-
Decode ProRes with AVFoundation and VideoToolbox
Make decoding and displaying ProRes content easier in your Mac app: Learn how to implement an optimal graphics pipeline by leveraging AVFoundation and VideoToolbox's decoding capabilities. We'll share best practices and performance considerations for your app, show you how to integrate Afterburner cards into your pipeline, and walk through how you can display decoded frames using Metal.
Resources
-
Search this video…
Hello and welcome to WWDC.
Hi, and welcome to ProRes Decoding with AV Foundation and Video Toolbox. Our goal today is optimizing the path from a ProRes movie file, or really any other video, into your application.
So, you have an amazing video-editing app in a really cool Metal rendering engine. You want to ensure that users have the best possible experience working with ProRes content in your app.
Our goal is to make two things happen: leverage available hardware decoders, like Afterburner, and make sure that you have an optimized and efficient path for the flow of compressed data, as well as for the frames coming out of the decoder. So, first we're going to do an overview of some of the concepts around integrating video into an app. Then we're gonna discuss how AV Foundation can do it all for you.
But doing it all at the AV Foundation level isn't right for everyone, so next we'll talk a little bit about how you can fetch or construct compressed samples if you choose to drive the decoder yourself with the Video Toolbox.
Then we'll talk a little bit about how to use a VTDecompressionSession. And finally, we'll cover some best practices for integrating decoded video frames with Metal.
All right, let's talk about some basics for working with video on our platforms. First, let's talk briefly about video decoders. Video decoders do a lot of parsing of bitstreams that can come from a wide range of sources not always fully controlled by users. This presents opportunities for malformed media to destabilize an application, or even exploit vulnerabilities and create security issues.
To mitigate these concerns, the Video Toolbox runs decoders out-of-process in a sandboxed server.
This both provides security benefits by running the decoder in a process with limited privileges, but it also adds application stability. If there is a crash in the video decoder, the result is a decode error rather than crashing your entire application. All right, let's talk about the media stack on mac OS, and for this talk, we're going to be focused on video.
At the top, we have AVKit. AVKit provides very high-level options for dropping media functionality into an app. Since we want to integrate with your existing render pipeline, we aren't going to be looking at AVKit.
AV Foundation provides a powerful and flexible interface for working with all aspects of media. We will be looking at a few interfaces in the AV Foundation framework.
We have already, and will continue to talk about Video Toolbox, which provides a low-level interface for working with video decoders and encoders.
The Core Media framework provides many basic building blocks for any media operations on the platform.
And finally, Core Video provides basic building blocks for working specifically with video. So, we're going to be focusing on interfaces from these three frameworks: AV Foundation, Video Toolbox, and Core Video.
In AV Foundation, we'll take a closer look at AVAssetReader as well as AVSampleBufferGenerator. In Video Toolbox, we'll be looking more closely at VTDecompressionSession.
And finally, in Core Video, we'll be looking at integrating CVPixelBuffers and CVPixelBufferPools with Metal.
Let's talk a little bit about some considerations when working at these different API levels.
First, in current versions of the OS, all media interfaces will automatically enable hardware decode when available. This includes enabling Afterburner. We'll talk later about how to selectively enable and disable hardware decode, but by default, it will always be used.
Earlier, we talked about how video decoders run in a separate process. If CMSampleBuffers are created by AV Foundation, they are automatically generated in a form which optimizes them for transfer over the RPC boundary.
When working with VTDecompressionSession directly, whether or not you get this optimized RPC depends on how the CMSampleBuffers are generated. We'll talk more about this later on as we talk about generating CMSampleBuffers.
Next, I want to dive into a little glossary.
First, let's talk about CVPixelBuffers. CVPixelBuffers are essentially wrappers around blocks of uncompressed raster image data. They have inherent properties like pixel format, height, width, and row bytes or pitch, but they can also carry attachments which describe the image data, things like color tags.
Next we have CMBlockBuffer. This type is defined in the Core Media framework and serves as a basic type for wrapping arbitrary blocks of data, usually compressed sample data.
Then we have CMSampleBuffers. CMSampleBuffers come in three main flavors. First, a CMSampleBuffer can wrap a CMBlockBuffer containing compressed audio or video data.
