-
Introducing Low-Latency HLS
Since its introduction in 2009, HTTP Live Streaming (HLS) has enabled the delivery of countless live and on‐demand audio and video streams globally. With the introduction of a new Low-Latency mode, latencies of less than two seconds are now achievable over public networks at scale, while still offering backwards compatibility to existing clients. Learn about how to develop and configure your content delivery systems to take advantage of this new technology.
Resources
- Enabling Low-Latency HTTP Live Streaming (HLS)
- HTTP Live Streaming Tools
- HTTP Live Streaming (HLS) authoring specification for Apple devices
- Presentation Slides (PDF)
Related Videos
WWDC20
WWDC19
-
Search this video…
Hey .
Good afternoon.
Good afternoon, everyone.
My name is Roger Pantos and our HLS session this year is all focused on Low-Latency.
So, first of all, what is this latency thing we're talking about when we say low-latency? Well, in this context, it refers to the amount of time from when a camera records a frame of video or hits your production backend. And when your user, sees that frame at home watching on their iPad or Apple TV.
And shortening that duration, keeping that small is crucial to certain types of content.
Now, the one we're probably most familiar with are live sports.
But it's also important for late-breaking news, for things like live streaming of games, and even for things like the Oscars. Really anything where there's a lot of people watching the same video at the same time. And usually, there's a social component to it.
So, how low does that latency have to be to provide a good user experience? Well, the gold standard today is around two to eight seconds. And that's what's provided by the current suite of television broadcasters, cable satellite television.
And so, when we design Low-Latency HLS, we set ourselves a target of one to two seconds delay from live at scale over the public internet with any kind of reasonable round trip time.
Now, we did that without sacrificing anything, any of the features that make HLS so compelling. So we still adapt the quality to match the user's network speed. We still allow you to protect your content. We still allow you to insert ads and provide program boundary and other metadata. We still enable you to scale your broadcasts to hundreds of thousands of users using commodity CDNs cost effectively. And we're making sure that these streams are backward compatible. So you can still see them at regular latency on older clients.
So, how do we do all that? Well, to understand that, first, we have to go back to regular HLS and see where we're starting from.
So, first of all, from its inception, HLS was designed to be a simple and robust protocol. And that has been great.
And in fact, if your content doesn't fall within the bounds of those, you know, types of content we talked about earlier, you should keep using regular HLS and it's going to work great for you.
But that simplicity comes at a cost. When you're watching sports, for instance, the manifestation of that cost is often that you hear about the goal through your apartment wall before you see it on your Apple TV.
So why is that? Well, to understand that, let's take a look at what has to happen with regular HLS in order to get a particular frame from your production backend to user at home.
We start with the frame. And the first thing we need to do is encode it and put it into a segment. Now, we recommend 6-second segments. But that does mean that because we're encoding in real time, its six seconds before you even have anything that you can put on your CDN.
After we've got that segment, the client has to discover that it exists. HLS today uses the polling mechanism, which means that every now and then the client checks in with the server for latest copy of the playlist to see if there's anything new.
Now in the best case, the client might say, check in right after the server has put the latest segment into the playlist. That's great, but often we don't fall into that best case. And in fact, in some cases, it can be almost another six seconds before the client even finds out that there's a new segment there.
After it does, and gets the new playlist back, it then has to turn around and make another request to actually get the segment itself. And remember that each of these requests takes a round trip time on the network. And on some networks, particularly cellular, this can be in the hundreds of milliseconds. It's not insignificant.
So anyway, after it does all that, then the segment can start flowing to the client.
Then once it gets enough, it can present that frame of video. Now, in this example, we're already up in the 12-second region. But if you're delivering your content over a CDN, and almost all of us do, then it can get even further away from live.
And the reason for that is because of the way that regular HLS interacts with CDNs. And let's take a look at that.
