-
Designing Great ML Experiences
Machine learning enables new experiences that understand what we say, suggest things that we may love, and allow us to express ourselves in new, rich ways. Machine learning can make existing experiences better by automating mundane tasks and improving the accuracy and speed of interactions. Learn how to incorporate ML experiences into your apps, and gain practical approaches to designing user interfaces that feel effortlessly helpful.
Resources
Related Videos
WWDC21
WWDC19
-
Search this video…
Hi, everyone.
I'm so excited that you're able to join us today. I'm Kayur and I'm here with some amazing designers, Rubii and Cas. And we're so excited to talk to you today about design and machine learning.
You see, at Apple, we've been thinking about design and machine learning for some time now. And when we think about and we talk about machine learning, we talk about all the amazing technological advances in speech recognition and computer vision. We talk about deep neural nets. We talk about custom processing for on-device machine learning. We talk about all these things because we care about products and we know that many of the products that we build today and many of the products and experiences that we want to build in the future would not be possible without machine learning.
Let's take a look at some of the products. AirPods. AirPods allow you to summon Siri to control your device with your voice. You can easily change your music or answer a call all when your hands are busy and when you can't really look at the screen. This AirPods experience would not be possible without machine learning and it would not be possible without Siri.
Machine learning allows us to create Face ID which provides fast secure authentication for your iOS devices. And we use machine learning in ways that you may not expect, subtle ways that improve your experience with your devices.
We use machine learning to invisibly improve your typing experience. We increase or decrease the target tap area for keyboard buttons based on the word you're most likely to type.
Machine learning applications are diverse. They're not just about voice assistance or recommending content or self-driving cars, machine learning applications are as diverse as any application of software engineering. They can make existing products better or enable new products that enrich the human experience.
And inside Apple, we've been talking about and thinking about what makes a great machine learning product for some time now.
And to go into this in more detail, let's dive into a single experience, Photos.
Photos uses machine learning in a variety of ways. Machine learning helps people create albums, edit photos and search for specific memories. Speaking of memories, recently I was looking for this memory. This is Angie. She's a friend of the family and this picture was taken from a hike a few years ago. I felt nostalgic and wanted to share the picture with some friends who were already there. Until very recently, finding a specific picture was painful. I'd have to sift through thousands of pictures, try and remember where I was or when I took the picture. I would've given up. Finding a picture used to be a barrier to me engaging with my memories and sharing them with my family.
In iOS X, Apple introduced a new search experience that could like inside a picture and detect, among other things, dogs. And over the years, we've been making this experience better.
Here's what the experience looks like now. I tap on the Search box. I type in dog. And I get a list of pictures with dogs. I can then select the picture I was looking for and share it. Easy peasy.
Searching for pictures based on what's in a picture changes how we engage with our memories. It's something we take for granted. In fact, it's such a great experience it's hard to remember a time before we had this capability. It's well designed.
And there's a lot of interface work that goes into making this experience. Photos suggest categories you can search for, it auto-completes searches and it connects search results to Moments but designing this experience is more than just designing a grid view in the Search field. If we just looked at the interface, we'd miss the most important parts of the search experience, the results being outputted into categories that people can search for.
These aspects of the experience should be designed. We get to decide which categories are included and we decide the level of quality we want for each category. We've realized that to build a good machine learning experience, we have to design more than just the interface. What do we mean? Well, when most people think about design, they think about the interface, how the product looks and feels, the flow of the experience. With machine learning, we have to design how the product works.
Now we know that many of you in the design and developer community have some machine learning experience. You could create a search experience from scratch but to get everyone on the same page, let's look at how machine learning for photo search works.
Deep within the logic of Photos is a function that takes a picture and detects if that picture contains any of the categories it can recognize. In our case, it recognizes that this picture of Angie has a dog in it. In traditional programming, we would have to create the function by writing code to tell the computer what to do.
Our code would have to work for a variety of different breeds, different scenarios, different photo resolutions because their customers are diverse and so are their dogs.
And we wouldn't want a search for dogs to be littered with pictures of other animals. Our code would have to differentiate between dogs and similar animals, like this hyena which looks like a dog but you should not have as a pet.
Writing code that generalizes the countless variations of dogs in photos would be impossible. And dogs are just one of thousands of categories that Photos can recognize.
There're experiences we want to create where we can't just tell the computer what to do.
And for many of these experiences, we can use machine learning to teach a computer what to do.
We teach by providing examples. If we wanted to distinguish pictures of dogs from pictures that do not contain dogs, we have to provide pictures with dogs and pictures without dogs. Machine learning learns a function that we can later use in our app. This function can take this picture of Angie and understand that it's a picture of a dog.
We call this function a model and a model is what makes the Photos Search experience work.
This model can generalize two pictures that it's never seen before. It can recognize different dog species and differentiate dogs from other animals and objects.
Models are central to the machine learning experience. Every product or experience that depends on machine learning depends on a model.
Siri has a model that converts your voice to text. And the keyboard has a model that infers the key you meant to type based on the letters you've already typed and your typing history.