Second, a CMSampleBuffer can wrap a CVPixelBuffer containing uncompressed raster image data.
As you can see, both types of CMSampleBuffers contain CMTime values which describe the sample's presentation and decode timestamps. They also contain a CMFormatDescription which carries information describing the format of the data in the SampleBuffer.
CMSampleBuffers can also carry attachments, and this brings us to the third type of CMSampleBuffer, a marker CMSampleBuffer which has no CMBlockBuffer or CVPixelBuffer and exists entirely to carry timed attachments through a media pipeline signaling specific conditions.
Next we have IOSurface. An IOSurface is a very clever abstraction around a piece of memory, often used for image data. We talked about the raster data in a CVPixelBuffer. That raster data is usually in the form of an IOSurface.
IOSurfaces can also be used as the basis for the memory for a texture in Metal as well.
IOSurface allows the memory to be efficiently moved between frameworks like Core Video and Metal, between processes like the sandboxed decoder and your application, or even between different memory regions, such as transfer between VRAM in different GPUs.
And our final stop in our glossary is the CVPixelBufferPool.
CVPixelBufferPools are objects from Core Video which allow video pipelines to efficiently recycle buffers used for image data.
In most cases, CVPixelBuffers will wrap IOSurfaces. When a CVPixelBuffer allocated from a pool is released and no longer in use, the IOSurface will go back into the CVPixelBufferPool so that the next CVPixelBuffer allocated from the pool can reuse that memory. This means that CVPixelBufferPools have some fixed characteristics, just like CVPixelBuffers: the pixel format, height, width, and row bytes or pitch.
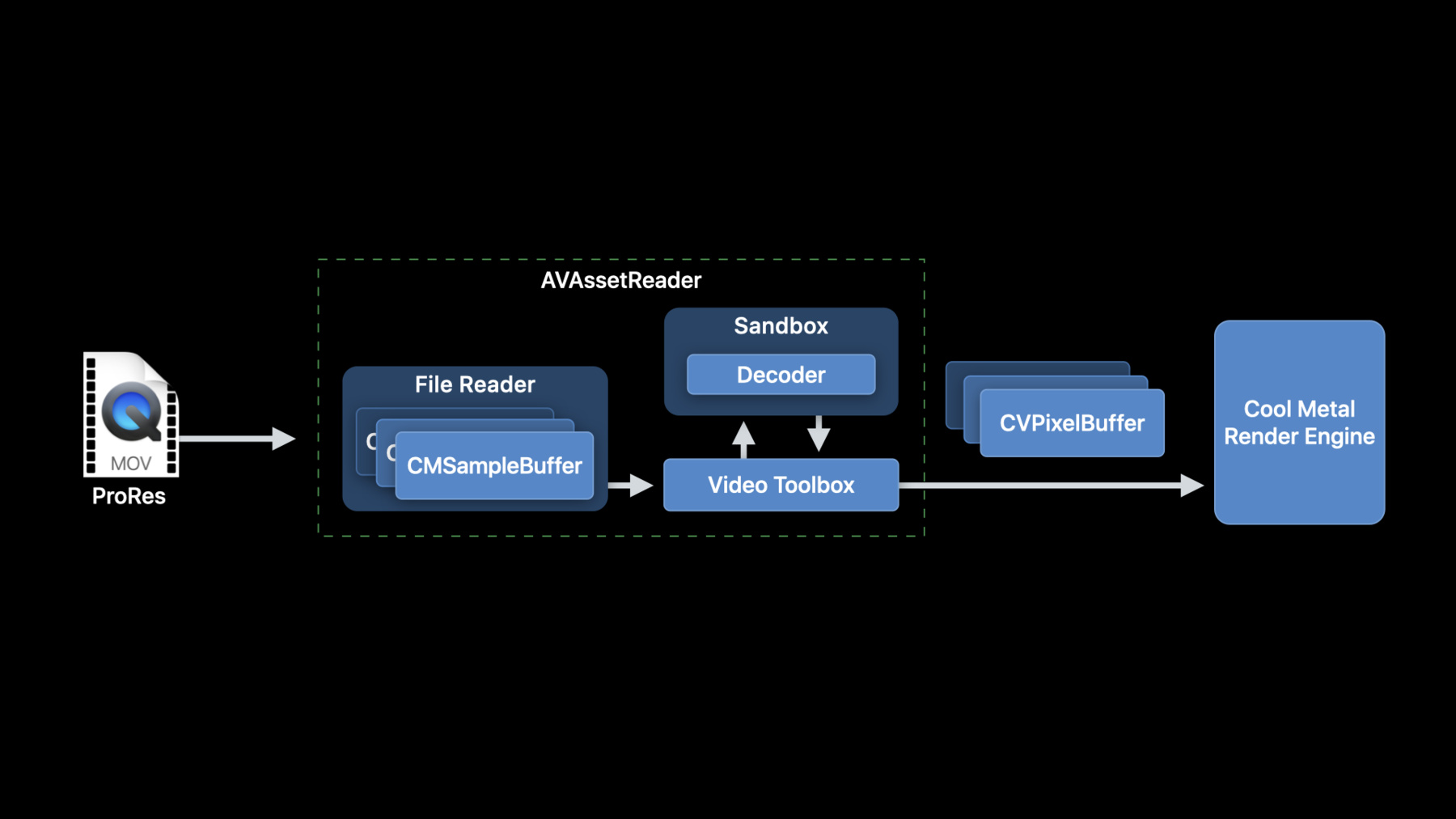
All right, let's get straight into how AV Foundation can do it all for you. Let's go back to our original problem. You have a ProRes movie file, you have your awesome Metal rendering engine, and you want to get frames from that movie into your renderer.
AVAssetReader can do it all for you. It reads samples from the source file, optimizing them for the RPC that will happen in the Video Toolbox. It decodes the video data in the sandbox process, and it provides the decoded CVPixelBuffers in the requested output format.
Creating an AVAssetReader is pretty easy. First we create an AVAsset with a URL to a local movie.
Then we create an AVAssetReader with that AVAsset, but the AVAssetReader isn't ready to use yet.
Requesting decoded data from the AVAssetReader involves configuring an AVAssetReaderTrackOutput.