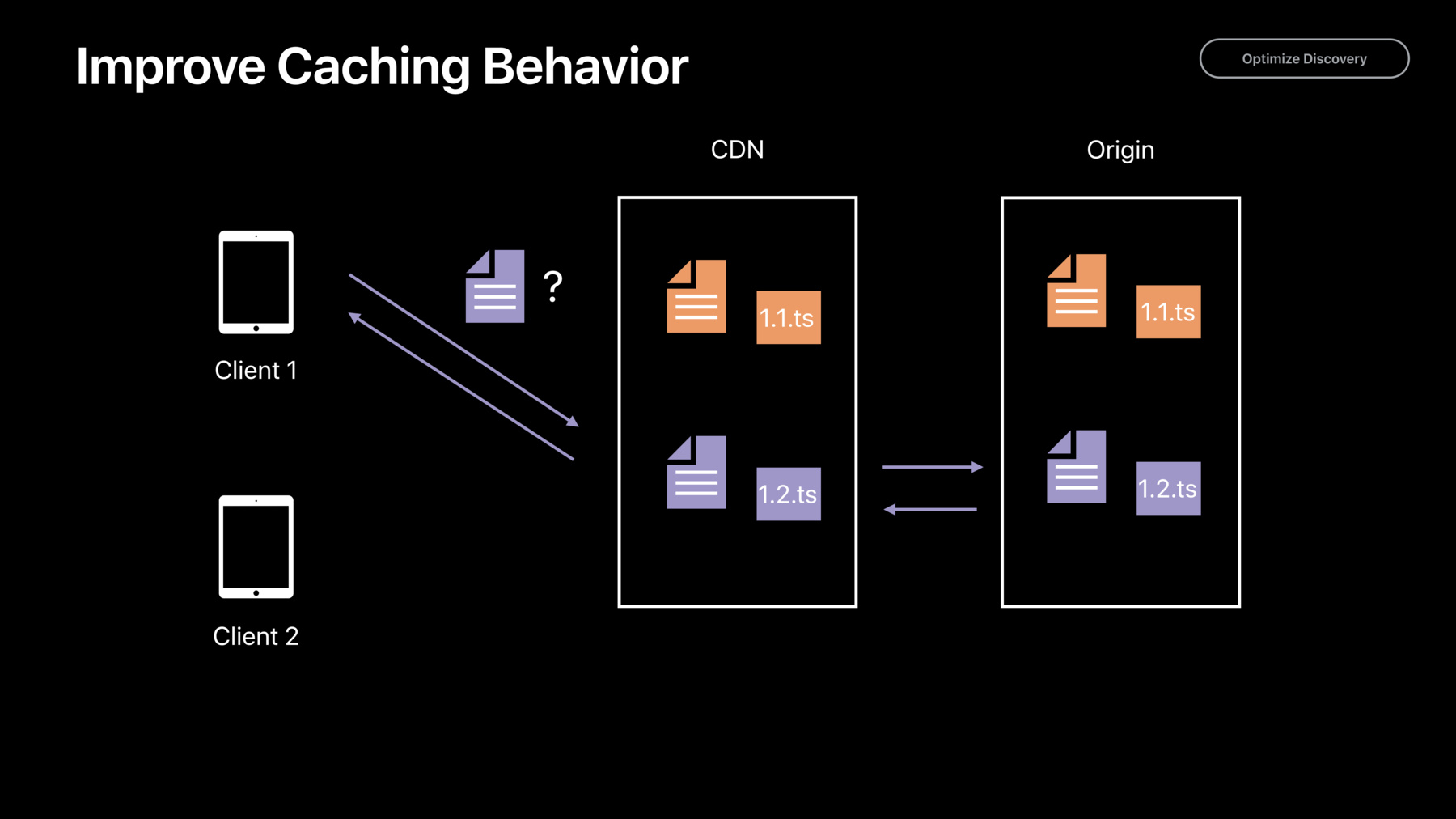
So imagine that you've got your HLS Stream. You're authoring it to your origin on the right. In a particular time, it's placed a playlist up there. It has three segments in it. Now, the first client that checks in wants to find the latest greatest media.
If the CDN edge server that it's talking to hasn't cached any of that stuff yet, he's actually in good shape because he's going to ask for a playlist. The CDN is going to get it from the origin, get the latest versions, sent it right to the client. Client 1 is in good shape. The problem comes about a second or two later when on the origin, we get a new segment in town and the playlist is updated with now containing segments 1 through 4.
What happens after that? When client 2 comes in and wants to find out again, "OK, what's the latest content?" Well, the playlist he's going to get back from that edge is the cached playlist that has only segments 1 through 3. He can't even discover segment 4 because the CDN has served him a cached version of that playlist.
Now, why does the CDN do that? Why it can just serve at the most recent version? Well, the problem is that the CDN has no way of learning that that playlist has been updated on the origin.
And if it were to go in and check with the origin, every time, some random client came in and said, "Hey, what's the latest playlist?" It would melt down the origin.