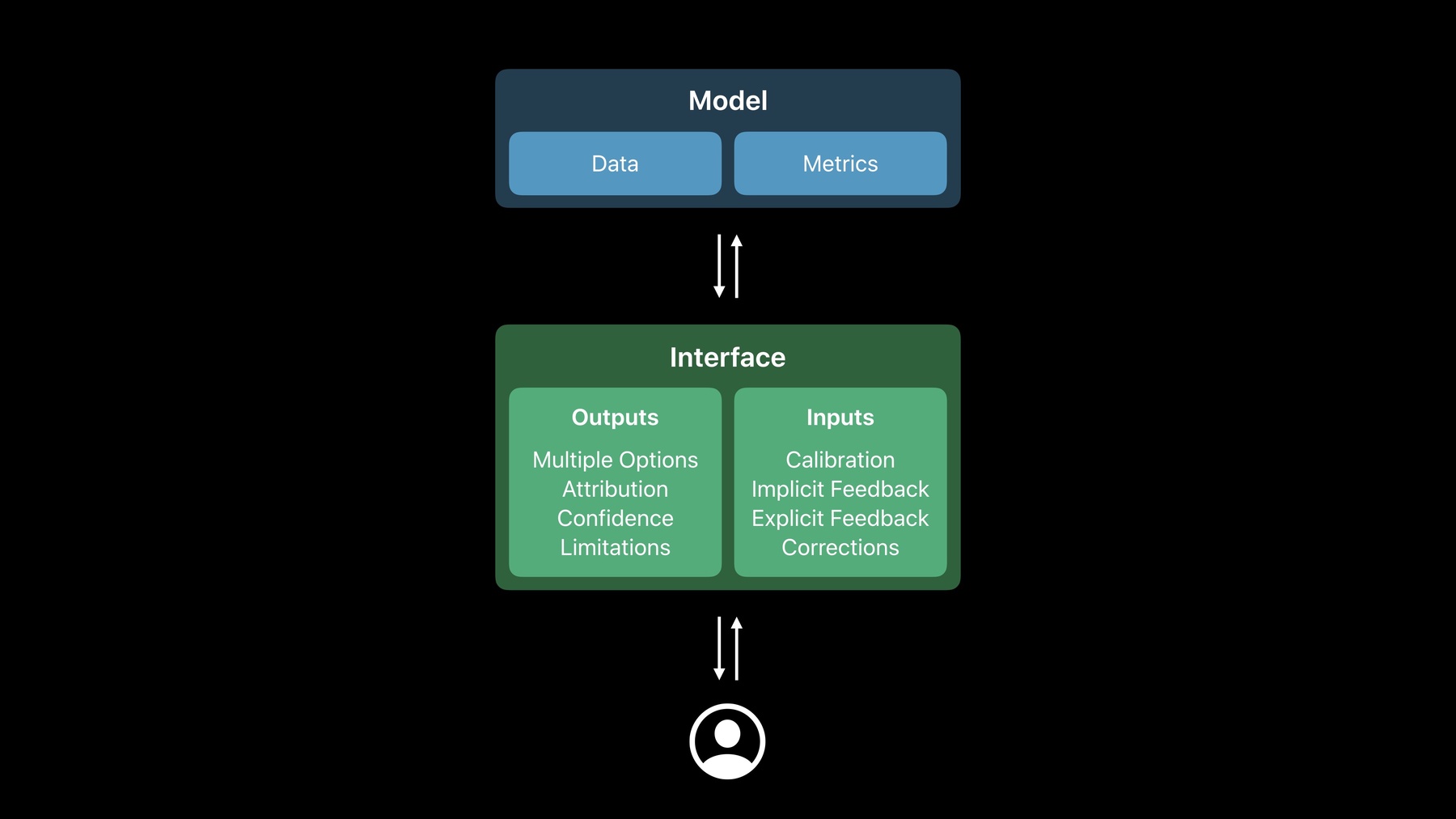
To design a great machine learning experience, we have to design both how it works and how it looks and feels. We have to design both the model and the interface. In this talk, we'll cover both.
Creating a model can be complicated. You have to make a lot of decisions about algorithms and parameters and frameworks. And all of these decisions affect what the model does and, therefore, the experience.
Machine learning decisions are all design decisions but not all of them are effective places for design input. We choose a few places where we think design can have the most impact.
We talk about the need to design what we use to teach the computer. This is the data.
And we also talk about how we design what we evaluate and these are the metrics. Along with the model, we do need to design the interface.
We have to design what the model outputs and how those model's outputs are presented to people. We also have to design how people interact with the model and, if appropriate, provide input to improve the model. Rubii and Cas will talk about that later.
So let's start. Let's talk about the data.
To recognize dogs in pictures, we used machine learning to create a model using examples.
Those examples are called data. And to build a good search experience, you need a lot of diverse data. You need photos of the categories that you want people to be able to search for. You need to provide plenty of pictures of dogs and of other animals to ensure the search experience doesn't show random animals when you're searching for dogs. And a good search experience needs to support thousands of categories that cover the objects and events people want to search for. And for each of those categories, you'll need data. If you want to support a new category, you'll need data. If you want to improve an existing category, you will need data. Choosing data is key to designing the experience.
