-
Discover geometry-aware audio with the Physical Audio Spatialization Engine (PHASE)
Explore how geometry-aware audio can help you build complex, interactive, and immersive audio scenes for your apps and games. Meet PHASE, Apple's spatial audio API, and learn how the Physical Audio Spatialization Engine (PHASE) keeps the sound aligned with your experience at all times — helping you create spatial soundscapes and scenes during the development process, rather than waiting until post production. We'll take you through an overview of the API and its classes, including Sources, Listeners, Acoustic Geometry, and Materials, and introduce the concept of Spatial Modeling. We'll also show you how to quickly combine PHASE's basic building blocks to start building an integrated audio experience for your app or game.
Resources
Related Videos
WWDC23
WWDC22
-
Search this video…
Hello, my name is Bharath, and I am from Apple's Core Audio team. And today, and I would like to talk to you about geometry-aware audio with PHASE. We will talk about why you would want to use the new PHASE framework. We will introduce you to some of the features the framework offers. Then, I will hand it over to my colleague, David Thall, to take you through concepts in some depth and sample use cases with this API. Let's begin.
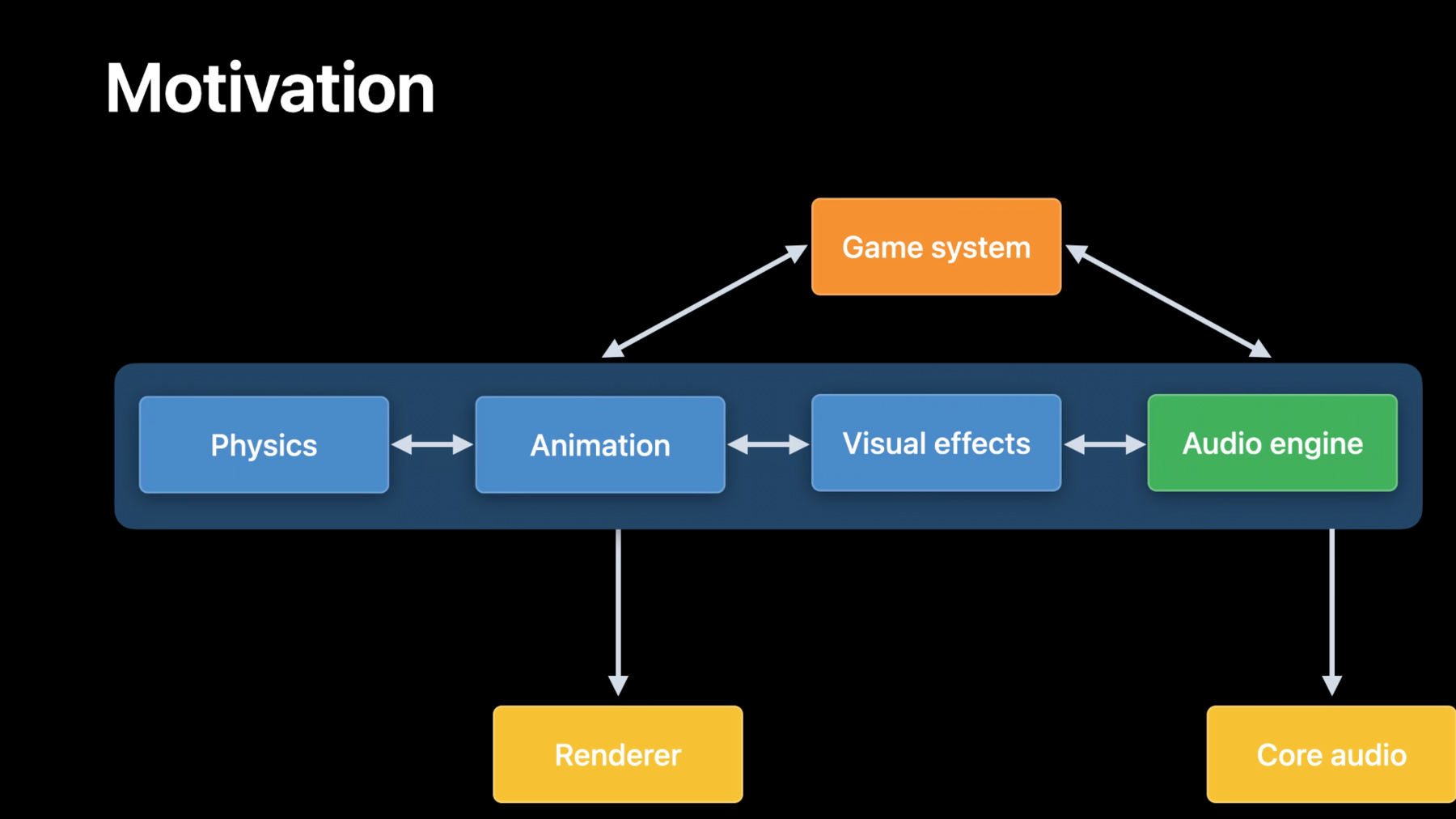
Audio is a critical aspect of any gaming experience. Spatial audio on headphones takes the overall gameplay to the next level and makes you feel more involved. In games today, various subsystems of the engine like physics, animation, visual effects, et cetera, all communicate with each other and move the game flow or storyline forward based on the player's actions. However, the audio subsystem is generally managed and driven separately from the rest. They sometimes are also authored through middleware that isn't always aware of the simulation.
