-
Detect people, faces, and poses using Vision
Discover the latest updates to the Vision framework to help your apps detect people, faces, and poses. Meet the Person Segmentation API, which helps your app separate people in images from their surroundings, and explore the latest contiguous metrics for tracking pitch, yaw, and the roll of the human head. And learn how these capabilities can be combined with other APIs like Core Image to deliver anything from simple virtual backgrounds to rich offline compositing in an image-editing app.
To get the most out of this session, we recommend watching “Detect Body and Hand Pose with Vision” from WWDC20 and “Understanding Images in Vision Framework” from WWDC19.
To learn even more about people analysis, see “Detect Body and Hand Pose with Vision” from WWDC20 and “Understanding Images in Vision Framework” from WWDC19.Resources
Related Videos
WWDC22
WWDC21
WWDC20
WWDC19
-
Search this video…
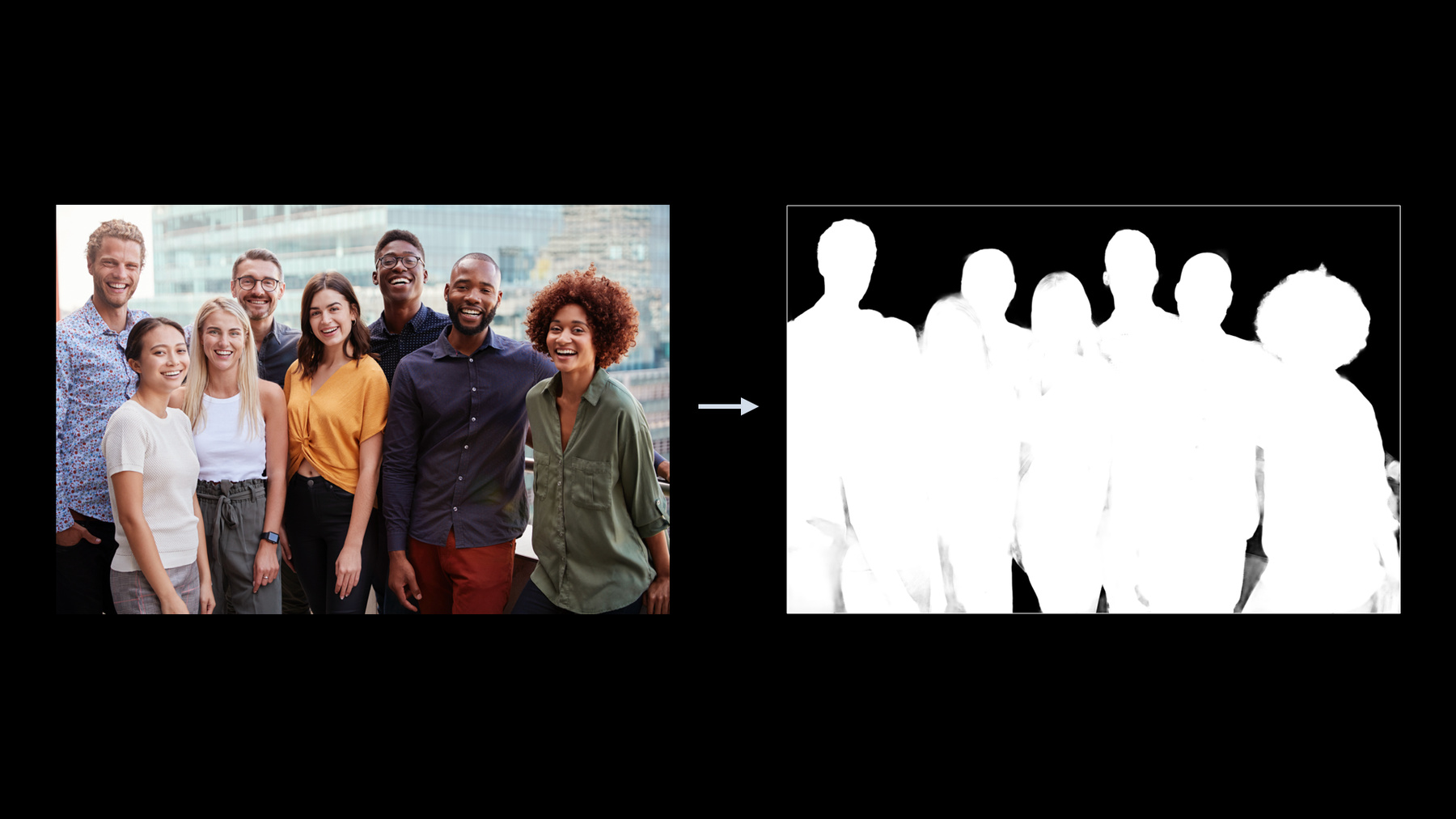
♪ Bass music playing ♪ ♪ Sergey Kamensky: Hello, everybody and welcome to WWDC. My name is Sergey Kamensky and I'm a software engineer in Vision framework team. The topic of today's session is to show how Vision framework can help with people analysis. Our agenda today consists of two main items. First we're going to have an overview of people analysis technology in Vision framework. While doing that, we will be specifically focusing on the new additions. And second, we're going to have the in-depth review of the new person segmentation feature. Let's start with people analysis technology first. The cornerstone of people analysis in Vision is person face analysis. Since the inception of Vision framework, we've been adding and enhancing human face analysis capabilities. We currently offer face detection, face landmarks detection, and face capture quality detection. Face detection functionality in Vision framework is exposed by the means of DetectFaceRectanglesRequest. Our face detector offers high precision and recall metrics, it can find faces with arbitrary orientation, different sizes, and also partially occluded. So far we have supported occlusions like glasses and hats. Now we are upgrading our face detector to revision number three which, in addition to improving all existing great qualities, can now also detect faces covered by masks. The main function of our face detector is of course to find face bounding box, but it can also detect face pose metrics. Previously, we have provided roll and yaw metrics only. Most metrics are reported in radians and their values are returned in discrete bins. With the new revision introduction, we're also adding a pitch metric and thus completing the full picture. But we didn't stop there. We're also making all three metrics reported in continuous space. All face pose metrics are returned as property of our FaceObservation object, which is the result of executing the DetectFaceRectanglesRequest. Let's look at the demo app that is designed to show face pose detection functionality. The app processes camera feed by running Vision face detector and presents face pose metrics to the user after converting the results from radians to degrees. For better tracking of the metric changes, the app uses red color gradient to show when face pose metrics increase in positive direction and blue color gradient to show when the metrics increase in negative direction. In both cases, the lighter the color is, the closer the metric is to the zero position. The zero position for each metric is what you would call a neutral position of a human head, when the person is looking straight -- just like this. As we already discussed, we have three face pose metrics: roll, yaw, and pitch. These terms come from flight dynamics and they describe aircraft principle axes with respect to the aircraft's center of gravity. The same terms have been adopted to describe human head pose as well. When applied to head pose -- or as we also call it, face pose -- they track human head movement as following. Roll is tracking head movement