So CDNs have to cache for a period of time. It's called the time to live.
And the longer that time to live is, the longer client is checking in. We'll see that outdated version of the playlist and that stretches our delay from live by that much more.
So, all these problems can be fixed.
But in deciding how we want to approach that fix, there are a few more factors that we need to consider.
The first is that HTTP is still the best way to deliver the same media to hundreds of thousands people over the internet at the same time. So we should stick with HTTP. But doing that means that we are stuck with the HTTP delivery model. And that is of distributing discrete segments, discrete chunks of resources to clients. And if it's going to take us six seconds to produce that chunk, then we've already missed our deadlines. If we're going to hit that deadline of only a second away from live, then the things we're distributing over HTTP have to shrink to become in some cases much shorter.
The next thing we have to sort of grapple with is that now and for the foreseeable future CDNs are essential to helping us scale to global sized audiences.
But CDNs, at the end of the day, are essentially HTTP proxy caches and they're going to do what caches do. And we have to work with that not against it. The final thing is that when we're playing so close to the live edge, we can only buffer a tiny little amount ahead because that's all we've got.
And so, if we have to do something like switch to a different bit rate, then we've only got like we don't have 10 seconds to do that before we stall. We might only have less than a second. And so, we have to make sure that the mechanics of switching are as efficient as they can be because we have this very short runway.
So, we looked at the entire HLS delivery model, soup to nuts. And we identified five big changes that we needed to make to hit this target of one to two seconds of delay from live.
The first thing we're going to talk about is that we need a way to get that media on to the server shorter than that six seconds.
And we call that reducing publishing latency. So the way we're going to do it, is we're going to allow the server to publish small parts of the main segment before the main segment itself is ready. So we can deliver those smaller parts early.
The second thing we're doing is we're optimizing how clients discover segments, so that they can do it more quickly. And the way we're doing that is we're changing how the client updates its playlist.
We're allowing it to ask for a particular playlist update in advance before it's actually ready on the server. The server will then hold on to that request keeping an eye on the playlist until it updates with that next segment. At that point, you will immediately send the playlist back to the client.
The client will find out about it in less than round trip time.
And in this model, each individual playlist update actually has a different URL.
And this provides a second advantage, which is that it makes caching of these playlist updates much more efficient because with a different URL for every update, every update looks like a separate cache entity.
So what happens now is when client 1 wants a particular update. It'll ask for it. The CDN says, "I've never heard of that." I'm going to go right over the origin, the origin is going to say, "Well, that's because I haven't built it yet." So now, it chugs away. Once it has it update, it hands it to the CDN which hands it right to the client.
Next client comes in, he says, "I want the same update." The CDN identifies that positively using the URL and says, "Here you go." Every subsequent client who asked for that update will get it served immediately out of the CDN cache. But the next time, the first client or any other client wants the update after that, the URL that sends the CDN is a different one. And so, this the CDN immediately knows he doesn't have it cache. He doesn't hand out something stale. Instead, he goes right back to the origin. The origin says, "Well, I haven't built that yet." And then, once it is built, it hands it back to the CDN and is sent over to client.
So, these new playlist update requests are inherently cache busting. And that makes caching work better overall on the CDN.
Now, the third thing we're doing is we're eliminating that extra round trip. After you discover a segment to go off and actually get the segment itself.
And the way we're doing that is to use Push.
So, when the client asks for the next playlist update, it's going to tell the server. And by the way, when you get that playlist update that has the next segment that I don't know about then I want you to-- when you return me that playlist, I want you to Push that segment to me right away. And that way, I don't have to turn around and make a second round trip.
The fourth thing we're doing is we are addressing the cost of transferring playlists, over and over again. And the basic approach we're taking is using Delta updates. So the way that works is the first time a client asks for a particular media playlist, it gets the whole thing back.
After that though, it has the vast majority of the playlist. It's only really interested in knowing about the part of the end that's changed. And so, after that, the next time and it asked one it says, "I want a playlist update that's a Delta update." And the thing that comes back is a much smaller chunk of data that only contains the stuff that has changed most recently at the live digital playlist. And these updates will often fit into a single packet, a single empty unit of data. So they're much, much more efficient for every subsequent update. Now, the fifth change is that since we now know that these playlist updates are pretty up to date, we can have them carry some information with them that helps us switch to other bit rate tiers faster.
So in other words, imagine we have to bit rates on our CDN here, and the clients playing the first one.