First we need to get the video track. Here we're getting an array of all of the video tracks in the movie, and then selecting the first track in that array. Your logic for selecting tracks may vary.
Now we create an AVAssetReaderTrackOutput based on the video track we selected. In this case, I'm choosing to configure the output to return 16-bit 4:4:4:4 YCbCr with alpha, or Y416, which is a great native format to use when working with ProRes 4444 content. Next, we're going to instruct the AVAssetReaderTrackOutput to not copy samples when returning them. When setting this, we will get optimal efficiency, but it also indicates that the returned CMSampleBuffers may be retained elsewhere, and we absolutely must not modify them.
And finally, we need to add this output to our AVAssetReader.
Running an AVAssetReader is pretty simple. I'll show you it operating in its simplest possible mode here. First, we just start it reading.
Then we can loop over calls to copyNextSampleBuffer, and since we've configured it to provide decoded output, we check each output CMSampleBuffer for a CVImageBuffer. We will get some marker CMSampleBuffers with no image buffers, but this is okay. Using an AVAssetReader, you can set time ranges or do other more advanced operations rather than this simple iteration through the track. Your video pipeline will be most efficient if your renderer is able to consume buffers in a format that is native to the decoder. AVAssetReader will convert the decoder output from the decoder's native format to your requested output format if you are requesting a format that the decoder does not support. But avoiding these buffer copies will improve your application efficiency immensely. Here are some guidelines on choosing an output pixel format that will not result in a conversion.
In the previous example, we configured the AVAssetReaderOutput to return buffers in 16-bit 4:4:4:4 YCbCr with alpha, or Y416, which is the optimal format when using ProRes 4444.
For ProRes 422, 16-bit 4:2:2 YCbCr, or v216, is the most native decoder format to request.
For ProRes RAW, RGBA half-float, or RGhA, provides the most native output.
Sometimes there's reasons why one doesn't want to rely on AVAssetReader to do everything. In these cases, you'll need to generate CMSampleBuffers to feed directly to the Video Toolbox. There are three main options here. First, you can use AVAssetReader, much like we described a moment ago, but you can request that it give you the compressed data without decoding it first. This provides track-level media access, with awareness of edits and frame dependencies.