in this direction. When I'm going from the most negative to the most positive values of roll, you can see that the background color changes from dark blue to light blue, neutral, then light red, and finally dark red. Similar color changes are happening with the yaw metric, which is tracking the angle when the head is turning right or left. And finally, the pitch metric is tracking my head movement when my head is nodding up or down. Here you can see again similar color changes when I'm going from the most negative to the most positive end of the spectrum. Face landmarks detection is another important function of our face analysis suite. Face landmarks detection is offered by means of DetectFaceLandmarksRequest, and the latest revision is revision number three. This revision offers 76-point constellation to better represent major face regions and also provide accurate pupil detection. Face analysis suite also includes face capture quality detection. This holistic measure takes into account attributes like human face expressions, lighting, occlusions, blur, focusing, et cetera. It is exposed via DetectFaceCaptureQualityRequest API and the latest revision of this request is revision number two. It is important to remember that face capture quality is a comparative measure of the same subject. This feature works great, for example, to pick the best photo out of the photo burst series or to pick the best photo to represent a person in the photo library. This feature is not designed to compare faces of different people. Human body analysis is another big section of the people analysis technology offered by Vision framework. Vision provides several functions in this area, which include human body detection, human pose detection, and last but not least, human hand pose detection. First let's take a look at the human body detection. This function is offered via DetectHumanRectanglesRequest, and it currently detects human upper body only. We are adding new functionality to this request, and therefore upgrading this revision to revision number two. With the new revision, in addition to the upper-body detection, we also offer a full-body detection. The choice between the upper-body and the full-body detection is controlled via the new upperBodyOnly property of the DetectHumanRectanglesRequest. The default value for this property is set to true to maintain backwards compatibility. Human body pose detection is offered in Vision framework via DetectHumanBodyPoseRequest. Processing this request provides a collection of human body joint locations. Revision number one is the latest and the only available revision of this request. Vision framework also offers human hand pose detection as DetectHumanHandPoseRequest. Similar to human body pose detection, processing of the hand pose request returns a collection of human hand joint locations. We're upgrading functionality of this request by adding an important property to the resulting observation, hand chirality. The new chirality property of the HumanHandPoseObservation will contain information whether the detected hand was left or right. If you want to learn more details about hand pose detection, I recommend watching the "Classify hand poses and actions with Create ML" session. This concludes our overview of the new upgrades to the people analysis technology suite. It is time now to move to the second topic of our session, which is person segmentation. What is person segmentation? In very simple terms, it's the ability to separate people from the scene. There are numerous applications of the person segmentation technology nowadays. You are all familiar, for example, with virtual background feature on video conferencing apps. It's also used in live sport analysis, autonomous driving, and many more places. Person segmentation also powers our famous Portrait mode. Person segmentation in Vision framework is a feature designed to work with a single frame. You can use it in streaming pipeline, and it's also suitable for the offline processing. This feature is supported on multiple platforms like macOS, iOS, iPadOS, and tvOS. Vision framework implements semantic person segmentation, which means that it will return a single mask for all people in the frame.