Audio assets are post-produced, pre-baked, hand-tuned to tell an audio story that matches the game visuals. As visuals evolve, audio system, sound design, and associated assets needs to be regenerated to keep audio experience cohesive on a wide range of platforms. This iterative development process needs to be accounted for during the game development. This typically leads to audio experiences lagging the visual side of the gameplay.
To provide a better game audio experience, we want to bring the audio system closer to other subsystems. We also want to make it easier for you to write applications that can provide a consistent spatial audio experience on all these supported devices.
Let us now take you through the new audio framework PHASE and its features. PHASE is a new framework that will enable you to provide geometry information to the audio engine, help you build a sound-design friendly, event-driven audio playback system, enable you to write applications that can automatically provide a consistent spatial audio experience across all supported devices and can be integrated with existing authoring solutions and pipelines. Before we jump into learning more about PHASE, let us review a commonly used game audio workflow. Here's an example outdoor scene with a listener, a sound source, a creek flowing and an occluder, a barn.
Occluders are objects in the scene that could dampen the sound between a source and the listener. Typically, you would place multiple point sources along an area. As the listener moves, you have to use various techniques such as ray tracing to determine the proper filtering and mix ratio between the point sources and manually blend between them to provide a good audio experience. During the natural course of the game development, if visual scenes change, for example, the barn in the example scene, you have to update and hand-tune the audio experience to match the visual scene change. Imagine you can build applications where audio sources are not points you need to manage and mix based on the scene but rather as sound emanating over an area or volume that the audio system can automatically manage for you. PHASE does exactly that. Introducing volumetric sources. The new framework provides API that allows you to pass sound sources as geometric shapes to the underlying audio engine. In addition to volumetric sound sources, you can also pass occluders in the scene as geometric shapes. You can also choose acoustic material properties from a set of presets and attach them to occluders. PHASE framework also allows you to set medium propagation and source directivity for point sources as required by your application. We are looking at an outdoor scene as an example here. However, if your application has indoor scenes, you can choose early reflections and late reverberation properties from a library of presets. Once you tell the framework where various sound sources, occluders, and the listener are, PHASE will help with the heavy lifting and model the occlusion and spreading effects of various sound sources in the scene for you. Now that your application's audio system is geometry aware, it can adapt to visual scene changes much quicker as the game development evolves.
In addition to geometry awareness, PHASE also provides an event-based interactive playback system. Sound events are basic units for describing audio playback events in PHASE. They encapsulate the selection, blending, and playback of audio assets. Sound events can range from simple events like one-shot playback, looping, to complex sequences organized as a tree that can blend or switch between subtrees of playback events. Let us take a simple example of playing footsteps. Here we have a random node that will automatically choose between three different sounds of a footstep on gravel. We can have another sound event for cloth rustle. Both event trees can be grafted onto another tree, "near" in this example, to play back a mix of cloth rustle and footsteps sounds. We can have another tree, "far" in this example, to play a different set of sounds when the character is at a distance. The mix of near and far trees can be now controlled by distance based on the gameplay. You can add more event trees like footstep on snow or grass, for example, and build a complex sequence of playback events that can be triggered by user interaction or by subsystems like physics and animation.