Second, there is AVSampleBufferGenerator. This provides media-level access to samples, with no awareness of edits and frame dependencies.
And finally, you can construct CMSampleBuffers yourself.
Letting AVAssetReader generate your samples provides compressed data read directly from the AVAsset. AVAssetReader is doing track-level reading, which means it will provide all samples necessary to display frames at the target time, including handling edits and frame dependencies. Also, as noted earlier, AVAssetReader will provide samples which are optimized for RPC, reducing sandbox overhead when the frames are sent to the Video Toolbox.
In order to get raw compressed output from the AVAssetReader, you simply need to construct the AVAssetReader as described earlier, but when creating the AVAssetReaderTrackOutput, you'll set the outputSettings to nil rather than providing a dictionary specifying a pixel format.
AVSampleBufferGenerator provides samples read directly from the media in an AVAssetTrack. It uses an AVSampleBufferCursor to control the position in the track from which it will read media. It has no inherent awareness of frame dependencies, so this may be straightforward to use with ProRes, but care must be taken when using this interface with content with inter-frame dependencies, like HEVC and H.264. Here's a brief code snippet showing how an AVSampleBufferGenerator is created. First you need to create an AVSampleCursor which will be used for stepping through samples.
You must also create an AVSampleBufferRequest which describes the actual sample requests you will be making.
Now you can create the AVSampleBufferGenerator with your source AVAsset.
Note that I'm setting the timebase to nil here, which will result in synchronous operation. For optimal performance with AVSampleBufferGenerator, you would provide a timebase and run your requests asynchronously.
Finally, I'm looping over calls to createSampleBufferForRequest and stepping the cursor forward one frame at a time. Again, this shows the simplest possible synchronous operation. For optimal performance, one would use async versions of these requests. Finally, you can create CMSampleBuffers yourself if you're doing your own file reading or getting sample data from some other source, like the network. It's important to note that this sample data will not be optimized for transfer over the sandbox RPC.
Earlier, we talked about the components of a CMSampleBuffer. Once again, there's the data in a CMBlockBuffer, a CMFormatDescription, and some timestamps.
So, first you need to pack your sample data in a CMBlockBuffer.
Then you need to create a CMVideoFormatDescription describing the data. Here it would be important to include the color tags in your extensionsDictionary to ensure proper color management for your video.
Next you would create some timestamps in a CMSampleTimingInfo struct. And finally, create a CMSampleBuffer using the CMBlockBuffer, the CMVideoFormatDescription and the CMSampleTimingInfo.
Okay, you've decided to do it yourself and you've created a source for CMSampleBuffers. On to the Video Toolbox. Let's take a look at the anatomy of a VTDecompressionSession.
The VTDecompressionSession, of course, has a video decoder, and as described earlier, this will be running in a separate sandboxed process.
The session also has a CVPixelBufferPool which is being used to create the output buffers for decoded video frames.
And finally, if you have requested output in a format which doesn't match what the decoder can provide, there will be a VTPixelTransferSession to do the required conversion. Before you get started, if your application needs to access the set of specialized decoders distributed for Pro video workflows, your application can make a call to VTRegisterProfessional- VideoWorkflowVideoDecoders. This only needs to happen once in your application. The steps to use a VTDecompressionSession are pretty simple. First, create a VTDecompressionSession.
Second, do any necessary configuration of the VTDecompressionSession via VTSessionSetProperty calls. This isn't always needed.
Finally, begin sending frames using calls to VTDecompressionSession- DecodeFrameWithOutputHandler, or simply VTDecompressionSessionDecodeFrame.
For optimal performance, it's recommended that asynchronous decode be enabled in your DecodeFrame calls. Let's look more closely at creating a VTDecompressionSession. There are three major options that need to be specified.
First is the videoFormatDescription. This tells the VTDecompressionSession what codec will be used, and provides more details about the format of the data in the CMSampleBuffers. This should match the CMVideoFormatDescription of the CMSampleBuffers that you are about to send to the session.
Next is the destinationImageBufferAttributes. This describes your output pixelBuffer requirements. This can include dimensions if you want the Video Toolbox to scale output to a certain size.
