-
Core Data: Sundries and maxims
Core Data is the central way to durably and persistently store information from your app — and we're going to show you how to refine that implementation for even faster data ingest and fetching. Discover how you can improve data capture with batch insert, tailor fetch requests to your data needs, and react to notifications about changes in the persistent store.
To get the most out of this session, you should know and have interacted with Core Data in the past. For more information on the framework, watch “Making Apps with Core Data.”Resources
Related Videos
WWDC19
-
Search this video…
Hello and welcome to WWDC.
Hello, everybody. I'm Rishi Verma from the Core Data team. This session, we'll show you how to harness Core Data to best fit the needs of an application. To start, we'll investigate how to populate and maintain your persistent store quickly and efficiently with batch operations.
Then we'll go over how to tailor a fetch request to match the needs of an application.
Lastly, a few tips and tricks on how an application could react to changes in the persistent store.
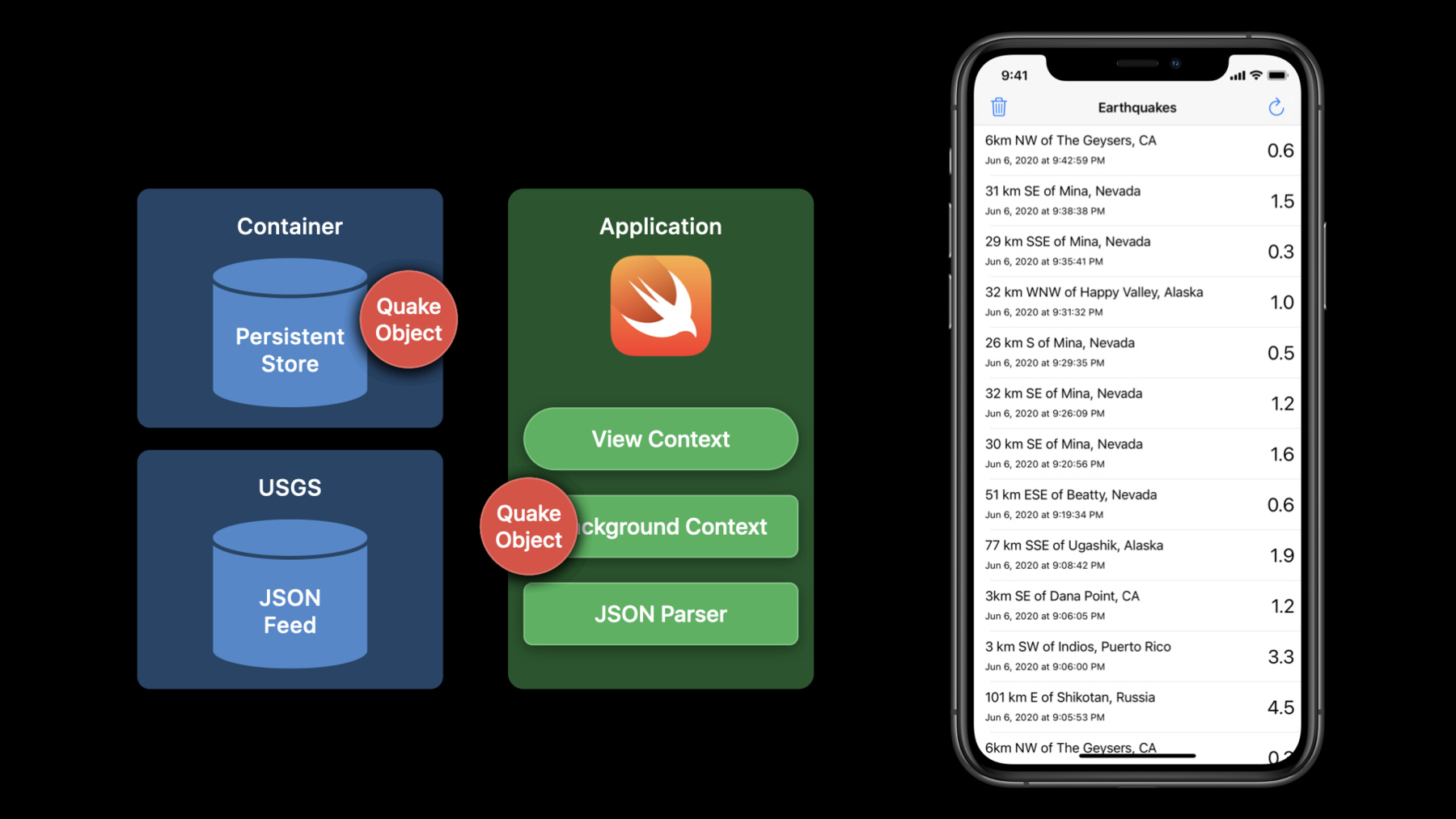
Let's start with a look at our sample, Earthquakes. It is a Swift application that has a view context to drive the UI and a background context to ingest the data provided by the US Geological Survey. Our sample has a local container for our application and gathers quake data from the USGS's JSON feed.