When it asks for an update and it receives that most recent version of the one megabit playlist, it can carry other information such that if it decides it needs to switch the two megabit one, it can go directly to the most recent version of the two megabit playlist. And this may make switching bit rates more efficient.
So five changes, we're reducing the publishing latency, putting our media on the CDN, optimizing segment discovery, we're eliminating round trips, we're reducing the overhead of transferring playlist, and we're making it possible switch to yours quickly.
Now, let's take a look into the details of all of those. So, to make all of the stuff work, the client needs a way to tell the server that it wants to make use of these new features like playlists Delta updates or blocking playlist reload. And the way it does that is using something we call the HLS Origin API.
The way that works is that the services themselves are advertised by the server using a new tag, the server control tag.
When the client discovers that they're available, it makes use of them by sending the server a small number of directives that are carried as query parameters in the get request for the playlist.
So it looks something like this.
Now, this is the first time that we've specified query parameters as part of the HLS.
And so, we are going forward reserving all query parameters that start with underscore HLS on playlist URLs for the use of the protocol.
Another thing we're doing is we're making sure that for all the clients that those query parameters appear in a deterministic order in the URL so that the CDNs don't end up caching multiple copies of what are effectively the same request.
So, now let's go through each of those five changes a little bit more detail.
The first is to address this notion-- is to address the reduction of publishing latency. And so, we're introducing a notion of a partial segment to HLS. And we call these things Parts for short.
So, a partial segment is essentially just a subset of the regular segment containing a subset of the media within that parent segment.
And CMAF already has a name for this kind of thing. They call them a CMAF chunk for FMP4 content. And so, you can use CMAF chunks as your partial segments in HLS. You can also use little bits of transport stream or any other of the defined HLS segment formats for your partial segments.
The main thing about them is that they're short. They can be less than a full GOP for instance. So that means you can have half second partial segments and still keep your two-second GOPs.
Every time you create a new partial segment, it is added to the playlist. And that means that if you've got half second partial segments for example, then you can publish content to your CDN about half a second after it hits your production backend. That's how far it reduces your publishing latency.
Partial segments are added to the playlist in parallel to the regular segments stream but they don't stay there for very long. And that's because partial segments are primarily useful when you're playing at the live edge. They allow clients to discover media just as soon as it arrives. And they fine-grained addressability of those partial segments allows clients who are joining those streams to join them closer to live and perhaps the largest segment boundary.
But after the partial segments drift further away from the live edge and their parent segments are well established in the playlist, the clients are actually better off loading the parent segments than the partial segments. And so the partial segments are removed from the playlist. And this helps keep our playlist compact.
So, the way it works is, as you produce your segment, you're producing partial segments in parallel. After a while, as those partial segments become further or far enough away from the live edge, they are removed and they're replaced by new partial segments at the live edge. Let's take a look at how that looks in an actual HLS playlist. So, I got a couple things up here. The first thing I want you to notice is that just like regular playlists have a target duration which says this is how long our segment can be.
Parts have the same kind of thing it's called a part target duration. And so this is saying to you that the Parts in this playlist, the partial segments have a maximum duration of five, of half second. The next thing though is we have a regular segment here. It's a 6-second segment43.
Half a second after we put segment43 into the playlist, we can put-- we can add the first part of segment44. And we do this using a new tag called the part tag. And so, what you can see is that each part tag has URI. So the segment get-- the Partial Segment has its own URI segment44.1 is half a second long. And it's independent, which means it has own URI.
Half a second after that, we can add the next partial segment of segment44 to the playlist and so on and so forth. This is a 6-second playlist. So there's going to be 12 parts. Once we get to the final part of segment44, we actually have the entire parents segment as well. And so, we can publish the final part of segment44 and the parents segment at the same time. And so, then half a second after that sort of the cycle repeats and we get segment45. And then, after a while, those partial segments in the middle are far enough away from the leading edge of the playlist that they can be removed. And now, we just have segment43, segment44 and then the parts of segment45 and beyond.
So that's how we use partial segments to lower your publishing latency.
Now, let's look at optimizing how we discover segments. And we do that using what we call blocking playlist reload. The way this works is the server advertises it has the ability to handle blocking playlist reload by putting a can block reload attribute into the server control tag.