With PHASE, sounds can be played either to a simple channel configuration or in a 3D space with orientation and position, or as ambient beds where the sounds have orientation but no position. The underlying engine is built upon our spatial audio rendering capabilities already available on supported iOS, macOS devices, and also Air Pods family of headphones. This enables you to build applications that provide a consistent spatial audio experience on all the supported devices automatically. Next, I would like to invite David Thall to dive deeper into PHASE and talk more about the concepts and the API for some example use cases. Hi, everyone, my name is David Thall, and I'm System Architect and Development Lead on PHASE. Today I'm going to walk you through the PHASE API. In this section, I'll introduce you to the general concepts. Following this, I'll run through some sample use cases to get you started. The PHASE API can be separated into three main concepts. The engine manages assets. Nodes control playback. And mixers control spatialization. The PHASE engine can be broken down into three main sections. The asset registry, scene graph, and rendering state. Throughout the engine life cycle you'll register and unregister assets with the engine. Today, PHASE supports registering sound assets and sound event assets. Sound assets can be loaded directly from an audio file or packed and embedded as raw audio data in your own assets and loaded directly into the engine. Sound event assets are a collection of one or more hierarchical nodes that control sound playback and downstream mixers that control spatialization. The scene graph is a hierarchy of objects that take part in the simulation. This includes listeners, sources, and occluders. A listener is an object that represents the location in space from which you hear the simulation. A source is an object that represents where sound originates. As Bharath mentioned earlier, PHASE supports both point sources and volumetric sources. An occluder is an object that represents the geometry in the simulation that affects sound transmission as it moves through the environment. Occluders are also assigned materials that affect how they absorb and transmit sound. PHASE comes with a library of material presets that can be assigned to occluders to simulate everything from cardboard boxes to glass windows to brick walls. As you add objects to your scene, you'll organize them into a hierarchy and attach them to the engine's root object, either directly or indirectly. This will ensure they take part in the simulation from frame to frame. The rendering state manages playing sound events and audio IO. When you first create the engine, audio IO is disabled. This allows you to register your assets, build your scene graph, construct sound events, and perform other engine operations, all without having to run audio IO. Once you're ready to play back sound events, you can start the engine, which will internally start the audio IO. Likewise, when you're finished playing back sound events, you can stop the engine. This will stop the audio IO and stop any playing sound events. Nodes in PHASE control playback of audio content. Nodes are a hierarchical collection of objects that either generate or control audio playback. Generator nodes produce audio. They are always leaf nodes in a node hierarchy. Control nodes set the logic for how generators are selected, mixed and parameterized before spatialization. Control nodes are always parent nodes and can be organized into hierarchies for complex sound design scenarios. A sampler node is a type of generator node. Samplers play back registered sound assets. Once constructed, you can set some basic properties on the sampler node to get it to play back correctly. The playback mode determines how the audio file will be played. If you set the playback mode to OneShot, the audio file will play once and automatically stop itself. This can be used in "fire-and-forget" scenarios, such as triggering sound effects. If you set the playback mode to looping, the audio file will play indefinitely, until you explicitly stop the sampler. The cull option tells PHASE what to do when the sound becomes inaudible. If you set the cull option to terminate, the sound will automatically stop itself when it becomes inaudible. If you set the cull option to sleep, the sound will stop rendering when it becomes inaudible and start rendering again when it becomes audible. This makes it so you don't have to manually start and stop sounds when they are culled by the engine. The calibration level sets the real-world level of the sound in decibels SPL. PHASE also supports four types of control nodes. These include random, switch, blend and container nodes. The random node selects one of its children according to a weighted random choice. For example, in this case, the left sampler has 4:1 odds over the right sampler of being selected the next time the sound event is triggered. The switch node switches between its children based on a parameter name. For example, you could change the terrain switch from "creaky wood" to "soft gravel." The next time the sound event is triggered, it'll select the sampler that matches the parameter name. The blend node blends between its children based on a parameter value. For example, you could assign a wetness parameter to a blend node, which could blend between a loud footstep and quiet splash on the dry end and a quiet footstep and loud splash on the wet end. The container node plays all its children at once. For example, you could have one sampler that plays back a footstep and another sampler that plays back the sound of clothing, like the sound of a ruffling Gor-Tex jacket. Every time the container is triggered, both samplers will play back at the same time.