Data determines the behavior of a model. It's easily the most important decision you'll make when creating your model. And if you don't have data that captures an important scenario, it's unlikely that your model's going to work well in that scenario. And since data determines the behavior of the model, and since the behavior of the model determines the experience, data needs to be designed to reflect good values in the best interest of your customers.
To understand this better, let's look at an example.
Let's look at Portrait mode.
Portrait mode uses machine learning to detect faces and segment your body from the background.
Historically, face recognition hasn't worked well for people of color. At Apple, we want to make sure our experiences are inclusive. So our design and engineering teams gather data from across different races, different cultures, and different scenarios. We built a dataset that matched the experience we wanted to create. We collected data intentionally. When collecting data, it's important to ask questions. Who is collecting the data? What data are they collecting? And how are they doing it? Data bias can seep into your dataset in a variety of ways. And data bias extends beyond fairness.
You should strive to be fair and inclusive. Those are good values. But you should also see how data collection might skew away from other design intents. If you're creating a fun or enriching experience, you should sample data for fun, enriching experiences. If your product is going to be used outdoors, you should sample from scenarios that are outdoors.
It's tempting to disconnect from this decision and make decisions about data collection that just sample the data from your existing customers and get a uniform sample of the world from other mechanisms but you can't just reflect the world. Reflecting the world can reinforce systemic biases.
You shouldn't optimize for the customers you have. You should optimize for the customers you want.
You shouldn't reflect the world as it is. You should reflect a better world, that world that you want it to be.
Collecting data is a way to design experiences and great experiences often change the world. They don't just reflect what already exists.
So how do we put this into practice? We'll start by collecting data intentionally. Understand the experience you're trying to create and think about what you'll need to make that experience work. If specific scenarios are important, spend more time and ensure you collect data for those scenarios.
Spending time up front collecting the right data can save time and effort and money later. Make sure you test for biases. Analyze your dataset. Catalogue your assumptions about who will use your product and how it will be used. Think of ways your data might be biased towards or against certain populations or certain experiences. Update data as products change.
Product specifications change the more you learn about your customers or the market or what you want to actually create.
You need to change your data to match. You may not need to collect more data. You may get rid of concepts that are not important but you must routinely align your data with your product goals. And beware of standard datasets. Academic or industry benchmark datasets might be a great way to start to get some knowledge about how machine learning works. It might be a great way to ramp up your product development process. But they're not designed to represent real experiences, especially your experience. Before you start using an off-the-shelf dataset, think about what the data covers and doesn't cover. Spend time augmenting the data to match your needs.
Spending time thinking about cataloguing and critically collecting data can help you align what you want your product to be and what machine learning can provide. So, we just talked about data, which is what you use to teach a model.
Next, let's talk about how you evaluate your model. This is done through metrics. You evaluate your model by testing it. In the Photo Search example, you'd give it pictures of animals and your model would predict what's in the pictures. And once it's done, you can compare how many times it was correct and how many times it was incorrect. Here, we see that the model gave the correct prediction 75% of the time. This is a metric and a metric like this will define how successful your model is and, therefore, whether it's ready to use or whether you have to go back to the drawing board and improve it. Models can be evaluated in many ways. You could look at how fast the model works or how many categories it can support. You can balance all of these together and find the right set of metrics for your problem.
Designing metrics define how the model will work and, therefore, how the experience will work but ultimately you get to decide. Metrics encode what you think a good experience is. They define what you care about and what you can ignore.
If part of the experience is not measured, it may be sacrificed for something that is.
And as a consequence, your metrics reflect your values. Let's look at an example.
Let's look at Face ID.
Face ID uses machine learning to detect your face to unlock your device.
And behind Face ID are a number of design intents. The most important is Face ID needs to be secure. Our customers trust us with some of their most private data. There are many metrics that we use to track different aspects of security. One key metric was the chance that a random person could find your phone, pick it up and unlock it.
We tracked this metric and worked hard to reduce this chance. At launch, we knew that there was a one-in-a-million chance that a random person could unlock your phone using Face ID. And since Face ID was a new experience, we needed to communicate this to our customers. That way they understood that we cared about their data and they could actually trust Face ID. But one in a million doesn't tell the whole story.
Each failure is a person, a scenario, an experience that we have to think about and address. Say you're me. I'm your average run-of-the-mill Apple employee and recently I had a run-in with the new MacBook Pro. Due to a small mishap, I accidentally opened up a portal to another timeline. Now I have to routinely fight off my mirror universe nemesis. I obviously don't want him accessing secret Apple data, so I have to rely on a pass code. And people like me with similar looking family members or evil twins need to take the same precautions.
As Apple, we also talked about this limitation. We dedicated time in a keynote because it's important that our customers understand and take steps to secure their data.
It's important for you to understand and communicate limitations to unpack aggregate statistics. Not all mistakes are equal.