When the client sees this, it knows that it can ask for its next playlist update in advance of when it's actually ready. So we advertise the request cost that way. At that point, the server receives a request, realizes that it doesn't have a playlist update that's been requested yet and so it holds on to it until it does. So, how does the client specify to the server which updated wants, that it wants a particular playlist update with a particular segment in it.
Well, it uses a feature of HLS called the media sequence number. Now, every segment in an HLS playlist has a unique sequence number.
The sequence number of the first segment of the playlist is the value of that media sequence tag. You see at the top there. So it's 1800 in this case.
The media sequence number of the next segment is just that plus one.
And that's true even if the next segment is separated from the others by a discontinuity tag or a key rotation or anything else. Sequence numbers just keep counting forward.
And that means that if we have this playlist. Then, we know the next time it's updated, what the sequence number of that next segments going to be.
So, to get the next update that contains the segment, you know, the next segment of interest, we can tell the server, "Hey, please, go get me a playlist update and I want the one that contains media sequence number 1803." So this is how that looks. So we've got a get request here for a playlist. You can see it's requesting live on m3U8. And we have a query parameter underscore HLS underscore msn=1803. That's how the client tells the server, I want this particular playlist update, the one that contains this media sequence number. After it receives it, as soon as it receives it, it'll immediately send the next update request for 1804.
And those to a CDN look like completely different URLs even though only one query parameter is different by one value to a CDN, it's a completely different cache entity. And so, that gives us our cache busting. Now, this works with partial segments as well. And this is how it looks in this case. So we have a second example and the second example says that, "I want the playlist update that contains the first part of the media sequence number 1803. Now, there's one more thing going on here and that's this Push query parameter. What's that about? Well, remember that another thing we want to do is eliminate these extra round trip times for segments. And so to do that, we're making use of Push.
And to do that, we're using HTTP/2.
Now, some of you may not be intimately familiar with HTTP/2. So let me give you a quick refresher.
HTTP/2 is a successor to our old buddy HTTP/1. And it was standardized by the IATF about four years ago.
Since then, it has been widely adopted by web servers, clients and CDNs. It is required for Low-Latency HLS because it gives us several features that allow us to crank up the efficiency of the protocol exchange. The most notable is Push. So how does Push work? Well, HTTP/2 works the same way as HTTP/1 in the sense that the client when it wants a resource will send a get request to the server. What's new with HTTP/2 is that when the server sees that request, it can say to itself, "Oh, I see you want this resource. I bet you want this other resource as well." And so, when it sends you the resource you've asked for, at the same time it can unilaterally start sending you that secondary resource that you don't know you want yet. In that way, if it guesses right then you don't have to turn around and make a second request for it because it's already on its way to you.
So, we're making use of this in the latency HLS with Segment Push.
So when a client asks for a particular playlist update, the one that contains the next segment x, it can tell the server, "Oh, and by the way, when you give me that playlist update, start pushing me segment x as well." And so that allows us to eliminate that extra round trip of asking for the segment. So let's take a look at all three of these first optimizations and see how they influence the flow in comparison to regular HLS. So, let's put that over there. And let's take a look at what the new flow looks like with a low-latency client talking to a low-latency server. First of all, the client will make a playlist request in advance. So we'll have it lined up there. Server holds on to it. The server in the meantime is producing that first partial segment.
And let's say in this example that the partial segment is one second long. So after a second of doing its encoding thing, at that point, it can add that partial segment to the playlist and unblock that playlist request, at the same time, pushing that first partial second to the client.
The client can then display that as soon as it gets enough of it. And at the same time, line up the next playlist request on the server so it can find out about the next segment that appears as quickly as possible.
Even with partial segments as long as the second, you can see how this dramatically reduces the amount of time it takes for a given frame of media to travel from the server all the way to the client. Now, the last couple of changes are essentially optimizations to this basic flow.
The first one is about reducing this overhead of transferring the playlist over and over again. Now, why is that important? Well, if this playlist you're transferring has like three hours or even five hours of worth of segments in it and you're transferring it like three to four times a second that can become significant, even with gzip.
And so instead, we're adding Delta playlist updates.
And so, the way that works is that, again, the server announces the client that it can has the ability to provide Delta updates. And it does that with a CAN-SKIP-UNTIL attribute that tells the client if you ask for a Delta update, it's going to skip all the segments until a certain number of seconds away from the live edge.
If the client sees that and it knows the last time it updated the playlist and so it figures, it can make do with a Delta update and not miss any information. Then it can make an explicit request the next time it updates a playlist for a Delta update.