Here, we send the JSON feed to our JSON parser, which in turn sends the data over to our background context to be turned into quake managed objects and saved to our local store.
Our view context then merges changes to magically update our UI.
Now, our background context could be working with a large number of managed objects that are created or fetched only to be discarded shortly after the save. But this is where batch operations shine.
Batch operations allow developers to do inserts, updates and deletes with ease, while being as minimal as possible. Due to the minimalist nature of these operations, a few caveats.
There are no save notifications posted because, well, obviously we're not doing a save here.
And because we did not manifest the managed objects, we do not get any callback or accessor logic for our changes. But wait. You can work around these two caveats with persistent history.
Enable persistent history, and your batch operations are captured so that a notification can easily be acquired, and now we've worked around that first caveat of the batch operations. As for the callbacks and accessor logic, we can accommodate that by parsing our persistent history for the relevant changes to our application's current view. How about we dive deeper into batch operations? The first thing our applications generally do is load data into the persistent store, which in turn drives our UI. When we introduced NSBatchInsertRequest, it gave developers the power of a batch operation for data ingestion. It streamlined the ability to ingest a ton of data, and now we have expanded the abilities of NSBatchInsertRequest.
Initially, we gave developers the ability to pass an array of dictionaries for a batch insert. The array of dictionaries represented the objects to create with the keys as attribute names and their assigned values.
And we have a new addition, an initializer that allows developers to give a block to fill out a given dictionary or managed object. This greatly reduces the peak memory of an ingestion while also reducing the number of objects allocations even further.
How about we see an example? In this snippet of code, we're creating managed objects for our quake...
and populating them with values for our quake data provided by the USGS.
Then we save. Let's see how this code would look if we adopted NSBatchInsertRequest.
First, we gather a dictionary of all the quake data and add it to our array.
We create a batch insert request and execute.
Simple. Now let's see this block variant of batch insert request. We create the batch insert request with a block that will assign values to a given dictionary.
We then execute the request, and this block is called until it returns "true" as the indicator to stop and save. But how do these three different ways perform? Let's look at how our application performs when we ingest a large number of earthquakes. When we save the context with managed objects, we see it takes over one minute and idles out with roughly 30 megs of memory usage.
The initial peak is the JSON data, and most of that first minute isn't actually the ingestion, but the merging of change notifications since we did a huge number of transactions. But we don't have that issue with batch inserts. When we use the NSBatchInsert with an array of dictionaries, we finish the same operation with 25 megs of idle memory and are able to save the same number of objects in only 13 seconds, a fraction of the time needed for a traditional save.
