-
Unsafe Swift
What exactly makes code “unsafe”? Join the Swift team as we take a look at the programming language's safety precautions — and when you might need to reach for unsafe operations. We'll take a look at APIs that can cause unexpected states if not used correctly, and how you can write code more specifically to avoid undefined behavior. Learn how to work with C APIs that use pointers and the steps to take when you want to use Swift's unsafe pointer APIs.
To get the most out of this session, you should have some familiarity with Swift and the C programming language. And for more information on working with pointers, check out "Safely Manage Pointers in Swift".Resources
Related Videos
WWDC20
WWDC16
-
Search this video…
Hello, and welcome to WWDC.
Hello, my name is Karoy Lorentey, and I'm an engineer on the Swift standard library team here at Apple. Today I'm going to talk about unsafe APIs in Swift.
The standard library provides many different constructs: types, protocols, functions, properties, and so on. A small amount of these are explicitly labeled as "unsafe". What does this mean? What makes these special? The distinction between safe and unsafe constructs is not apparent in the interface they provide. Rather, it arises from the way their implementations deal with invalid input. Most operations in the standard library fully validate their input before executing, so we can safely assume that any serious coding errors we may make will be reliably caught and reported.
One example for such an operation is the familiar force-unwrapping operator on Swift's Optional type. It does require that the value must not be nil, but if we get this wrong, we are guaranteed to get a nice, clean fatal runtime error. Here, we asked Optional to do something that is nonsensical, so stopping execution is the only responsible thing it can do. Of course, trying to force-unwrap a nil value is still a serious programming error, but its consequences are well-defined.
We say that the force unwrap operator is "safe" because we can fully describe its behavior for all possible inputs, including input that doesn't satisfy its requirements.
So, by extension, unsafe operations must exhibit undefined behavior on at least some input that violates their documented expectations.
For example, Optional also provides an "unsafe" force-unwrapping operation through its "unsafelyUnwrapped" property. Just like the regular force-unwrap operator, this also requires the underlying value to be non-nil. However, when compiled with optimizations enabled, this property does not verify this requirement; it trusts you that you only call it on a non-nil value and directly reads it out.
So what happens when you accidentally call it on nil? Well, it reads a value that isn't there, and it's difficult to say what exactly this means. Depending on arbitrary circumstances, it could trigger an immediate crash, or it may return some garbage value; perhaps it will do something else. It could do the same thing every time, or its result may change on every execution.
The point is that by using this property, you assume full responsibility to fulfill its requirements. If you accidentally violate them, the effects can be unpredictable, and debugging the problem may be extraordinarily difficult.
This is the quintessential property of all unsafe types and operations in the standard library: they all have assumptions that they are unable, or unwilling, to fully verify.
The "unsafe" prefix is a naming convention that works a bit like a hazard symbol. It warns you, and anyone reading your code, of the danger inherent in their use. Interfaces marked "unsafe" can still be used to build code that works reliably; indeed, some tasks can only be done using them. However, you need to be extra careful when you reach for these, and you must fully understand the conditions of their use.
In exchange, though, we get to achieve something that would be difficult or impossible to do otherwise. The use cases of unsafe APIs typically fall into one of two categories: either they provide interoperability with C or Objective-C, or they provide fine-grained control over runtime performance, or some other aspect of the execution of your program.
Optional's unsafelyUnwrapped property falls squarely in the second category. It enables us to eliminate a superfluous check for a nil value. This is best reserved for the most critical parts of our code base, where performance measurements indicate that the tiny, TINY cost of a potentially unnecessary check still has a detrimental impact.
To help us catch potential mistakes, this property only elides the nil check in optimized builds; in unoptimized debug builds, it still fully validates its input value. If you ever implement your own performance-oriented unsafe interfaces, it is a good idea to replicate this behavior, because it makes it so much easier to detect problems during development.
It is important to note that the goal of safe APIs is not to prevent crashes. In fact, it's kind of the opposite: when they are given input outside of their documented constraints, safe APIs guarantee to stop execution by raising a fatal runtime error.
These situations indicate serious programming errors: our code broke a critical contract, and we need to go and fix it. Proceeding with execution would be irresponsible. The crash report generated by the error lets us know the circumstances of how the problem occurred, so that we can debug the problem and correct it.
When we say that Swift is a safe programming language, we mean that, by default, its language and library-level features fully validate their input. Any construct that does not or cannot do this is explicitly marked as unsafe.