Mixers in PHASE control spatialization of audio content. PHASE currently supports channel, ambient, and spatial mixers. Channel mixers render audio without spatialization and environmental effects. Use channel mixers for regular stem-based content that needs to be rendered directly to the output device, such as stereo music or center channel narrative dialogue. Ambient mixers render audio with externalization but without distance modeling or environmental effects. As the listener rotates their head, the sound will continue to come from the same relative location in space. Use ambient mixers for multichannel content that isn't being simulated in the environment but should still sound like it's coming from somewhere out in space, for example, a background of crickets chirping in a large forest. Spatial mixers perform full spatialization. As the sound source moves relative to the listener, you'll hear changes in perceived location, level, and frequency response based on panning, distance modeling, and directivity modeling algorithms. In addition to this, geometry-aware environmental effects are applied to the path between the source and listener. If you're wearing headphones, you'll also get externalization through the application of binaural filters. Use spatial mixers for sounds that should take part in the full environmental simulation. Spatial mixers support two unique distance modeling algorithms. You can set up standard geometric spreading loss for natural attenuation over distance. You can also increase or decrease the effect to your liking. For example, lowering the value could be useful if you wanted to boom mic a conversation at a distance. On the other end of the spectrum, you can add full piecewise curved segments of attenuation over distance. For example, you could construct a set of segments with natural distance attenuation at the start and end of the range, but decrease the attenuation in the middle to keep important dialogue audible at increased distances. For point sources, spatial mixers support two different directivity modeling algorithms. You can add cardioid directivity modeling to your spatial mix. Using some simple modifications, you could model a human speaker with a cardioid directivity pattern or the sound of an acoustic stringed instrument with a hyper-cardioid pattern. You can also add cone directivity modeling. This classic mode allows you to limit directivity filtering to within a specific range of rotation. Spatial mixers also support geometry-aware environmental effects based on a spatial pipeline. The spatial pipeline selects environmental effects to enable or disable, as well as the send levels to each. PHASE currently supports direct path transmission, early reflections, and late reverb. Direct path transmission renders the direct and occluded paths between the source and listener. Note that with occluded sound, some energy is absorbed by materials, while other energy is transmitted to the other side of the object. Early reflections provide both intensity modification and coloration to the direct path. These are usually built from the specular reflections off the walls and floor. In larger spaces, they also add noticeable echoes to the experience. Late reverb provides the sound of the environment. It's a dense build-up of the diffuse scattered energy that coalesces into the final audible representation of the space. In addition to providing cues for room size and shape, it's also responsible for giving you a sense of envelopment. Now that I've reviewed the concepts behind the PHASE engine, nodes and mixers, it's time to bring these concepts together with some sample use cases. In this section, I'll walk you through playing an audio file, building a spatial audio experience, and building a behavioral sound event. These three key areas will give you a wide overview of the capabilities of PHASE, with a gentle introduction at the beginning and a deep dive into the more interesting capabilities toward the middle and end. To kick things off, I'll show you how to play an audio file. First, let's create a PHASE engine instance. Next, I'll retrieve the URL to an audio file and register the sound asset with PHASE. I'll give it the name "drums" so I can refer to it later. Here I'll create an engine and register a sound asset in code. First, I'll create a PHASE engine instance in automatic update mode. This is the preferred mode to get things up and running, so I'm using it here for demoing simple playback. Note that when a game requires more precise synchronization with the frame update, manual mode is the way to go. Check out the documentation for more details. Next, I'll retrieve the URL to an audio file stored in the application bundle. This is a mono 24bit, 48kHz WAV file with a prepared drum loop sample. When registering the sound asset with the engine, I'll provide some additional arguments. I'll give the sound asset a unique name so I can refer to it later. I'll specify that the audio data within the sound asset should be pre-loaded into resident memory, as opposed to streaming it into memory in real time. This should be fine since the drum loop is fairly short, and I might want to play it back several times in short succession. I'm also choosing to normalize the sound asset for calibrated loudness on the output device. In general, it's advised to normalize the input. This'll make it easier to mix the content once we assign it to a sampler and set its target output level. Now that I've registered a sound asset with the engine, I'll construct a sound event asset. First I'll create a channel mixer from a channel layout. Then I'll create a sampler node. The sampler node takes the name of the registered sound asset and a reference to the downstream channel mixer. Next I'll set some basic properties on the sampler node to get it to play back correctly. The playback mode will set whether or not the sampler will loop the audio file, and the calibration level will set the perceived