But we can do even better. Let's use the new block ingestion, and we're able to ingest all of the objects in 11 seconds. Now that we've optimized our data population, let's learn a neat trick about batch inserts. Here, we have our managed-object model from the Earthquakes Sample, and I have the quake entity selected. On the right-hand side is the data model inspector for our quake entity. Let's take a closer look. We can see that the attribute "code" is a unique constraint. This means that only one object can have a specific value for "code" in the persistent store. No other quakes can have the same value for "code." How does this come into play with our Earthquakes Sample? Well, our JSON feed gives us all of the quakes for the last 30 days, and every time our user hits the reload button, we ingest all of the data from the JSON feed, which is mostly the same data except for a few quakes that have happened recently, and updated data on past quakes. Here we have a quake with code 42 coming from our JSON feed into our parser.
Then it is passed to our background context, which saves quake 42 into the store.
The first time it is ingested, we create a new row in our store. However, on subsequent attempts to insert the same quake, we don't want to delete the old one and insert the new one. We would really like to update any data that has changed, and in SQL that's called an UPSERT.
UPSERT is an SQL term that is easier to understand if you see the SQL at the same time. So, here we have our insert of our quake object, and while inserting, if we have a conflict on code, update these properties instead of inserting. How do you get this behavior? Simply set the mergePolicy on the context, executing the batch insert request to NSMergeByPropertyObject- TrumpMergePolicy.
But there is a simpler way to do updates, and it couldn't be simpler with batch updates.
With the NSBatchUpdateRequest, there is no need to execute the fetch request only to update the managed objects and save. An NSBatchUpdateRequest can quickly and efficiently update the properties in our objects that meet the search criteria defined in the fetch request.
Let's check out a quick example.
Using our Earthquakes Sample app, we could mark all of the quakes as validated if we were able to confirm them with another source. Well, let's imagine our source only validates earthquakes if they have a magnitude greater than 2.5.
Well, we can build a batch update for this. This code creates a batch update request for "Quake" and then sets the propertiesToUpdate "validated" equals "true" and sets our predicate, magnitude greater than 2.5.
Then we execute our batch update, and we're all done. It's just that simple. So we've covered inserts and updates. Let's do batch deletes.
Batch deletes are very powerful and can be used to easily delete large portions of the object graph. Relationship rules are observed, so deletes will cascade and relationships will be nullified. The general use case we have seen is from expiration code that determines the time to live for objects and cleans up those objects that have reached their expiration.
This is a great use of this API. However, what seems like a simple operation can have complex ramifications. How about an example? Here, we have an example where our earthquake data expires after 30 days.
And since this is a clean-up task, we have it dispatched asynchronously with a background priority. Our block kicks off on the managed object context and determines the expiration date. Then we build our fetch request and set our expiration predicate...
create a batch delete request with our new fetch request, and execute.
Hmm. But what if we had a large number of objects that matched our batch delete search criteria? The request would take a write lock on our store for, uh-oh, possibly some unbounded amount of time.
But wait. We can fix this.
Let's set a fetch limit. This way our task doesn't go unbounded, and we've saved our user from a lot of frustration.
Now that we've avoided this pitfall, let's see how we can improve how to fetch data. Now that we have this rich object graph, we need to investigate and display what we have in our store. When fetching data, the data we get back can drive a lot of views and computations. But do we always need that much data? And how can we do these complex computations without the entire object graph? Well, first, the managedObjectResultType provides the easiest way to traverse the object graph to the fullest extent.
This is great when we're using the results to batch a fetchResultsController. As our managed objects are updated, our fetchResultsController magically responds and applies the diffs. Let's see this in action. Here's our Earthquakes Sample without any data, and then we fetch.
As the objects are fetched, our fetchResultsController is adding rows.
And as we update these objects, our view is also updated. But if you notice here, our view only shows about 15 earthquakes. We fetched a lot more than that. We have some room for improvement here. By setting the batch size on our fetch request, the results will only have the first batch of a given number of objects fully hydrated with data. And when our user scrolls, the remaining objects will be hydrated, but only as far as the user needs.