And that update carries just the last few segments in the playlist, the ones that are closest to the live edge.
And it skips the earlier part of the playlist that the client already has.
So here's an example.
In this case, you can see that the client is asking for a Delta update by specifying the underscore HLS underscore skip=YES query parameter, when it makes its play playlist get request. In the playlist that comes back, you'll see that there's a CAN-SKIP-UNTIL, which tells the client that when it asks for a Delta update that the Delta update will skip everything until the last 36 seconds before the live edge.
And then the last new tag here is this skip tag. And the way you can think of the skip tag is it is a stand in for 1700 xm segment, xm segment tags that would have been there in a full playlist update.
So that's Delta updates and allows us to really minimize the number or the amount of network traffic it takes to constantly refresh the playlist without losing any of the generality and power that HLS Playlist give you. So now, let's look at the last change and this is the one that helps us switch bit rate tiers more rapidly.
They're called Rendition Reports. And the idea is that, when your client loads the most up to date version of a particular playlist for a particular bit rate that update can carry an up to date kind of a peek into other renditions that the client might decide or interesting to switch to in the next second or two. Specifically, the Rendition Reports carry the last media sequence number in that pure playlist in its last partial segment number. And that gives the client what it needs to compose the URL to get that latest playlist. So it looks like this.
In this example, we have the client asking for an update of the one-megabit playlist. And when it's doing that, it's using the HLS report query parameter to ask for a peek into the two-megabit playlist that's on the same server. When it gets its playlist back, the playlist will contain a rendition report tag. And that has a variety of information about that other rendition. So, if we put all these changes together, the question is, how well do they work. Do you guys want to see a demo? Yeah. Let's do it. You know, when we were putting the session together, we were like, "Yeah, we could do a live demo or we could do a Live Stream from Cupertino." But wouldn't it be more demonstrative to do a live demo from somewhere a little bit further away? Maybe somewhere 7,000 miles away, 12,000 kilometers somewhere like Sydney, Australia? But wait, do we know anyone in Sydney? Matt. We know Matt.
Let's call Matt.
OK. Let's see. Geez, I hope Matt is awake.
Good day, Roger.
Hey, Matt. How are you? I'm well, thank you. Great. Hey, say, I am here at WWDC and I want to show these folks Low-Latency HLS. Do you still have that Stream running? I sure do. Oh, fantastic.
OK. Let's tune in. See what we got here. I'm got my Apple TV. OK. There we go.
OK. Hey, fantastic I'm at Apple TV.
All right. So let's bring up our app. We got our Sydney Stream here. And let's tune in and see what we got.
Sydney is not happening.
Let's see if we try that again.
OK. Let me try the Cupertino Stream just to see if there's someone-- oh, there's Simon. Simon is in Cupertino. So that's-- we got Simon going.
All right. Let's try this one more time. Are we-- Oops, come on, how do I manage this thing? Matt, you're still there right-- Whoa, there you are. Yeah. I'm still here. Hello. OK, great.
But, hey, you know, what is that the Sydney GPO behind you? It sure is. Oh man, come on.
We're not sorry-- I got to try this again.
My Stream is not behaving the way I want my Stream to be today. Yeah. Simon is still there.
Oh man. And there's-- OK, there's-- Yeah, there is Matt. And am I hitting play, pause? Well, you know what, maybe we're going to have to end up calling Simon instead, which is kind of a bummer because I really wanted to show you guys the Stream. Let's see.
Hold our breath. Are we good? Did you guys have to restart Stream? The network went away for a bit. The network went away.
That's great.
All right. We're having-- Let me just see if maybe we're not plugged in right.
These live demos just killing me.
Double tap this and this is going to try to get rid of this guy. Yeah, I don't know if this going to help me but let's give a shot.
Oh, man. All right. I think we're going to try this one more time and then we are going to back up. All right.
Sorry, Matt. We're having trouble with the Stream over here. So let me-- Thanks for showing up and we're able to see you for a little bit but I'm going to have to go to Cupertino. All right. No problem. All right. Well, that's really a bummer but let's call Simon anyway. This is why you have backups, I guess.
Hey, Simon, are you there? Yeah, I'm here Roger. How are you? Good. Simon is also Australian. I realized that's not-- that's kind of cool comfort but there he is. You got Australians everywhere.