It can contain a specific pixelFormat if your rendering engine requires it. If you only know how to consume 8-bit RGB samples, this is where you would request that.
This can also be a high-level directive, like a request to just provide Core Animation-compatible output.
Next is the videoDecoderSpecification, which provides hints about factors for decoder selection. This is where you specify non-default hardware decoder requests.
Speaking of hardware decoder usage, as mentioned earlier, on current OS versions, hardware decoder usage is enabled by default for all formats where it's supported. This is a slight change from a few years ago when it was an opt-in. In current OSes, all hardware-accelerated codecs are available by default with no opt-ins required. If you want to guarantee that your VTDecompressionSession is created with a hardware decoder, and want session creation to fail if it isn't possible, you can pass in the RequireHardwareAcceleratedVideoDecoder specification option set to true.
Similarly, if you want to disable hardware decode and use a software decoder, you can include EnableHardwareAcceleratedVideoDecoder specification option set to false. These two keys are awfully similar, so once more, the first key is RequireHardwareAcceleratedVideoDecoder and the second is EnableHardwareAcceleratedVideoDecoder. This sample shows the basics of VTDecompressionSession creation. The first thing that we need is a formatDescription to tell the session what type of data to expect. We pull this straight from a CMSampleBuffer that will be passed to the session later. If we want a specific pixelFormat for our output, we need to create a pixelBufferAttributes dictionary describing what we need. So, just like in the earlier AVAssetReader example, we're requesting 16-bit 4:4:4:4 YCbCr with alpha. Now we can create the VTDecompressionSession. Note that we're passing in NULL for the third parameter, the videoDecoderSpecification. This NULL means that the Video Toolbox will do its default hardware decoder selection.
Once the VTDecompressionSession is created, the calls to DecodeFrame are fairly straightforward. As mentioned earlier, for optimal performance, the kVTDecodeFrame_Enable- AsynchronousDecompression flag should be set in the decodeFlags.
The block-based VTDecompressionSession- DecodeFrameWithOutputHandler takes the compressed sampleBuffer, the inFlags, which control decoder behavior, and an output block which will be called with the results of the decode operation.
As long as the VTDecompressionSession- DecodeFrameWithOutputHandler call doesn't return an error, your output block will be called with the results of the frame decode, either a CVImageBuffer or a decoder error. A quick note about decompression output. Decoder output is serialized. You should only see a single frame being returned from the decoder at a time. If you block inside of the decoder output, it will effectively block subsequent frame output and ultimately cause back pressure through the decoder.
For best performance, you should make sure that processing and work is done outside of your session's output block or callback.
Now let's talk a little bit about using decoded CVPixelBuffers with Metal. Before diving into this, it's important to review exactly how a CVPixelBufferPool works.
As described before, when a CVPixelBuffer which was allocated from a CVPixelBufferPool is released, its IOSurface goes back into the CVPixelBufferPool, and the next time a CVPixelBuffer is allocated from the pool, the IOSurface will be recycled and used for the new CVPixelBuffer.
With this in mind, it's easier to understand the pitfalls that one can encounter working with CVPixelBuffers and Metal. We need to ensure that IOSurfaces are not recycled while still being used by Metal.
There are two main approaches to using CVPixelBuffers with Metal. One is the obvious bridge through IOSurface. The CVPixelBuffer contains an IOSurface and Metal knows how to use an IOSurface for texturing. But this path requires a bit of extra care.
The second path is through Core Video's CVMetalTextureCache. This is less obvious, but generally simpler to use in a safe manner, and can provide some performance benefits.
Using the IOSurface backing from a CVPixelBuffer directly with Metal appears straightforward, but there's a trick to ensuring that the IOSurface is not recycled by the CVPixelBufferPool while it's still in use by Metal.
To go this route, you first need to get the IOSurface from the CVPixelBuffer, and you can then create a Metal texture with that IOSurface.
But you need to ensure that the IOSurface is not recycled by the CVPixelBufferPool while it's still in use by Metal. So, we use the IOSurfaceIncrementUseCount call.