Vision API for person segmentation is implemented by means of GeneratePersonSegmentationRequest, This is a stateful request. As opposed to traditional requests in Vision framework, the stateful request objects are reused throughout the entire sequence of frames. In our particular case, using request object helps with smoothing temporal changes between the frames in fast-quality level model. Let's take a look at the Person Segmentation API offered by Vision framework. This API follows an already familiar and established pattern. Create a request, create a request handler, process your request with the request handler, and finally, review the results. Default initialization of GeneratePersonSegmentationRequest object is equivalent to setting revision, qualityLevel, and outputPixelFormat properties to their default values. Let's review all properties one by one. First is the revision property. Here we set the revision to revision number one. This is the default and the only available revision, since we're dealing with the new request type. Even though there is technically no choice here today, we always recommend to set explicitly to guarantee deterministic behavior in the future. This is because if new revisions are introduced, the default will also change to represent the latest available revision. Second is the qualityLevel property. Vision API offers three different levels: accurate, which is also the default one; balanced; and fast. As far as the use cases go, we recommend using accurate level for computational photography. This is the use case where you would like to achieve the highest possible quality and are typically not limited in time. Using similar logic, balanced level is recommended for video frame-by-frame segmentation and fast for streaming processing. The third property is the output mask format. We are going to review the resulting mask in details, but here I would like to mention that, as a client, you can specify which format the resulting mask will be returned in. There are three choices here: unsigned 8-bit integer mask with a typical 0 to 255 quantization range, and two floating point mask formats -- one with 32-bit full precision and another with 16-bit half precision. The 16-bit half precision is intended to provide you with a reduced memory floating point format that can be inserted directly into further GPU-based processing with Metal. So far we have learned how to create, configure, and execute our person segmentation request. It is time now to look at the results. The result of processing person segmentation request come in form of PixelBufferObservation object. PixelBufferObservation derives from observation and it adds an important pixelBuffer property. The actual CVPixelBuffer object stored in this property has the same pixel format as our person segmentation request was configured with. Processing of person segmentation request will produce a segmentation mask. Let's look at the original image and three different quality level masks generated by executing person segmentation request. Fast, balanced, and accurate. Let's zoom in to look at the details of each mask. As expected, when we go from fast to balanced and eventually to accurate, the quality of the mask increases and we'll start seeing more and more details. Now let's examine the different mask levels as a function of quality versus performance. When we move from fast to balanced, and eventually to accurate, the quality of the mask goes up but so does the resource usage. The dynamic range, mask resolution, memory consumption, processing time all go up when the mask quality increases. This represents a trade-off between the quality of the segmentation mask and the resource consumption needed to compute the mask. So you already know everything about mask generation and their properties. What can you actually do with