For instance, the Swift standard library provides powerful unsafe pointer types that are roughly on the same level of abstraction as pointers in the C programming language. In order to understand how pointers work, we have to talk a little bit about memory.
Swift has a flat memory model: it treats memory as a linear address space of individually addressable 8-bit bytes. Each of these bytes has its own unique address, usually printed as a hexadecimal integer value.
Now at runtime, the address space is sparsely populated with data that reflects our app's execution state at any given moment. It includes: our app's executable binary; all the libraries and frameworks that we have imported; the stack, providing storage for local and temporary variables as well as some function arguments; dynamic memory regions, including class instance storage and memory we manually allocate ourselves; some regions may even get mapped to read-only resources such as image files.
Each individual item is assigned a contiguous memory region storing some sort of data in the same, shared, linear address space. As your app executes, the state of its memory keeps evolving. New objects get allocated, the stack keeps changing, old items get destroyed. Luckily the Swift language and the runtime take care of keeping track of where things are for us. We generally don't need to manually manage memory in Swift.
When we do need to do so though, unsafe pointers give us all the low-level operations we need to effectively manage memory ourselves. Of course, the flip side of all of this control is the responsibility that comes with it. These pointers simply represent the address of a location somewhere in memory. They provide powerful operations, but they have to trust you that you will use them correctly, and this makes them fundamentally unsafe. If you aren't careful, your pointer operations may scribble all over the address space, ruining the carefully maintained state of your application.
For example, dynamically allocating storage for an integer value creates a storage location for you and gives you a direct pointer to it. The pointer gives you full control over the underlying memory, but it does not manage it for you. Neither is it able to keep track of what happens to that memory location later. It merely executes the operations you tell it to do.
The pointer gets invalidated as the underlying memory is deinitialized and deallocated. However, an invalid pointer looks just like a regular valid one. The pointer itself doesn't know that it has become invalid. Any attempt to dereference such a dangling pointer is a serious programming error.
If we are lucky, the memory location was rendered completely inaccessible by the deallocation, and trying to access it will result in an immediate crash. However, this isn't guaranteed. Subsequent allocations may have reused the same address to store some other value. In this case, dereferencing the dangling pointer may lead to even more serious problems. Attempting to write through it may silently corrupt the state of some unrelated part of our application.
This is bad, because this may have arbitrary effects; for example, it can lead to silent corruption or even loss of user data. Such bugs are especially sinister when the values we access contain object references, or when the memory now contains the Swift value of an incompatible type.
Xcode provides a runtime debugging tool called the Address Sanitizer to help you catch such memory problems. For more information on this and similar Xcode tools, see the "Finding Bugs Using Xcode Runtime Tools" session from a previous conference. For a more detailed discussion on how to avoid issues with pointer type safety, check out my colleague Andy's talk on this topic this week.
So if pointers are so dangerous, why would you ever want to use them? Well, a big reason is interoperability with unsafe languages like C or Objective-C.
In these languages, functions often take pointer arguments, so to be able to call them from Swift, you need to know how to generate pointers to Swift values. In fact, there is a direct mapping between C pointer types and their corresponding Swift unsafe pointer counterparts. C APIs that we import to Swift get translated using this mapping.
For example, consider this simple C function that processes a buffer of integer values in some way. When it gets imported to Swift, the const int pointer parameter gets translated into an implicitly-unwrapped Optional unsafe pointer type.
One way to get such a pointer is to use the static "allocate" method on UnsafeMutablePointer to create a dynamic buffer suitable for holding integer values. Then we can use pointer arithmetic and dedicated initialization methods to set up the buffer's elements to particular values. And once that's all arranged, we can at last call the C function, passing it the pointer to the initialized buffer. When the function returns, we can deinitialize and deallocate the buffer, allowing Swift to re-use its memory location for something else later.
We have full control over every operation along the way, but every step is fundamentally unsafe: The lifetime of the allocated buffer is not managed by the return pointer. We have to remember to manually deallocate it at the appropriate time, or it will stick around forever, causing a memory leak.
Initialization cannot automatically verify that the addressed location is within the buffer we allocated. If we get it wrong, we get undefined behavior.
To correctly call the function, we have to be aware if it is going to take ownership of the underlying buffer. In this case, we are assuming that it merely accesses it for the duration of the function call, and it doesn't hold onto the pointer or attempt to deallocate it. This is not enforced by the language; we have to look it up in the function's documentation.
Deinitialization only makes sense if the underlying memory has been previously initialized with values the correct type.