The batched array is special and behaves differently than a traditional array. Let me show you.
Here, we have a regular result array. All our managed objects are hydrated, and as we iterate over them, all is as expected.
Now we have a batched array. Notice that we do not have managed objects but ObjectIDs that will turn into managed objects upon iterating over the array. And as I move on, the batches are released and only the ObjectID is retained for the results.
Let's see this in action. Here's our Earthquakes Sample fetching data, and it shows the idle memory at roughly 17 megs.
Well, what if we turn on batch fetch? When we set the batch size, we only use roughly 12 megs of memory to do the same task, and we've saved almost five megs, nearly a third of our application's memory usage.
How else can we improve our fetches? We can trim down what data the fetch fetches. If we know the result will need certain attributes or relationships, we can tailor our fetch to these requirements.
For the known attributes that will be accessed, we can set propertiesToFetch. When we work with managed objects, the default behavior is to have the relationship set as "false," and the first traversal of a relationship will trigger the fetch of the related object. This is great if few relationships are traversed, or none at all. But if it is known that a relationship is highly likely to be traversed, we recommend setting that key path to be prefetched, thus avoiding having to fetch the data at a later time and inefficiently, as the faults are loaded on each traversal.
Here is our baseline fetch, which sits idle at 17.6 megs.
But if we set the propertiesToFetch to only those attributes visible in our UI, we can reduce our idle memory to 16.4 megs.
Now let's talk about ObjectIDs.
Managed objects are large and rich with data, but these are not ideal to pass between threads, so ObjectIDResultType comes in handy. When we want to do the work and identify the objects that meet a certain criteria, these simple identifiers can be passed to other threads for further processing, avoiding that lookup cost on the processing thread. But what if we need something in between a full managed object and ObjectIDs? Like dictionary results, which are very handy as they provide a lightweight, read-only data set that can be passed to other threads.
Dictionary results can also be tailored to do complex data aggregation that can help reduce large computations that would normally require pulling in the relevant object graph...
such as groupBy with aggregate functions on the entities and their properties. Let's look at an example.
Average magnitude grouped by place. First, we determine our key path expression for magnitude, then our function expression to get the average.
Then we make an expression description of our average magnitude.
And lastly, we set up our fetch request for quakes with properties to fetch, our expression description and the place, grouped by the place, and set the result to "dictionary." And this leads to these results, which show us the average magnitude for earthquakes in the designated places. Our last result type to cover is the countResultType. It's simple, elegant and optimized.
Need I say more? We've optimized ingestion and fetching. Now let's look at how we can improve our application's reactions to changes in our persistent store. Core Data is rich with notifications that let you know when stores have been added or removed, or objects have been saved or changed. But we want to focus on two in particular that are really useful. This year, we've introduced ObjectID notifications that are available in addition to the traditional save notification. The ObjectID notification is a lightweight counterpart to the managed object save notification you're already familiar with, and this convenient notification is vended from persistent history transactions. Let's look at these new additions in Swift. The managed object context now has modernized notifications for Swift. We've updated some oldies but goodies to be friendlier in Swift and added these two new notifications that allow you to drive your application with ObjectIDs rather than managed objects. But that's not all that we've modernized. As part of our efforts to modernize, we've also added notification keys that make notification processing much easier in Swift.
We've also added some new keys to go with the ObjectID notifications. And the other notification we want to discuss is the remote change notification.
Remote change notifications are very informative because they're posted for all operations that are done in and out of your process by any Core Data client.
This allows your application to avoid polling for changes and be able to drive that same logic with notifications.
And when persistent history is enabled, the userInfo of a remote change notification contains a persistent history token which can be used to get an ObjectID notification. Let's see this in the works.
Here we have our container and application and a table showing our persistent history that has been captured so far.
The JSON feed from the USGS comes online, and the background context ingests the JSON data into the persistent store.