the masks? Let's start with three images. The input image, the segmentation mask that was obtained by processing the input image, and the background image. What we would like to do is to replace the background in the original image in the area outside of the mask region with the background from a different image. When you execute such blending operation, we end up with the young man in the original image being transported from the beach promenade to the forest. How does this blending sequence look like in the code? First let's assume we have done all relevant processing and already have our three images: the input image, the mask, and the background. Now we need to scale both the mask and the background to the size of the original image. Then we will create and initialize the Core Image blending filter. You probably noticed that I created my blending filter with the red mask. This is because when CIImage is initialized with one component PixelBuffer -- as all our masks are -- it creates an object with the red channel by default. Finally, we perform the blending operation to get our results. Let's take a look how we can use person segmentation feature in Vision framework. Our second demo app, which is available for downloading, combines face pose metric detection with the new person segmentation capability. The app processes camera feed by running face detection and person segmentation. Then that takes up the end segmentation mask and uses it to replace the background in the area outside of the mask pixels with a different color. The decision of what background color to use comes from the combination of values for roll, yaw, and pitch at any given point in time. I'm currently located in a room with a table and chairs, and the demo app shows my segmented silhouette over the new background, which is the color mix corresponding to my head position. Let's see if it tracks roll, yaw, and pitch changes. When I turn my head like this, roll is a major contributor to the background color mix decision. When I turn my head left and right, yaw becomes the major contributor. And finally, nodding my head up and down makes pitch the major contributor. Vision framework is not the only place that offers person segmentation API. There are several other frameworks that offer similar functionality powered by the same technology. Let's take a brief look at each one of them. First is the AVFoundation. AVFoundation can return a person segmentation mask in some of the newer-generation devices during photo capture session. The segmentation mask is returned via PortraitEffectsMatte property of AVCapturePhoto. In order to get it, you will first need to check if it's supported; and if it is, enable the delivery of it. The second framework that offers person segmentation API is ARKit. This functionality is supported on A12 Bionic and later devices, and is generated when processing camera feed. The segmentation mask is returned via segmentationBuffer property of ARFrame. Before attempting to retrieve it, you need to check if it's supported by examining supportsFrameSemantics property of ARWorldTrackingConfiguration class. The third framework is Core Image. Core Image offers a thin wrapper on top of Vision person segmentation API, so you can perform the entire use case within the Core Image domain. Let's take a look now at how person segmentation can be implemented using Core Image API. We will start with logging an image to perform segmentation on. Then we will create a person segmentation CIFilter, assign an inputImage to it, and execute the filter to get our segmentation mask. We have just reviewed multiple versions of person segmentation APIs and Apple SDKs. Let's summarize to see where each one could be used. AVFoundation is available on some of iOS devices with AVCaptureSession. If you have a capture session running, this will be your choice. If you're developing an ARKit app, you should already have an AR session where you can get your segmentation mask from. In this case, ARKit API is the recommended one to use. Vision