Finally, we must only deallocate memory that was previously allocated, and which is in a deinitialized state.
At every step, there are unchecked assumptions. Getting any one of them wrong will lead to undefined behavior.
Now, this code works fine, but it has some questionable choices. One of these is that the buffer is represented solely by its start address; its length is a separate value that is duplicated all over.
We could improve the clarity of this code by modeling the buffer as a pair of (start address, length) values. This way, the boundaries of the buffer are always easily available, so for example, it becomes possible to easily check against out-of-bounds access at any point.
This is why the standard library provides these four unsafe buffer pointer types. These come in handy whenever we need to work with regions of memory, rather than pointers to individual values. By including the size of the region, as well its location in a nice package, they encourage best practices and let you manage memory more carefully.
In an unoptimized debug builds, these buffer pointers check against out-of-bounds access through their subscript operation, contributing a little bit of safety. However, this validation is incomplete by necessity: it is limited to bounds checking. Like pointers, they cannot verify that the underlying memory is in the expected state. Still, partial checking is far more helpful than no verification at all, and the mere act of considering the length and the address together as a single unit already helps preventing some simple mistakes.
Swift's standard contiguous collections use these buffer pointers to provide temporary direct access to their underlying storage buffer through these handy unsafe methods. It is also possible to get a temporary pointer to an individual Swift value, which we can then pass to C functions expecting such. We can use these methods to simplify our code, isolating unsafe operations to the smallest possible code section.
To get rid of the need for manual memory management, we can store our input data in an Array value. Then we can use the withUnsafeBufferPointer method to temporarily get direct access to the array's underlying storage. Within the closure we pass to this function, we can extract the start address and count values, and pass them directly to the C function we want to call.
In fact, the need to pass pointers to C functions is so frequent that Swift provides special syntax for it. We can simply pass an array value to a function expecting an unsafe pointer, and the compiler will automatically generate the equivalent withUnsafeBufferPointer for us.
Remember, though, that this does not change the fact that the pointer is only valid for the duration of the function call. If the function escapes the pointer and tries to access the underlying memory later, then that will result in undefined behavior, no matter what syntax we used to get the pointer.
Here's a list of such implicit value-to-pointer conversions supported by Swift. As we have just seen, to pass the contents of a Swift Array to a C function, we can simply pass in the array value itself. If the function wants to mutate the elements, we can pass in an "inout" reference to the array to get a mutable pointer. Functions that take C strings can be called by directly passing in a Swift String value: the string will produce a temporary C string, including the all-important terminating NUL character. If the C function simply expects a pointer to an individual value, we can use an "inout" reference to the corresponding Swift value to get a suitable temporary pointer to it.
Careful use of this feature lets us call even the most complicated C interfaces.
For instance, here is a C function provided by the Darwin module that you can use to query or update low-level information about the running system. It comes with six parameters, specifying: the location and size of an integer buffer, serving as the identifier for the value we want to access; the location and size of another buffer, where we want the function to store the current value; and an optional, read-only third buffer containing a new value we may want to set for the specified entry.
However, calling this function from Swift isn't necessarily more complicated as it is in C. We can use implicit pointer conversions to great effect here, resulting in code that is roughly similar in apparent complexity as it would be in its native language.
For example, here we want to create a function that retrieves the size of a cache line for the processor architecture we are running on.
The documentation of sysctl tells us that this information is available under the identifier "CACHELINE" in the hardware section. To pass this ID to sysctl, we can use an implicit array-to-pointer conversion, and an explicit integer conversion for its count.
The information we want to retrieve is a C integer value, so we create a local integer variable, and generate a temporary pointer to it for the third argument, with another inout-to-pointer conversion. The function will copy the size of the cache lines into the buffer starting at this pointer, overwriting our original zero value with another integer.
The fourth argument is a pointer to the size of this buffer, which we can get from the MemoryLayout of the corresponding integer type. On return, the function will set this value to the number of bytes it copied into "result".
Because we only want to retrieve the current value, not set it, we supply a nil value for the "new value" buffer, and set its size to zero.
sysctl is documented to return a zero value on success. We assume that this code cannot fail, but we do verify this assumption in case we've made a mistake in the arguments we supplied. Similarly, we expect the call to set as many bytes as there are in a C integer value.
Finally, we can convert the C integer to a Swift Int, and return the result. As it happens, the cache line is 64 bytes wide on most platforms.
Notice how the unsafe parts are neatly isolated into the single function call.