To release the IOSurface back into the pool when Metal has finished with it, we set up a MTLCommandBuffer completion handler to run after our CommandBuffer completes, and we decrement the IOSurfaceUseCount here.
Using CVMetalTextureCache to manage the interface between CVPixelBuffer and MetalTexture simplifies things, removing the need to manually track IOSurfaces and IOSurfaceUseCounts.
To use this facility, you need to first create a CVMetalTextureCache. You can specify the Metal device you want to associate with here.
Now you can call CVMetalTextureCacheCreateTextureFromImage to create a CVMetalTexture object associated with your CVPixelBuffer.
And getting the actual Metal texture from the CVMetalTextureCache is a simple call to CVMetalTextureGetTexture.
And the last thing to keep in mind here is that once again, you must set up a handler on your Metal command buffer completion, or otherwise ensure that Metal is done with the texture before you release the CVMetalTexture.
CVMetalTextureCache also saves you from repeating the IOSurface texture binding when IOSurfaces which come from a CVPixelBufferPool are reused and are seen again, making it a little bit more efficient.
Okay, so we covered a few topics here. We talked about when you will get hardware decode, and how to control it. We talked about how AV Foundation's AVAssetReader can simply and easily allow you to integrate accelerated video decoding with your custom rendering pipeline. We talked about how to construct CMSampleBuffers and use them with the Video Toolbox if using AVAssetReader on its own isn't a good fit for your use case.
And finally, we talked about some best practices around using CVPixelBuffers with Metal. I hope that what we've discussed today helps you make your amazing video app a little bit more amazing. Thanks for watching and have a great WWDC.
-
-
7:41 - Creating an AVAssetReader is pretty easy
// Constructing an AVAssetReader // Create an AVAsset with an URL pointing at a local asset AVAsset *sourceMovieAsset = [AVAsset assetWithURL:sourceMovieURL]; // Create an AVAssetReader for the asset AVAssetReader *assetReader = [AVAssetReader assetReaderWithAsset:sourceMovieAsset error:&error]; -
7:58 - // Configuring AVAssetReaderTrackOutput
// Configuring AVAssetReaderTrackOutput // Copy the array of video tracks from the source movie NSArray<AVAssetTrack*> *tracks = [sourceMovieAsset tracksWithMediaType:AVMediaTypeVideo]; // Get the first video track AVAssetTrack *track = [sourceMovieVideoTracks objectAtIndex:0]; // Create the asset reader track output for this video track, requesting ‘y416’ output NSDictionary *outputSettings = @{ (id)kCVPixelBufferPixelFormatTypeKey : @(kCVPixelFormatType_4444AYpCbCr16) }; AVAssetReaderTrackOutput* assetReaderTrackOutput = [AVAssetReaderTrackOutput assetReaderTrackOutputWithTrack:track outputSettings:outputSettings]; // Set the property to instruct the track output to return the samples // without copying them assetReaderTrackOutput.alwaysCopiesSampleData = NO; // Connect the the AVAssetReaderTrackOutput to the AVAssetReader [assetReader addOutput:assetReaderTrackOutput]; -
8:57 - Running AVAssetReader
// Running AVAssetReader BOOL success = [assetReader startReading]; if (success) { CMSampleBufferRef sampleBuffer = NULL; // output is a AVAssetReaderOutput while ((sampleBuffer = [output copyNextSampleBuffer])) { CVImageBufferRef imageBuffer = CMSampleBufferGetImageBuffer(sampleBuffer); if (imageBuffer) { // Use the image buffer here // if imageBuffer is NULL, this is likely a marker sampleBuffer } } } -
11:40 - Prepareing CMSampleBuffers for optimized RPC transfer
AVAssetReaderTrackOutput* assetReaderTrackOutput = [AVAssetReaderTrackOutput assetReaderTrackOutputWithTrack:track outputSettings:nil]; -