Mistakes in machine learning are inevitable. Few models work 100% of the time. When you start, you may not understand all the limitations. That's OK. It's an iterative process. But over time, you need to build a better understanding of what is and is not possible.
Mistakes don't mean you can't create an experience that people love. If you understand mistakes, you can account for them either by creating new models, improving the product or clearly communicating technical limitations.
And remember that metrics are proxies for what we actually care about.
Metrics provide numbers, a sense of scientific accuracy, and it's easy to get caught up in numbers and improving them but we ultimately care about abstract concepts. These things are hard to measure like good experiences, happy customers and strong brands. Let's look at an example.
To understand metrics as proxies, let's talk about the App Store. The App Store uses machine learning to recommend new apps based on what you've downloaded. And at first approximation, the amount of time a person spends in the app might be a good measure. Right? Afterall, the more time you spend doing something, the more you like it. And if the App Store is purely driven by metrics and models, people would see apps that are very similar to the apps they currently use. I like playing games. So my top recommended apps are all games. And for a while, I might like those recommendations but over time, I'd feel boxed in because I care about more than just games.
People have diverse interests and tastes. The amount of time I spend in an app may not indicate how much I value it. The App Store makes an editorial content with recommendations. This allows people to explore a diverse set of applications and experiences that they may not normally see if they just got their top recommendations.
Editorial content is a way to address limitations of metrics and recommendations.
But as you deploy your products and learn more about customer needs, what you care about evolves. You can evolve your metrics to match. For example, you can bake diversity into your metrics. You can measure when people engage with diverse content and actively create models that balance the quality and diversity of apps that people engage in.
You should ensure that your metrics still track what you care about: a good experience, happy and fulfilled customers and strong brands.
But to do that, you need to question metrics to ensure they're relevant. In your day to day, you can put this into practice. You can try to understand mistakes because not all mistakes are equal. Group failure cases into categories and scenarios. This will help you understand how important each scenario is. Decide if it's best handled by a non-ML approach like improving the design or if you actually need to build a better model. And design for failure scenarios. When storyboarding or sketching out an experience, don't just sketch out what happens if things go well. Sketch out what happens if something goes wrong. This will help you emphasize what your customers might experience. Spend time evaluating the experience.
The metric will give you an objective value for how well your model is working. Remember, the model is not the experience. The actual experience is the experience. So try to measure that experience. Run user studies. Build demos. Talk to your customers. Read forums.
If the experience is bad and the metric says it's good, your metric is probably wrong. If the experience seems the same the metric says it's getting better, your metric is likely wrong. And over time, evolve your metrics. Question and assess the effectiveness of your metrics constantly. The more you rely on something, the more you should question it.
Ultimately, your metrics reflect your values. And if you want to align your metrics with your values, you have to think carefully, critically and continuously about what is and is not measured. We just talked about metrics which is how you understand if the model is good, how you evaluate a model. Next, let's talk about the interface. Designing metrics in data is key to designing how your model behaves.
But we also have to figure out how do we surface the model in the interface. And to do that, I'll hand it over to Rubii and Cas to talk more about outputs/inputs. Thank you so much. As Kayur has shown, there's a lot that goes into creating the underlying machine learning system that powers an experience.
But we also need to design interfaces that allow people to interact with the experience in an intuitive way. The interface can translate results from a model to outputs that people can actually interact with.
The feedback we collect from these interactions are inputs we can use to future improve the experience. We've created a set of patterns in the human interface guidelines to help you design output and inputs.
Cas and I will go in-depth through some of them to help you understand how they apply to the experience you're building. First let's talk about outputs. Outputs can be more than just predictions. They're a design medium that can augment an experience into something that feels more contextual and seamlessly helpful.
There are four types of outputs we'll discuss. Multiple options allow you to present a diverse set of outputs to people. Attributions are explanations that help people understand more about how your app makes decisions.
Confidence is a measurement of certainty for an output. And limitations occurs when there's a mismatch between people's mental model of a feature and what the feature can actually do. Let's start with multiple options. As I had mentioned, multiple options allow people to choose from among the results a feature generates.
What does this actually mean? Well it's often tempting to only reveal the best option that was created by your model. That's often not the best experience. Let me show you an example from the real world.
Last weekend I wanted to take a short trip and I asked my colleagues what's the best way to get between San Francisco and Napa.
Depending on the person and the time of day that I asked, the answers varied. Sometimes they would say take the I-80. Sometimes they would say take the 101. This is because route prediction is a complex task with a lot of different variables that might constantly be changing. There might be traffic or construction or even car accidents.
Given all of that information, in Maps we try to predict the best route possible but sometimes a single option is not enough.
We can't know everything that a particular person may care about.
They may prefer scenic routes or routes without tolls or routes not along highways.
Providing a set of meaningfully different routes can help people navigate the gap between their preferences and what a model can realistically predict. Here, Maps gives us three distinctly different routes: One that goes to the North Bay and two that go to the East Bay.
This can give people a sense of control over how to get to their final destination.