loudness of the sampler within the mix. Now that I've hooked the output of the sampler node to the input of the channel mixer and set some basic parameters, it's time to register the sound event asset with the engine. In this case, I'll register the sound event asset with the name drumEvent, which I'll use to refer to it later. Here I'll register a sound event asset in code. I'll create a channelLayout from a mono ChannelLayoutTag. Then I'll initialize the channel mixer with the mono channelLayout. Next I'll create the sampler node and pass in the name drums, which refers to the mono drum asset I previously registered with the engine. The sampler node will be routed to the downstream channel mixer. I'll set the playbackMode to looping. This will ensure the sound continues to play back until I explicitly stop it from code. I'll set the CalibrationMode to relativeSpl, and the level to 0 decibels. This will ensure a comfortable listening level for the experience. Finally I'll register the soundEventAsset with the engine, passing in the name drumEvent so I can refer to it later when I start creating sound events for playback. Once a sound event asset is registered, I can create an instance and start playback. The first thing I'll do is create a sound event from the registered sound event asset named drumEvent. Now that I have a sound event, I'll go ahead and start the engine. This will start the audio IO so I can listen to the audio feeding the output device. Finally I'll start the sound event. At this point, the loaded sound asset will be played through the sampler, routed to the channel mixer, remapped to the current output format, and played back through the output device. Here I'll start a soundEvent in code. The sound event asset is constructed from the name of the registered sound asset. Here, I'm passing in drumEvent. I'll go ahead and start the engine, which will start the audio IO and start the sound event.
Once I'm finished playing back the sound event, I can clean up the engine. First I'll stop the sound event. Then I'll stop the engine. This will stop the audio IO and stop any playing sound events. Next I'll unregister the sound event asset named drumEvent and unregister the sound asset named drums. Finally I'll destroy the engine. Here I'll do the cleanup in code. First I'll stop the sound event once I'm finished listening to the drum loop. then I'll stop the engine, which will internally stop the audio IO. Next I'll unregister the sound event asset named drumEvent and unregister the sound asset named drums. Finally I'll destroy the engine.
Now that I've covered the basics, I'll show you how to build a simple spatial audio experience in PHASE. We'll cover topics including spatial mixers, volumetric sound sources, and occluders. This first thing I'll do is register a sound event asset with the engine. For this example, I'll start with an engine that already has the drums sound event registered. From here, I'll upgrade the mix to go from simple channel-based playback to full spatialization. The first thing I'll do is construct a spatial pipeline to selectively apply different environmental effects to my sound source. Then I'll create a spatial mixer from the spatial pipeline. Once constructed, I'll set some basic properties on the spatial mixer to get it to play back correctly. In this example, I'll set the distance model to control level attenuation over distance. I'll also set the directivity model to control level attenuation based on the angle between the source relative to the listener. Then I'll create a sampler node. The sampler node takes the name of the registered sound asset and a reference to the downstream spatial mixer. Next I'll set some basic properties on the sampler node to get it to play back correctly. In addition to the playback mode and calibration level, I'll also set the cull option here. This will tell PHASE what to do when the sampler becomes inaudible. Now that I've hooked the output of our sampler node to the input of the spatial mixer and set some basic parameters, it's time to register the sound event asset with the engine. I'll use the same name as before. Here I'll create a sound event asset in code. First I'll create a spatialPipeline to render .directPathTransmission and .lateReverb. I'll also go ahead and set the .lateReverb .sendLevel to control the direct-to-reverberant ratio and choose a .mediumRoom preset for the late reverb simulation. Then I'll create a spatial mixer with the spatialPipeline. Next I'll create a natural-sounding GeometricSpreadingDistanceModel and assign it to the spatial mixer. I'll set the cullDistance to 10 meters. If the source were to go beyond this distance, I'd want to automatically cull it from the mix. And I'll adjust the rolloffFactor a little to de-emphasize the distance attenuation effect. Then I'll create a sampler node and pass it the name "drums," which refers to the mono drum sound asset I previously registered with the engine. I'll set the playbackMode to .looping. I'll set the calibration mode to .relativeSpl, and the level to +12 decibels to increase the output level of the sampler. And I'll set the cullOption to sleep. Finally, I'll register the soundEventAsset with the engine, passing in the name drumEvent so I can refer to it later when I start creating sound events. Now that I have a sound event asset registered with the engine I need to create a scene for the simulation. This involves creating a listener, source, and occluder. In this example, I'll place the occluder between the source and listener. First I'll create a listener. Then I'll set its transform. Once I'm ready to make the listener active within the scene graph, I'll attach it to the engine's root object or one of its children. Here I'll set up the listener in code. First I'll create a listener. Then I'll set its transform. In this example, I'll set the listener to the origin with no rotation. Finally I'll attach the listener to the engine's root object.