Of course, we could also choose to expand this code into explicit closure based calls. It would look something like this. This code is functionally equivalent to our original version; choosing between the two styles is mostly a matter of taste. To be honest though, in this particular case, I think I prefer to go with the shorter variant.
Whichever version we choose though, we need to always be aware that the generated pointer values are temporary, and they get invalidated when the function returns.
While inout-to-pointer conversions can be convenient, they are really only intended to help calling C functions. In pure Swift code, we need to pass around pointers far less often, so it makes sense to highlight the cases when we do such things by preferring to use closure-based APIs. They might be more verbose, but I find that their explicitness makes it easier to understand what exactly is happening.
In particular, their closure-based design makes the actual lifetime of the resulting pointer far more explicit, helping you avoid lifetime issues, like this invalid pointer conversion. Here, passing a temporary pointer to the mutable pointer initializer escapes its value out of the initializer call. Accessing the resulting dangling pointer value is undefined behavior: the underlying memory location may not exist anymore, or it may have been reused for some other value. To help catch these sort of bugs, the Swift 5.3 compiler now produces a helpful warning when it can detect such cases.
Another recent improvement is that the Swift standard library now provides new initializers that allow us to create an Array or a String value by directly copying data into their underlying uninitalized storage. This gets rid of the need to allocate temporary buffers only to prepare such data.
For example, String's new initializer can be used to call the same sysctl function to retrieve a string value. Here, we want to find out the kernel version of the operating system we're running on, which is identified by the VERSION entry in the kernel section.
Unlike the cache line example, we don't know the size of the version string in advance. So in order to figure it out, we will need to call sysctl twice.
First, we call the function with a nil output buffer. On return, the "length" variable will get set to the number of bytes required to store the string. Like before, we need to remember to check for any reported errors. With the size of the result on hand, we can now ask String to prepare uninitialized storage for us so that we can get the actual data. The initializer gives us a buffer pointer that we can pass to the sysctl function. The function will copy the version string directly into this buffer. On return, we verify that the call was successful. We double check that the function did actually copy some bytes to the buffer, and that the last byte is zero, corresponding to the NUL character terminating a C string. This NUL character is not part of the version string, so we discard it by returning one less than the amount of bytes copied. This signals to the String exactly how many bytes of UTF-8 data we've copied into its storage.
By using this new String initializer, we get rid of the need for manual memory management here. We get direct access to a buffer that will eventually become storage for a regular Swift string instance. We don't need to manually allocate or deallocate memory. When we call this function, we get the expected version string.
So, as we have seen, we can use the standard library's unsafe APIs to elegantly solve even the most tricky interoperability puzzles.
In summary, to effectively use unsafe APIs, you need to be aware of their expectations, and be careful to always fulfill them; otherwise your code will have undefined behavior.
It is easier to do this if you keep unsafe API usage to the minimum. It is always a good idea to choose safer alternatives whenever they are available.
When working with a region of memory containing more than one element, it is best to keep track of its boundaries by using unsafe buffer pointers rather than just a pointer value.
Xcode provides a set of great tools to help debug issues with how we use unsafe APIs, including the Address Sanitizer. Use these to identify bugs in your code before putting it in production, and to debug problems that may have been uncovered.
And with that, thank you, and have a great WWDC.