Whenever possible, you should prefer diverse options that encapsulate a meaningful selection of choices.
People might also be using Maps while on the go and some of the options might appear very similar which makes it difficult for people to quickly choose the route.
We can also use attributions to help people differentiate between the options and make a choice faster.
Here, we show you whether a route requires a toll, which highway it goes through and we even highlight each path on the map making it easier to find that perfect scenic waterfront drive.
These small summaries are a great tool to help people differentiate between a broad selection of options at a quick glance and easily make a selection while on the go. Now I know Maps is an obvious example for presenting options because it's reacting to very explicit input. I know where I am, where I want to go and I'm expecting a list of options that can get me there. But multiple options can also be useful for features that are proactively surfacing suggestions or it might be more ambiguous what my current intent and context is.
Let's talk about the watch. When I start the day every morning, I might want to check the weather, see my first appointment and see reminders of what I need to do that day. Siri watch face allows me to customize up to 19 different data sources that I might want to get information from including weather, calendar, and reminders. You can even choose to see information from third-party apps. Now information from 19 different apps is a lot to look at on such a small screen.
That's why Siri chooses to surface a smaller selection of options based on time, location, and what I've previously interacted with. Since my watch knows it's morning time, I'm at home, and in the past I've always selected the option to turn on the lights at the certain time. It'll surface this as a top suggestion every morning. Siri can understand my usage history to help me automate this mundane task without having to scroll through this long list of options when I first wake up. This makes getting up in the morning so much more effortless for someone who's not a morning person, like me.
This is important because every time someone selects an option, they're actually giving you valuable implicit feedback that you can use to make sure the most relevant option is always ranked at the top. If you learn from their selection, you'll be able to surface better suggestions over time.
Now remember when we talked about Maps and how attributions can be used to differentiate routes? Attributions can actually be used for so much more than that. Attributions are explanations that help people understand more about how your app makes decisions. Within the App Store, we use attributions to explain how recommendations are created.
This helps people understand why they might be seeing certain suggestions and how their data is being used.
But let's say the App Store is showing me some recommendations because I downloaded a cooking app. Now I might have downloaded an app to cook but that doesn't necessarily mean I'm into cooking. Neither does it mean that I love that particular app.
Therefore, when using attributions to explain suggestions, you should relate to objective facts rather than subjective taste.
Here, we simply state that these suggestions are because you've downloaded the "New York Times" Cooking app.
We can never have a complete picture of someone's taste and preferences because they might evolve on a daily basis. People might also share an account with their friends and family; therefore, profiling them makes them feel confused and boxed in. You should avoid profiling people by not using language that implies understanding or judgment of their emotions and preferences.
We can also use attributions to help people understand the trustworthiness of a result. I'm an astronomy enthusiast and I wanted to see which planet was visible in the sky tonight. So I asked Siri, "When can you see Jupiter?" Siri tells me when the event will happen but also gives me more information from Wolfram Alpha. This helps me understand that it's a reliable prediction because Wolfram Alpha is a well-known knowledge engine. This is really important when it comes to displaying predictions where the trustworthiness of the source really matters like scientific information or election results. Cite data sources so people can determine how reliable a certain prediction might be.
Now attributions can be used for more than just explaining personalization or predictions. We can also use it to communicate confidence. Let's look at the App Store again and see how we really try to avoid technical jargon here.
For example, we could've said these apps are an 85% match for you but it's really difficult to understand what 85% mean. That number might also mean different things to different people. That's why we try to use a more understandable explanation such as recommendations based on apps you've downloaded. That 85% I mentioned is a measurement of confidence or how certain the model is that you'll like the recommendations.
Confidence is what you get from a machine learning model but it's important to translate it into something more understandable for people. Sometimes it's OK to directly display confidence.
The Weather app gives you information that it's going to rain but it also gives you a percentage for how likely it's going to rain. Now you might think what kind of a decision should I make based on this 30% chance.
Is it worth bringing my umbrella? It's unclear. But we've been conditioned to understand this percentage over time.
And while numbers are appropriate for statistical predictions such as weather, sports results or election predictions, it might not work in other situations. This is Hopper. It's an app that helps you book cheaper flights.
It uses confidence to tell people whether the fare will go up or down.
And we don't expect people to grapple with percentages here because in this context, percentages are difficult to interpret. Seeing a 65% chance the price will go down is not really actionable. How is 65% different than 70%? The way Hopper presents confidence is by giving you actual suggestions for actions you should take, whether you should wait or buy now.
It also provides additional context such as how much money you're going to save and the optimal time range to book a flight.
These additional explanations help people make a more informed decision.
When confidence is used appropriately, it can make an experience feel so much more human. Most of the time you should prefer to translate confidence into easy-to-understand terms to help people make a decision.
So by this point, you probably understand that confidence can be a great tool to help people estimate how risky a certain decision might be but there are cases where this doesn't work.
For example, if I ask you how long it would take for me to get between here and San Francisco and you replied, "I'm 72% confident you'll get there at 1:30." That would be pretty confusing. How can I be sure what time I'll actually get home? A better way is to provide a range in the prediction.