And persistent history captures the operation with great detail, much more than we can show you here.
Previously, though, our application would need to poll the store for new changes. But not with remote change notifications. Instead, we're notified that changes have been made, and the userInfo payload for the remote change notification has a history token so I can see the exact operation in persistent history. Let's see how this works as our application evolves.
Our application has some new additions: a share extension, a second application that harnesses the same data, and a handy Photos extension. When one of these new additions makes a change to the persistent store, the operation is recorded in persistent history.
However, when an application comes to the foreground, it needs to poll for history, which is really expensive.
But if we have remote change notifications enabled, we get notified when our app is brought to the foreground...
and on subsequent changes by our Photos extension...
and our second application...
and our share extension.
When our app relaunches, it is notified and can easily see what has changed with persistent history.
These two features make it really easy to know who, what, when, where, and how the persistent store has changed. Lastly, a quick tip on persistent history.
A rather handy tip for persistent history is the same we told you earlier for fetch requests. Make sure to tailor the request to your application's needs.
Here, we have an example of how to tailor the change request so that we can find all the changes for a specific ObjectID after a given date.
First, we start off by getting our entity description for the persistent history change object...
so that we can use it to build our fetch request and set the entity.
Then we set our predicate here, looking for changes to a specific ObjectID, and then we create our history request, and set the fetch request.
And voilà, execute. Our results will only be those changes for the given ObjectID after the specific date. That's all we have for this session. A quick recap: batch when possible, tailor your fetches to the intended use and harness the power of notifications and persistent history. Thanks to all of you and to the Core Data team. It's been an honor.
-
-
1:48 - Batch Operations - Enable Persistent History
storeDesc.setOption(true as NSNumber, forKey: NSPersistentHistoryTrackingKey) -
2:32 - NSBatchInsertRequest.h
//NSBatchInsertRequest.h @available(iOS 13.0, *) open class NSBatchInsertRequest : NSPersistentStoreRequest { open var resultType: NSBatchInsertRequestResultType public convenience init(entityName: String, objects dictionaries: [[String : Any]]) public convenience init(entity: NSEntityDescription, objects dictionaries: [[String : Any]]) @available(iOS 14.0, *) open var dictionaryHandler: ((inout Dictionary<String, Any>) -> Void)? open var managedObjectHandler: ((inout NSManagedObject) -> Void)? public convenience init(entity: NSEntityDescription, dictionaryHandler handler: @escaping (inout Dictionary<String, Any>) -> Void) public convenience init(entity: NSEntityDescription, managedObjectHandler handler: @escaping (inout NSManagedObject) -> Void) } -
3:01 - Earthquakes Sample - Regular Save
//Earthquakes Sample - Regular Save for quakeData in quakesBatch { guard let quake = NSEntityDescription.insertNewObject(forEntityName: "Quake", into: taskContext) as? Quake else { ... } do { try quake.update(with: quakeData) } catch QuakeError.missingData { ... taskContext.delete(quake) } ... } do { try taskContext.save() } catch { ... } -
3:16 - Earthquakes Sample - Batch Insert with Array of Dictionaries
//Earthquakes Sample - Batch Insert var quakePropertiesArray = [[String:Any]]() for quake in quakesBatch { quakePropertiesArray.append(quake.dictionary) } let batchInsert = NSBatchInsertRequest(entityName: "Quake", objects: quakePropertiesArray) var insertResult : NSBatchInsertResult do { insertResult = try taskContext.execute(batchInsert) as! NSBatchInsertResult ... } -