Now let's set up a volumetric source. First I'll create a source shape from a mesh. Then I'll create a source from the shape. This inherently constructs a volumetric source. Next I'll set its transform. And once I'm ready to make the source active within the scene graph, I'll attach it to the engine's root object or one of its children. Here I'll set up a volumetric source in code. First I'll create an Icosahedron mesh and scale it to about the size of a HomePod Mini. Then I'll create a shape from the mesh. This shape can be reused to construct multiple instances of a volumetric source. For example, I could place multiple HomePod Minis in the simulation that share the same mesh.
Next I'll create a volumetric source from the shape. Note that I could also create a simple point source by using a version of the initializer that doesn't take a shape as input. Then I'll set its transform. I'll translate the source 2 meters in front of the listener and rotate it back toward the listener so they are facing each other. Finally I'll attach the source to the engine's root object.
Now let's set up an occluder. First I'll create a shape from a mesh.
Then I'll create a cardboard material and assign it to the shape. Now the shape has a geometry and an associated material. Next I'll create an occluder from the shape. Then I'll set its transform. And once I'm ready to make the occluder active within the scene graph, I'll attach it to the engine's root object or one of its children.
Here I'll set up the occluder in code. First I'll create a boxMesh and scale its dimensions accordingly. Then I'll create a shape from the mesh. This shape can be reused to construct multiple instances of an occluder. For example, I can place multiple boxes in the simulation that share the same mesh. Next, I'll create a material from a cardboard box preset and assign the material to the shape.
Next I'll create an occluder from the shape. Then I'll set its transform. I'll translate the occluder 1 meter in front of the listener and rotate it back toward the listener so they are facing each other. This puts the occluder halfway between the source and listener. Finally I'll attach the occluder to the engine's root object.
At this point, I have a scene with an occluder halfway between a source and listener.
Next I'll create a sound event from our registered sound event asset and associate it with the source and listener in the scene graph. When I start the sound event, I'll hear an occluded drum loop playing from a small volumetric source on the opposite side of a cardboard box. Here I'll start the sound event in code. First I'll associate the source and listener with the spatial mixer in the sound event. Then I'll create a soundEvent from the registered soundEvent asset named drumEvent. The rest is the same as before. Make sure the engine is running, then start the sound event. Now that I've covered spatial audio, I'll show you how to build a complex sound event. Sound events can be organized into behavioral hierarchies for interactive sound design. In this section, I'll walk you through consecutive examples that build upon each type of sound event node to create the final sound event. Here we'll model an actor wearing a noisy Gore-Tex jacket walking on different types of terrain with variable surface wetness. First I'll create a sampler node that plays back a footstep on creaky wood. In code, I'll create a sampler node with a registered sound asset named "footstep_wood_clip_1." For this example, this node and all others will play back on a single pre-constructed channel mixer. Now I'll add some randomness. I'll create a random node with two child sampler nodes that play slightly different footstep on creaky wood samples. In code, I'll create two sampler nodes. The first uses a registered sound asset named "footstep_wood_clip_1 and the second uses a registered sound asset named "footstep_wood_clip_2." Then , I'll create a random node and add the sampler nodes as children. Note that a weighting factor is applied to each child node to control the likelihood of that child being chosen over successive iterations. In this case, the first child has twice the chance of being selected over the second child.