-
-
0:52 - Optional's force unwrapping operator
let value: Int? = nil print(value!) // Fatal error: Unexpectedly found nil while unwrapping an Optional value -
1:58 - Unsafe force-unwrapping
let value: String? = "Hello" print(value.unsafelyUnwrapped) // Hello -
2:25 - Invalid use of unsafe force-unwrapping
let value: String? = nil print(value.unsafelyUnwrapped) // ?! -
4:23 - Invalid use of unsafe force-unwrapping
let value: String? = nil print(value.unsafelyUnwrapped) // Guaranteed fatal error in debug builds -
7:37 - Manual memory management
let ptr = UnsafeMutablePointer<Int>.allocate(capacity: 1) ptr.initialize(to: 42) print(ptr.pointee) // 42 ptr.deallocate() ptr.pointee = 23 // UNDEFINED BEHAVIOR -
10:04 - Passing an array of integers to a C function (1)
void process_integers(const int *start, size_t count); -
10:08 - Passing an array of integers to a C function (2)
func process_integers(_ start: UnsafePointer<CInt>!, _ count: Int) -
10:17 - Passing an array of integers to a C function (3)
let start = UnsafeMutablePointer<CInt>.allocate(capacity: 4) start.initialize(to: 0) (start + 1).initialize(to: 2) (start + 2).initialize(to: 4) (start + 3).initialize(to: 6) process_integers(start, 4) start.deinitialize(count: 4) start.deallocate() -
12:33 - Unsafe buffer pointer types
UnsafeBufferPointer<Element> UnsafeMutableBufferPointer<Element> UnsafeRawBufferPointer UnsafeMutableRawBufferPointer -
13:28 - Accessing contiguous collection storage
Sequence.withContiguousStorageIfAvailable(_:) MutableCollection.withContiguousMutableStorageIfAvailable(_:) String.withCString(_:) String.withUTF8(_:) Array.withUnsafeBytes(_:) Array.withUnsafeBufferPointer(_:) Array.withUnsafeMutableBytes(_:) Array.withUnsafeMutableBufferPointer(_:) -
13:39 - Temporary pointers to Swift values
withUnsafePointer(to:_:) withUnsafeMutablePointer(to:_:) withUnsafeBytes(of:_:) withUnsafeMutableBytes(of:_:) -
13:48 - Passing an array of integers to a C function (4)
let values: [CInt] = [0, 2, 4, 6] values.withUnsafeBufferPointer { buffer in print_integers(buffer.baseAddress!, buffer.count) } -
14:25 - Passing an array of integers to a C function (5)
let values: [CInt] = [0, 2, 4, 6] print_integers(values, values.count) -
15:36 - Advanced C interoperability
func sysctl( _ name: UnsafeMutablePointer<CInt>!, _ namelen: CUnsignedInt, _ oldp: UnsafeMutableRawPointer!, _ oldlenp: UnsafeMutablePointer<Int>!, _ newp: UnsafeMutableRawPointer!, _ newlen: Int ) -> CInt -
16:32 - Advanced C interoperability