With ride sharing, it's often difficult to pinpoint an exact arrival time since there might be traffic or the driver might pick up more riders.
Lyft help people estimate when they will arrive at their destination before they book a ride by providing a range about the time the driver will pick you up and the time you will arrive at the airport.
These ranges help me have a realistic expectation of when I'll actually get home.
Range can be a great tool to help people estimate how risky a certain decision might be.
Now these are all good examples of how to display confidence but what do you do when there is low confidence and the model doesn't have enough information to actually take an action? In a lot of cases, we can actually ask people for help.
For example, the Photos app can automatically recognize people in order to make searching for their pictures easier.
When Photos has low confidence who is in a picture, it will ask people to confirm additional photos of that person before automatically labeling them.
Asking for confirmation is important because it'd be annoying if I saw pictures that were marked as me that weren't photos of me at all. With every photo I mark as me, Photos become better at recognizing who I am.
This is an example of a limitation that the facial recognition in Photos has, which also brings me to our last output pattern. So what actually is a limitation? A limitation is that when there's a mismatch between people's mental model of a feature and what the feature can actually do. I might expect Photos to always know who I am even though it can't do that yet because a photo might be blurry or taken in low light or not in focus. Every feature has limitations whether by design, capability, or circumstance. You have to strengthen people's trust in your app by acknowledging its limitations and teaching people how to work with them. Now Memoji is one of my favorite features but people might not understand that it won't work in certain scenarios, whether your face is not in view, something is covering the camera, or you're in a dark room. Every time this limitation occurs, we instantly show these inline coaching tips to help people move past the limitation and successfully use the feature. Explaining the limitations when they happen help people learn to avoid these situations in the future. People might lose trust in your feature if limitations are not appropriately addressed.
You should take care to manage people's expectations of what a feature can actually do and guide people to move past limitations.
Another way to help people move past limitations is to suggest alternative ways to accomplish their goals. In order to do this right, you need to understand the goal well enough to suggest alternatives that actually make sense.
For example, if people ask Siri to set a timer on a Mac, it can't perform the action because timers aren't available at MacOS. Instead of simply replying, "I can't do it," which is kind of frustrating, Siri suggests setting a reminder instead.
This suggestion actually makes sense because Siri understands that the goal is to receive an alert at a certain time and setting a reminder accomplishes the same goal as setting a timer.
When possible, suggest alternatives that can help people accomplish their goals. I hope these patterns have given you some ideas on different outputs that you can get from a machine learning model. But you have to remember that outputs are a design medium.
By understanding the types of outputs that are available, you can choose outputs that align with the experience you want to build and not just rely on standard outputs from the model. We should respect people's agency and time by choosing outputs that are easy to understand and effortlessly helpful.
As you've seen, there are many different ways to translate outputs from the model to the interface. But of course, outputs aren't static. They're dynamic and constantly update based on inputs.
People interact with the experience through inputs and now Cas will tell you all about how to design for inputs. Thank you. So Rubii showed a range of outputs that people can interact with on the interface and these interactions serve as inputs that we can use to collect feedback for information from people so we can improve our experience.
These are the four inputs we will discuss.
Calibration helps you get essential information for someone to engage in your experience.
Calibration allows you to collect important information from interactions someone has with your experience.
Explicit feedback also allows you to collect information but this time by asking specific questions about the results you're showing.
And corrections allow people to fix a mistake a model has made by using familiar interfaces. So let's start with calibration.
As I just said, calibrations allow people to provide essential information for them to engage in your experience. We can use calibration for example to collect biometric data or data about your surroundings. Let me give an example.
Let's look at HomeCourt. HomeCourt is an app that helps you become a better basketball player. It uses machine learning to analyze images from the camera and detect for example how accurately you take shots at the hoop.
In order to do so, the camera needs to be calibrated so it can detect you, the hoop and the court. And HomeCourt has done an amazing job at doing this fast and intuitively. You simply point the front-facing camera to the hoop and it immediately detects it by putting a wide square around it. It then asks you to make one shot and from then on, you're good to go and it will start counting your shots. What's remarkable here is what HomeCourt is not asking you to do. For example, you don't have to draw lines around the hoop or the court.
It doesn't ask for confirmation on whether it got the hoop right or wrong. And you don't need to take shots from multiple angles.
Calibration also happens in some of Apple's products, for example when you set up Face ID.
Face ID uses calibration to only collect essential information.
It asks you to scan your face twice and from then on, it is set up and it will always keep working regardless of whether you might start to wear glasses or change your hairstyle. So when you're using calibration, try to be quick and effortless and only ask for essential information and, when possible, try to avoid the need for multiple calibrations. Once you're setting up Face ID, we help you along the way. We start with an introduction that clearly states why your phone needs to scan your face. And we do this by explaining both how it works and what it will allow you to do. Throughout the process, we always give you a sense of progress. Here, we fill out the lines around your face. And if this progress might stall, we make sure you never get stuck and we provide guidance to help you move forward. Here, we point arrows that point in which way to look. And at the end, we give the notion of success. We tell you the work is done and the feature can be used now. So always provide help by introducing, guiding and confirming the calibration. Of course, Face ID collects a lot of sensitive information. And so to respect your privacy, we give you a way to edit or remove this information in Settings.