API is available on multiple platforms for online and offline single-frame processing. And finally, Core Image offers a thin wrapper around Vision API, which is a convenient option if you want to stay within the Core Image domain. As any algorithm, person segmentation has its best practices -- or in other words, the set of conditions where it works best. If you're planning to use person segmentation feature, your app will perform better if you try to follow these rules. First, you should try to segment up to four people in the scene where all people are mostly visible, while maybe with natural occlusions. Second, the height of each person should be at least half of the image height, ideally with good contrast compared to the background. And third, we also recommend you to avoid ambiguities like statues, pictures of people, people at far distance. This concludes our session. Let's take a brief look at what we have learned today. First, we had an overview of the person analysis technology in Vision framework while focusing on the upgrades like masked face detection, adding face pitch metric, and making all face pose metrics reported in continuous space. We also introduced new hand chirality metric to the human hand pose detection. In the second part, we took a deep dive into the new person segmentation API added to Vision framework. We also looked into other APIs offering similar functionality and provided the guidance where each one could be used. I really hope that by watching this session, you have learned new tools for developing your apps and are really eager to try them right away. Before we finish today, I would like to thank you for watching, wish you good luck, and have a great rest of the WWDC. ♪
-
-
8:13 - Get segmentation mask from an image
// Create request let request = VNGeneratePersonSegmentationRequest() // Create request handler let requestHandler = VNImageRequestHandler(url: imageURL, options: options) // Process request try requestHandler.perform([request]) // Review results let mask = request.results!.first! let maskBuffer = mask.pixelBuffer -
8:33 - Configuring the segmentation request
let request = VNGeneratePersonSegmentationRequest() request.revision = VNGeneratePersonSegmentationRequestRevision1 request.qualityLevel = VNGeneratePersonSegmentationRequest.QualityLevel.accurate request.outputPixelFormat = kCVPixelFormatType_OneComponent8 -
12:24 - Applying a segmentation mask
let input = CIImage?(contentsOf: imageUrl)! let mask = CIImage(cvPixelBuffer: maskBuffer) let background = CIImage?(contentsOf: backgroundImageUrl)! let maskScaleX = input.extent.width / mask.extent.width let maskScaleY = input.extent.height / mask.extent.height let maskScaled = mask.transformed(by: __CGAffineTransformMake( maskScaleX, 0, 0, maskScaleY, 0, 0)) let backgroundScaleX = input.extent.width / background.extent.width let backgroundScaleY = input.extent.height / background.extent.height let backgroundScaled = background.transformed(by: __CGAffineTransformMake( backgroundScaleX, 0, 0, backgroundScaleY, 0, 0)) let blendFilter = CIFilter.blendWithRedMask() blendFilter.inputImage = input blendFilter.backgroundImage = backgroundScaled blendFilter.maskImage = maskScaled let blendedImage = blendFilter.outputImage -
14:37 - Segmentation from AVCapture
private let photoOutput = AVCapturePhotoOutput() … if self.photoOutput.isPortraitEffectsMatteDeliverySupported { self.photoOutput.isPortraitEffectsMatteDeliveryEnabled = true } open class AVCapturePhoto { … var portraitEffectsMatte: AVPortraitEffectsMatte? { get } // nil if no people in the scene … } -
14:58 - Segmentation in ARKit
if ARWorldTrackingConfiguration.supportsFrameSemantics(.personSegmentationWithDepth) { // Proceed with getting Person Segmentation Mask … } open class ARFrame { … var segmentationBuffer: CVPixelBuffer? { get } … } -
15:31 - Segmentation in CoreImage
let input = CIImage?(contentsOf: imageUrl)! let segmentationFilter = CIFilter.personSegmentation() segmentationFilter.inputImage = input let mask = segmentationFilter.outputImage
-