3:28 - Earthquakes Sample - Batch Insert with a block
//Earthquakes Sample - Batch Insert with a block var batchInsert = NSBatchInsertRequest(entityName: "Quake", dictionaryHandler: { (dictionary) in if (blockCount == batchSize) { return true } else { dictionary = quakesBatch[blockCount] blockCount += 1 } }) var insertResult : NSBatchInsertResult do { insertResult = try taskContext.execute(batchInsert) as! NSBatchInsertResult ... } -
5:42 - NSBatchInsertRequest - UPSERT
let moc = NSManagedObjectContext(concurrencyType: NSManagedObjectContextConcurrencyType.privateQueueConcurrencyType) moc.mergePolicy = NSMergeByPropertyObjectTrumpMergePolicy insertResult = try moc.execute(insertRequest) -
6:30 - Batch Update Example
//Earthquakes Sample - Batch Update let updateRequest = NSBatchUpdateRequest(entityName: "Quake") updateRequest.propertiesToUpdate = ["validated" : true] updateRequest.predicate = NSPredicate("%K > 2.5", "magnitude") var updateResult : NSBatchUpdateResult do { updateResult = try taskContext.execute(updateRequest) as! NSBatchUpdateResult ... } -
7:33 - Batch Delete without and with a Fetch Limit
// Batch Delete without and with a Fetch Limit DispatchQueue.global(qos: .background).async { moc.performAndWait { () -> Void in do { let expirationDate = Date.init().addingTimeInterval(-30*24*3600) let request = NSFetchRequest<Quake>(entityName: "Quake") request.predicate = NSPredicate(format:"creationDate < %@", expirationDate) let batchDelete = NSBatchDeleteRequest(fetchRequest: request) batchDelete.fetchLimit = 1000 moc.execute(batchDelete) } } } -
12:18 - Fetch average magnitude of each place
//Fetch average magnitude of each place let magnitudeExp = NSExpression(forKeyPath: "magnitude") let avgExp = NSExpression(forFunction: "avg:", arguments: [magnitudeExp]) let avgDesc = NSExpressionDescription() avgDesc.expression = avgExp avgDesc.name = "average magnitude" avgDesc.expressionResultType = .floatAttributeType let fetch = NSFetchRequest<NSFetchRequestResult>(entityName: "Quake") fetch.propertiesToFetch = [avgDesc, "place"] fetch.propertiesToGroupBy = ["place"] fetch.resultType = .dictionaryResultType -
13:36 - NSManagedObjectContext.h - Modernized Notifications
//NSManagedObjectContext.h @available(iOS 14.0, *) extension NSManagedObjectContext { public static let willSaveObjectsNotification: Notification.Name public static let didSaveObjectsNotification: Notification.Name public static let didChangeObjectsNotification: Notification.Name public static let didSaveObjectIDsNotification: Notification.Name public static let didMergeChangesObjectIDsNotification: Notification.Name } -
13:54 - NSManagedObjectContext.h - Modernized Keys
//NSManagedObjectContext.h @available(iOS 14.0, *) extension NSManagedObjectContext { public enum NotificationKey : String { case sourceContext case queryGeneration case invalidatedAllObjects case insertedObjects case updatedObjects case deletedObjects case refreshedObjects case invalidatedObjects case insertedObjectIDs case updatedObjectIDs case deletedObjectIDs case refreshedObjectIDs case invalidatedObjectIDs } } -
14:08 - Enable Remote Change Notifications with Persistent History
storeDesc.setOption(true as NSNumber, forKey: NSPersistentStoreRemoteChangeNotificationPostOptionKey) storeDesc.setOption(true as NSNumber, forKey: NSPersistentHistoryTrackingKey) -
16:19 - History Pointers
let changeDesc = NSPersistentHistoryChange.entityDescription(with: moc) let request = NSFetchRequest<NSFetchRequestResult>() //Set fetch request entity and predicate request.entity = changeDesc request.predicate = NSPredicate(format: "%K = %@",changeDesc?.attributesByName["changedObjectID"], objectID) //Set up history request with distantPast and set fetch request let historyReq = NSPersistentHistoryChangeRequest.fetchHistory(after: Date.distantPast) historyReq.fetchRequest = request let results = try moc.execute(historyReq)
-