So when possible, allow people to update their information. Now as I said before, Face ID asks for just one calibration and from then on, it will keep working regardless of whether you might start to wear glasses, change your hairstyle, maybe wear a hat or a scarf sometimes or even as your face changes as you become older.
This was a big challenge when we designed Face ID. It would've been a lot easier to occasionally ask to recalibrate your face so your iPhone or iPad could keep recognizing you. But who would like to rescan their face each time they change their hairstyle? So instead of asking for multiple calibrations, Face ID collects implicit feedback to update the information about your face each time you use Face ID. And that brings us to our next pattern which is implicit feedback.
Implicit feedback is information that arises from the interactions people have with your app and that information can be used to improve the model and your feature.
A very common example of using implicit feedback is personalization. For example, Siri personalizes the search experiences on iOS based on how you use your device. When you trigger the Search bar on your Home screen, Siri presents a range of apps you might want to use.
Which apps appear here depends on the implicit feedback you give to Siri. These might be apps you frequently used, maybe ones you've just used or ones you use typically at this time of day.
For example in the car, I might get Maps so I can get directions or music and podcasts so I have something to listen to.
At work, I might get apps that help me at a meeting like Notes or Reminders and at home, I might get Messages to text friends or family or suggestions to check my activity or news. Based on how I use these apps, Siri tries to identify my intent so it can surface apps to help me achieve that intent.
So when you're using implicit feedback, strive to identify people's intent by looking at how they interact with your feature. Over time, Siri will get better at understanding my intent and, apart from just showing apps as a suggestion, it might also start suggesting shortcuts of actions I frequently perform.
For example in the car, I might get directions to places I frequently visit or the location of my next meeting.
At work, I might get shortcuts to my meeting notes or my work reminders. And at home, I might get shortcuts to turn on the lights or message or FaceTime my closest friends and family.
These shortcuts appear after a few days or weeks. The more specific they are, the more certain Siri needs to be about my intent.
As I said, these shortcuts are based on implicit feedback, so it might take a while for Siri to be certain enough about a suggestion and that's OK.
It's better to be patient and become certain of a suggestion than to be quick and show an unhelpful suggestion. So bear in mind that implicit feedback can be slow but it also can be more accurate over time. Now these suggestions can appear on the Lock screen and it might be that they contain some sensitive information. For example, it might show an event you want to keep as a surprise or notes you might want to keep secret. To respect people's privacy, we added settings for you to control which app and which app shortcuts can appear in Search. So respect people's privacy and give them full control over their information. Treat it privately and securely. So implicit feedback is a great tool for personalization but you can also use it for some maybe less obvious purposes, for example simply making a direction faster or more accurate.
One good example has been with us since the beginning of iOS and that's the keyboard. Each key on the keyboard has a touch area and the keyboard uses machine learning to optimize these touch areas based on what you type.
Each touch area might become bigger or smaller depending on the word you're typing or the way your fingers are positioned on the keyboard. Now notice that we're not visibly making these buttons any bigger or smaller. The keyboard always appears in the same way. But over time, the keyboard might start to feel more accurate and more personalized to you.
So use implicit feedback to make your interactions more accurate and delightful.
One last example are the Siri suggestions in Safari. Safari uses machine learning to collect links from messages, mail, your reading lists, your iCloud tabs, and other places. And hopefully these suggestions are good and they help you discover interesting content from your friends and family or ones you've saved yourself. Occasionally, though, you might get suggestions you'd rather not see, maybe an article you're not interested in or a source you don't really trust.
If all of these suggestions turn out to be unhelpful, you might start losing trust in the suggestions or even worse, start to lose trust in Safari. And that is obviously something we would like to avoid.
Rubii talked about attribution that can really help here in explaining why we're showing these suggestions but we also want to make sure you can control these suggestions so you can get rid of the ones you don't want to see and make sure they don't appear again.
And that brings us to our next pattern which is explicit feedback.
Explicit feedback allows your app to collect information by asking specific questions about your results. In the previous example, it would be great if I could get feedback on these suggestions that I don't want to see and that way the model can learn and can avoid showing similar suggestions in the future.
So how do I design these feedback actions? Here are two actions that frequently appear when we're using explicit feedback: the heart and the heart with a strikethrough. Now seeing these as buttons leaves a lot of room for interpretation. It's unclear what will happen when I press one of these even if I add labels like Love or Dislike.
Let's say I want to get feedback on the third article here. I can bring up the Action menu and I can see the action Love.
That leaves a lot of room for interpretation. Does this mean I have to love every article that I like? Positive explicit feedback implies additional work. People might think they have to give positive explicit feedback to every article they like just to get more good suggestions.