12:24 - How an AVSampleBufferGenerator is created
AVSampleCursor* cursor = [assetTrack makeSampleCursorAtFirstSampleInDecodeOrder]; AVSampleBufferRequest* request = [[AVSampleBufferRequest alloc] initWithStartCursor:cursor]; request.direction = AVSampleBufferRequestDirectionForward; request.preferredMinSampleCount = 1; request.maxSampleCount = 1; AVSampleBufferGenerator* generator = [[AVSampleBufferGenerator alloc] initWithAsset:srcAsset timebase:nil]; BOOL notDone = YES; while(notDone) { CMSampleBufferRef sampleBuffer = [generator createSampleBufferForRequest:request]; // do your thing with the sampleBuffer [cursor stepInDecodeOrderByCount:1]; } -
13:40 - Pack your sample data into a CMBlockBuffer
CMBlockBufferCreateWithMemoryBlock(kCFAllocatorDefault, sampleData, sizeof(sampleData), kCFAllocatorMalloc, NULL, 0, sizeof(sampleData), 0, &blockBuffer); CMVideoFormatDescriptionCreate(kCFAllocatorDefault, kCMVideoCodecType_AppleProRes4444, 1920, 1080, extensionsDictionary, &formatDescription); CMSampleTimingInfo timingInfo; timingInfo.duration = CMTimeMake(10, 600); timingInfo.presentationTimeStamp = CMTimeMake(frameNumber * 10, 600); CMSampleBufferCreateReady(kCFAllocatorDefault, blockBuffer, formatDescription, 1, 1, &timingInfo, 1, &sampleSize, &sampleBuffer); -
17:47 - VTDecompressionSession Creation
// VTDecompressionSession Creation CMFormatDescriptionRef formatDesc = CMSampleBufferGetFormatDescription(sampleBuffer); CFDictionaryRef pixelBufferAttributes = (__bridge CFDictionaryRef)@{ (id)kCVPixelBufferPixelFormatTypeKey : @(kCVPixelFormatType_4444AYpCbCr16) }; VTDecompressionSessionRef decompressionSession; OSStatus err = VTDecompressionSessionCreate(kCFAllocatorDefault, formatDesc, NULL, pixelBufferAttributes, NULL, &decompressionSession); -
18:30 - Running a VTDecompressionSession
// Running a VTDecompressionSession uint32_t inFlags = kVTDecodeFrame_EnableAsynchronousDecompression; VTDecompressionOutputHandler outputHandler = ^(OSStatus status, VTDecodeInfoFlags infoFlags, CVImageBufferRef imageBuffer, CMTime presentationTimeStamp, CMTime presentationDurationVTDecodeInfoFlags) { // Handle decoder output in this block // Status reports any decoder errors // imageBuffer contains the decoded frame if there were no errors }; VTDecodeInfoFlags outFlags; OSStatus err = VTDecompressionSessionDecodeFrameWithOutputHandler(decompressionSession, sampleBuffer, inFlags, &outFlags, outputHandler); -
20:54 - CVPixelBuffer to Metal texture: IOSurface
// CVPixelBuffer to Metal texture: IOSurface IOSurfaceRef surface = CVPixelBufferGetIOSurface(imageBuffer); id <MTLTexture> metalTexture = [metalDevice newTextureWithDescriptor:descriptor iosurface:surface plane:0]; // Mark the IOSurface as in-use so that it won’t be recycled by the CVPixelBufferPool IOSurfaceIncrementUseCount(surface); // Set up command buffer completion handler to decrement IOSurface use count again [cmdBuffer addCompletedHandler:^(id<MTLCommandBuffer> buffer) { IOSurfaceDecrementUseCount(surface); }]; -
21:42 - Create a CVMetalTextureCacheRef
// Create a CVMetalTextureCacheRef CVMetalTextureCacheRef metalTextureCache = NULL; id <MTLDevice> metalDevice = MTLCreateSystemDefaultDevice(); CVMetalTextureCacheCreate(kCFAllocatorDefault, NULL, metalDevice, NULL, &metalTextureCache); // Create a CVMetalTextureRef using metalTextureCache and our pixelBuffer CVMetalTextureCacheCreateTextureFromImage(kCFAllocatorDefault, metalTextureCache, pixelBuffer, NULL, pixelFormat, CVPixelBufferGetWidth(pixelBuffer), CVPixelBufferGetHeight(pixelBuffer), 0, &cvTexture); id <MTLTexture> texture = CVMetalTextureGetTexture(cvTexture); // Be sure to release the cvTexture object when the Metal command buffer completes!
-