import Darwin func cachelineSize() -> Int { var query = [CTL_HW, HW_CACHELINE] var result: CInt = 0 var resultSize = MemoryLayout<CInt>.size let r = sysctl(&query, CUnsignedInt(query.count), &result, &resultSize, nil, 0) precondition(r == 0, "Cannot query cache line size") precondition(resultSize == MemoryLayout<CInt>.size) return Int(result) } print(cachelineSize()) // 64 -
18:18 - Advanced C interoperability
import Darwin func cachelineSize() -> Int { var query = [CTL_HW, HW_CACHELINE] return query.withUnsafeMutableBufferPointer { buffer in var result: CInt = 0 withUnsafeMutablePointer(to: &result) { resultptr in var resultSize = MemoryLayout<CInt>.size let r = withUnsafeMutablePointer(to: &resultSize) { sizeptr in sysctl(buffer.baseAddress, CUnsignedInt(buffer.count), resultptr, sizeptr, nil, 0) } precondition(r == 0, "Cannot query cache line size") precondition(resultSize == MemoryLayout<CInt>.size) } return Int(result) } } print(cachelineSize()) // 64 -
18:30 - Advanced C interoperability
import Darwin func cachelineSize() -> Int { var query = [CTL_HW, HW_CACHELINE] var result: CInt = 0 var resultSize = MemoryLayout<CInt>.size let r = sysctl(&query, CUnsignedInt(query.count), &result, &resultSize, nil, 0) precondition(r == 0, "Cannot query cache line size") precondition(resultSize == MemoryLayout<CInt>.size) return Int(result) } print(cachelineSize()) // 64 -
18:48 - Closure-based vs. implicit pointers
var value = 42 withUnsafeMutablePointer(to: &value) { p in p.pointee += 1 } print(value) // 43 -
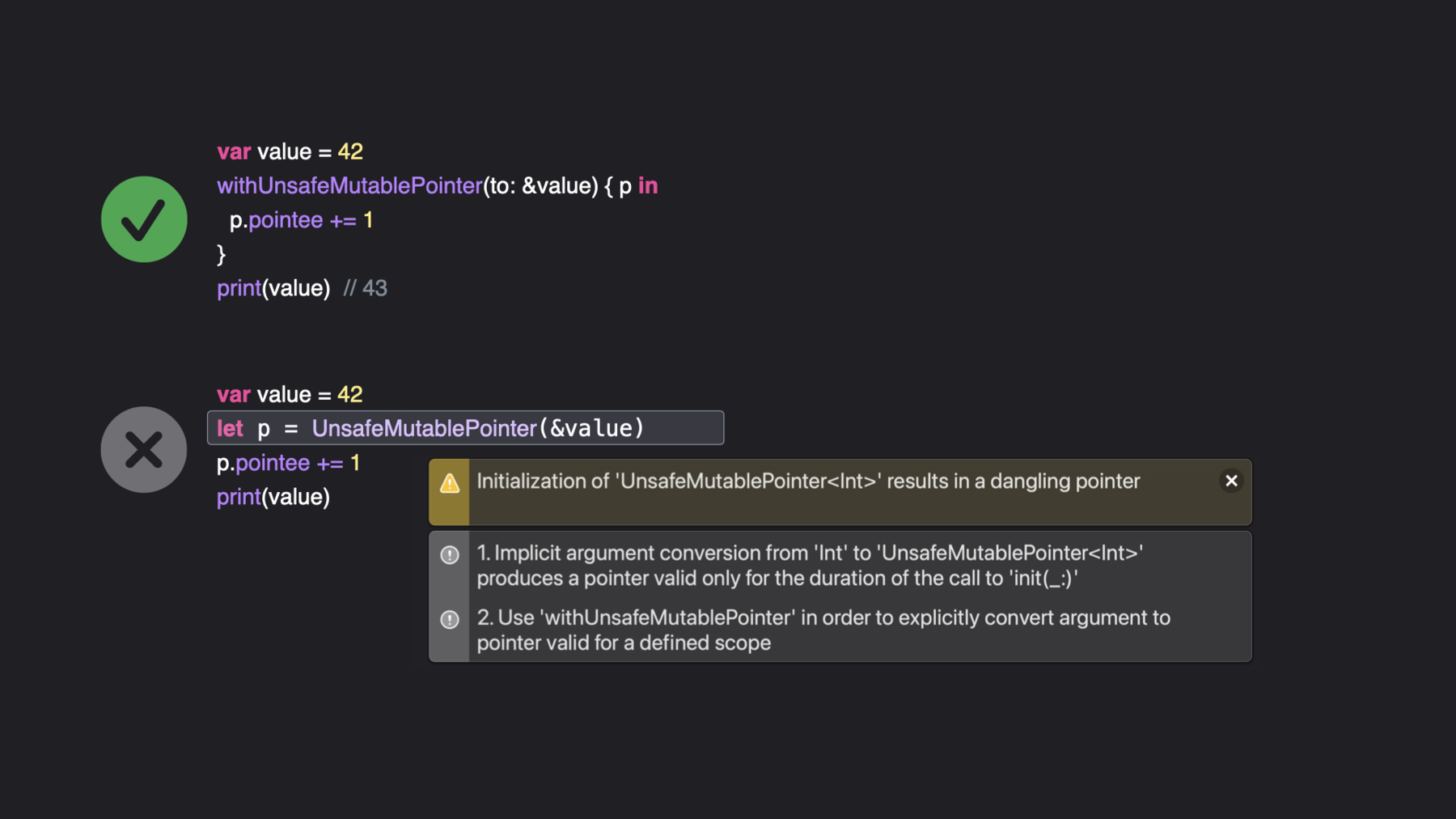
19:19 - Closure-based vs. implicit pointers
var value = 42 withUnsafeMutablePointer(to: &value) { p in p.pointee += 1 } print(value) // 43 var value2 = 42 let p = UnsafeMutablePointer(&value2) // BROKEN -- dangling pointer! p.pointee += 1 print(value2) -
19:43 - Initializing contiguous collection storage
Array.init(unsafeUninitializedCapacity:initializingWith:) String.init(unsafeUninitializedCapacity:initializingUTF8With:) -
20:02 - Initializing a String value using a C function
import Darwin func kernelVersion() -> String { var query = [CTL_KERN, KERN_VERSION] var length = 0 let r = sysctl(&query, 2, nil, &length, nil, 0) precondition(r == 0, "Error retrieving kern.version") return String(unsafeUninitializedCapacity: length) { buffer in var length = buffer.count let r = sysctl(&query, 2, buffer.baseAddress, &length, nil, 0) precondition(r == 0, "Error retrieving kern.version") precondition(length > 0 && length <= buffer.count) precondition(buffer[length - 1] == 0) return length - 1 } } print(kernelVersion()) // Darwin Kernel Version 19.5.0: Thu Apr 30 18:25:59 PDT 2020; root:xnu-6153.121.1~7/RELEASE_X86_64
-