So we actually recommend to prioritize negative feedback over positive. Positive feedback can better be inferred through implicit signals, for example me reading the article, bookmarking it or sharing it.
So instead of showing both Love and Dislike, we can actually only show Dislike.
But still, that leaves a lot of room for interpretation. If I dislike an article, am I disliking the article, the author, the source, the person who sent it to me, or maybe even the app in which I received it? It's still difficult to understand what will happen when I tap Dislike. Words like "suggest less" or "hide the suggestion" make it much easier to understand what will happen when I tap such a button.
To give people even more control, we can allow them to select exactly what they like to see less, for example less of the source, the person who sent it to me or the app in which I received it.
So when using explicit feedback, clearly describe the option and its consequences. Use words that describe what will happen. And when possible, provide different options to better understand the user's preference. And of course, when I select one of these options, the interface should immediately reflect my choice and hide the suggestions that match my preference.
So always act immediately and persistently when the user gives explicit feedback.
So you've seen that explicit feedback allows us to correct suggestions that might be wrong, unwanted or inappropriate.
But for some machine learning features, using explicit feedback might not be the right choice or might not even be possible.
Here's Angie again, the dog from our friends. She's often the main topic in our group conversation.
Now the keyboard uses machine learning to suggest corrections of what I'm typing. And when I initially type the word "Angie," it wanted to correct it to the word "angle." Now that's obviously wrong but using explicit feedback here seems a little bit off. Let's say I can bring up a contextual menu here.
This doesn't feel very intuitive and it doesn't really allow me to say what I actually meant.
Instead, I can simply select the words and correct the suggestion the keyboard has made by retyping it and this time the keyboard will not autocorrect it. The keyboard learned from my correction and the next time I type in Angie, it knows I'm referring to a name and not the word "angle." This is the most obvious example of our last pattern which is corrections.
Corrections allow people to fix a mistake a model has made by using known tasks. And with known tasks, I'll explain what that means.
In the previous example, you've seen that we corrected this using standard text controls. There was no new interface that we showed here. Everybody knows how to do this since this is how the keyboard's always worked.
Corrections are, therefore, an amazing pattern to optimize your results without feeling like extra work. Let me give another example.
Photos uses machine learning to optimize your pictures. It can help find to the right rotation or cropping your pictures could take.
The way Photos suggest these croppings or rotations is quite subtle. When you go into Edit mode and select Rotation or Cropping tool, photos will crop or rotate the picture for you. Now it doesn't apply the rotation or cropping, it simply suggests it as a starting point.
If you like what Photos has done, you can simply tap Done and the rotation or cropping is applied. But if you'd like to change what Photos has suggested, you can simply use the slider at the bottom to rotate or drag the corners to crop. So these are great examples of corrections. We show you familiar controls and we learn from the corrections you make. So that concludes the last pattern.
Allow corrections through familiar ways. This makes it easy and fast for somebody to correct.
Provide immediate value when somebody makes a correction. As we saw with the text correction, the keyboard won't autocorrect things that we typed.
And use corrections as implicit feedback. Corrections work great as implicit feedback to improve your machine learning results. So those are all the interface patterns we wanted to show you today. As you can see, many of these patterns leverage existing interface elements we've had for a long time. Machine learning, therefore, is an elevation of what we've been doing all along. These patterns are not necessarily new but they are applied in a new context. And whenever we choose our patterns, we have to make sure we respect people's work.
Adding additional attribution or additional feedback actions asks even more information for someone to parse and that invades their attention and might distract them from their task at hand. So choose your patterns with people in mind first. So designing a machine learning experience is not just outputting your results in an interface.
The way we select our data, metrics, inputs and outputs plays a very important role in making these experiences understandable, intuitive and delightful. Now to end our talk, I want to go back to something that Kayur said in the beginning.
Apple uses machine learning to create products and experiences we could never create before, products and experiences we really care about.
You've seen examples of how machine learning helps us manage our attention, on how it allows us to give you better recommendations, on how it can present contextual information at the right time, and how we can automate mundane tasks so you can focus on what matters. But machine learning can help us achieve much more than that.
Apple has always used technology to empower everyone and machine learning only elevates that capability. It can empower us to be healthy by measuring our activity and our steps. Machine learning allows us to be more inclusive by leveraging our communication, for example by adding voice control to the camera so a blind person can see what they're holding or it can know when their loved ones are in frame. Machine learning helps us to be safe by detecting problems with our heart by measuring our heart beats or an ECG. And lastly, it can allow us to be creative by seeing the world in a whole new way, for example by letting a known tool like a pencil do magic things on screen.
So you can see when we align the we create with the values we uphold, we can create experiences that really elevate the best of humanity. That's everything we had in store for you and we hope we've given you plenty of inspiration, insight into designing great machine learning experiences.
All the patterns we talked about and more are available on the Human Interface Guidelines as a beta. There are still a few more talks this afternoon about machine learning and all of us will be available in the coming hour at the User Interface Design Lab to answer any questions you might have. So make sure to come by and say hi. Thank you all for attending and enjoy the last day of WWDC. [ Applause ]
-