So Simon, I wanted to show the folks here a Low-Latency HLS Stream. Oh you bet. So why don't we do this. I'll have you raise your hand and people hear you said-- if you said when you do it, they'll hear you over the audio. And then they'll see you on the Stream. Now, they'll give you-- a give them a sense of what the video latency is. So, I want you to raise your hand. OK. You bet. OK. Raise your hand. Hey, everybody.
I'm raising my hand. OK. Good. Keep that hand up. And-- oh you put it down. OK. Now, give me three fingers.
Three fingers.
There we are. So that's a-- they are about, you know, HLS Stream less than two seconds latency. Thank you very much for helping us out today, Simon. You bet. I hope you all enjoy the rest of WWDC. Thank you. Alright. So that is Low-Latency HLS. So at this point, some of you are probably wondering, how can I give me some of that HLS Low-Latency stuff? And so, first of all, a lot of your application developers and so let's talk about that first.
The good news is by default, you don't have to do anything if you're using an AV Player to play your Streams and you stand up Low-Latency Stream, you'll get it by default.
We do have a couple of new API's however. One that tells you how far you're currently set from the live edge and the other which is a recommendation based on things like round trip time we're observing. And so, you can use those together to configure. For instance, you see here a little bit too close in your risk of stalling, you can back it off a little bit. Maybe we should have done that here. The second is a way to allow you to maintain the play head position relative to the live edge. And the reason this is interesting is because that today if you're playing the Live Stream and you go through a tunnel or whatever and you buffer for 10 seconds, when you resume, you resume at the point you stopped, which means you don't miss anything. But every time you're buffering a little bit further behind, and so if you set automatically preserves time offset from live to yes, then every time after we will buffer we will not automatically jump ahead to that same place from live. And so, that keeps you at live. The next thing to think about is configuring your CDN. We really wanted to avoid placing exotic video specific requirements on our CDNs because we want them to be able to focus on being great CDNs. And so we kept things straightforward.
You need to use industry standard HTTP/2 to deliver your HLS segments and playlists. That includes supporting Push and the standard priority controls.
You should be putting a complete ladder of tiers on each server. You can still have multiple redundant servers, but each one should have a complete ladder so we can minimize connection setup time.
And you have to set up your CDN so the aggregates duplicate requests. If Fred asked for a particular playlist and it goes off to the origin to get it, and then Bob asks for the same thing, rather than sending the same request through the CDN, you should park it next to Fred's and wait for that first response to come back and then deliver them together. Different CDNs call that different things, Apache Traffic Server calls it Reader while writer. Others might call it early published or something like that. The main thing is to find that and set it up. Now, the main work here is implementing your origin, changing your packagers who admit partial segments and implementing the origin API. To help you with that, we've published a spec for Low-Latency HLS. It's available on the website. There's a link to it through the session page on the app.
It's currently structured as the separate draft. We plan to roll the rules into the course back later this year. It includes something new, which is a Server Configuration Profile. And that has a set of attributes of the server delivery chain that required to engage Low-Latency mode in the client. The client will check these if it doesn't see all the met, it'll fall back to regular latency.
Also, we're giving you a reference implementation for producing and Streaming Low-Latency HLS Streams.
It's called a Low-Latency HLS Beta Tools package.
And it has tools that will generate a playlist either a programmatic bit bop or from the camera and package it into a Low-Latency Stream.
It includes a front end to Apache that implements the origin API, including Blocking Playlist Reload, Delta Updates, Rendition Reports. And you can use that either to experiment with Low-Latency with your app and also to compare it against your backend implementation when you build that.
So that's what you need as developers to get up and running on this thing. Let's talk about the roadmap to users. We recognize that Low-Latency HLS is a major change. And so, we are allowing you to spend a bit of time getting to know it and to we-- and to stand up your implementations against our clients at scale.
So the short answer for what that means is you need an app entitlement for Low-Latency mode. This allows you to build your app, test your Streams and even deploy them and up to 10,000 beta users via TestFlight. And then once you're confident that things are working and the beta period ends, you'll be able to submit your apps to the store. So, in summary, go take a look at the spec. Try it out in the beta and start building your back ends to support Low-Latency Live Streams. To help you with that, today or this week rather, we have a couple of HLS labs. I'll be there along with a number of other folks on my team and we're happy to answer all your questions about Low-Latency HLS and any other HLS questions. The first one is on Thursday from 4 to 6. The second is on Friday from 11 to 1, I think. And so with that, thank you very much for attending. And I hope everyone has a great show.
[ Applause ]
-