet. And so it's unaware of what's on the other side of that line. Now, do you see that we've created an interval that says moving to the background. And we can do that because it is nicely bookended between a moving and executing Signpost pair.
But we don't know where that followup executing interval's really going to end because it's ending event is on the other side of the event horizon. So what we want to do is when we get into speculation mode, just write a temporary placeholder event into the tables so that the UI can see something and we're going to run that interval basically from the executing Signpost up to the current value of the event horizon.
Now, you know that your modeler's in Speculation mode because you get a Speculate fact that's going to be injected into working memory.
And in your recorder rules, you can combine that Speculate fact with any interval facts to write those open intervals into the table with the captured event horizon timestamp. And that's your opportunity to write the open intervals.
So, let's take a look at example rule that we might define here.
So first off, we're going to put our speculative output writing rule in the recorder module. So, prefix it with a recorder colon colon.
Now, we're going to match on the Speculate event, capture the value of the event horizon. So, we have the end time for our interval, our theoretical end time.
Now, for each open interval fact sitting in the working memory, we're going to fire the righthand side of the rule.
And what we're going to do here is compute the duration based on the end time which is the event horizon and start time which is whenever the interval started.
And then you create a new row and fill out the columns just like you would in normal output writing rule. Now the only difference really between a normal output writing rule and a speculative output writing rule is that you're testing or predicating this rule on the Speculate fact, and you're looking at the open intervals instead of the closed intervals, which you'd normally be writing into your output table.
Now, when you're in immediate mode, what happens is that as that recording head moves forward, the older speculative data is purged and your modeler enters into speculation mode again with a new value of the event horizon and you're able to put those speculation events back. And the UI just continues to update like normal.
Now when the trace stops, your modeler will enter Speculation mode one more time. But whatever you write now will actually be recorded and saved in the real trace data and become available to downstream modelers, not just the UI. Now, if we make that change to our existing instrument, it'll start working like this now where you have our mobile agent trace and now you see this parking interval continuing to grow here at the end. And it updates in real time. If you look in the detail table on the bottom, you'll see the duration continuing to grow.
Now, when we press stop and end the recording, you'll notice that the interval sticks around. It's actually been recorded and will be saved as part of the trace.
Now in summary, we know that writing custom modelers represents a significant investment, both in your time and learning a new technology. But it's really the best way to get the most out of custom instruments and to add intelligence to your custom instruments. And as we've seen, an intelligent instrument can lead to a more efficient recording mechanism and a much better user experience.
So for more information, we have our attached sample code, also some related sessions on our sessions webpage. And that about does it for today. Thank you very much. Enjoy the rest of the show.
[ Applause ]
-