Next I'll add a terrain switch. I'll create a switch node and two random nodes as children. In this case, the second random node plays back random footsteps on gravel as opposed to random footsteps on wood. I'll use a terrain parameter to control the switch. In code, I'll create two sampler nodes. The first uses a registered sound asset named "footstep_gravel_clip_1" and the second uses a registered sound asset named "footstep_gravel_clip_2." Then I'll create a random node and add the sampler nodes as children. Next I'll create a terrain parameter. The default value will be "creaky_wood." Then I'll create a switch node that's controlled by the terrain parameter. I'll add two children, the wood random node and gravel random node. If I set the parameter to "creaky_wood," it'll select the wood random node. Likewise, if I set the parameter to "soft_gravel," it'll select the gravel random node.
Next I'll add a wetness blend. I'll create a blend node with a terrain switch node and random splash node as children. The new random splash node plays random splash noises as the actor takes steps, while the terrain switch determines if the actor's feet are walking on creaky wood or soft gravel. The blend between the dry footstep sounds and the splashes is dependent on the wetness parameter, from completely dry--loud footsteps and no splashes-- to completely wet--quiet footsteps and loud splashes. In code, I'll create two sampler nodes. The first uses a registered sound asset named "splash_clip_1" and the second uses a registered sound asset named "splash_clip_2." Then I'll create a random node and add the sampler nodes as children. Next I'll create a wetness parameter. The range will be 0 to 1, and the default value will be 0.5. Note that I can set the parameter to any value and range supported by my game. Then I'll create a blend node that's controlled by the wetness parameter. I'll add two children, the terrain switch node and random splash node. If I set the parameter to 0, I'll only hear dry footsteps on creaky wood or gravel, depending on the terrain. As I increase the wetness from 0 to 1, I'll increase the loudness of splash noises that accompany each footstep, simulating wet terrain.
Finally I'll create a container node with the wetness blend node and a random noisy clothing node as children. The new noisy clothing node plays back the ruffling noises of a Gore-Tex jacket whenever the actor takes a step on changing terrain with variable wetness. With this final node hierarchy in place, I have a complete representation of the actor walking in a scene. Every time the actor takes a step, I'll hear the ruffling of the jacket, plus footsteps on creaky wood or soft gravel, depending on the terrain parameter. In addition to this, I'll hear more or less of the splashes with each footstep, depending on the wetness parameter. In code, I'll create two sampler nodes. The first uses a registered sound asset named "gortex_clip_1" and the second uses a registered sound asset named "gortex_clip_2." Then I'll create a random node and add the sampler nodes as children. Finally I'll create an actor_container node. I'll add two children, the wetness_blend node and noisy_clothing_random node. Together, they represent the complete sound of the actor. In review, we learned how to play an audio file. Following this, we expanded our knowledge by diving headfirst into constructing a simple yet effective spatial audio experience. Here we learned about listeners, volumetric sources, and occluders. Finally, we learned about building behavioral sound events for interactive sound design. Here we learned about grafting random, switch, blend, and container nodes together to form hierarchical, interactive sound events. Taken together, you should now have a broad understanding of the inner workings of PHASE and be able to take a deeper dive into the underlying system components when you're ready to settle in and build your next geometry-aware game audio experience. Thank you. Have a great WWDC21. [upbeat music]
-
-
18:31 - Create an Engine and Register a Sound Asset
// Create an Engine in Automatic Update Mode. let engine = PHASEEngine(updateMode: .automatic) // Retrieve the URL to an Audio File stored in our Application Bundle. let audioFileUrl = Bundle.main.url(forResource: "DrumLoop_24_48_Mono", withExtension: "wav")! // Register the Audio File at the URL. // Name it "drums", load it into resident memory and apply dynamic normalization to prepare it for playback. let soundAsset = try engine.assetRegistry.registerSoundAsset(url: audioFileUrl, identifier: "drums", assetType: .resident, channelLayout: nil, normalizationMode: .dynamic) -
20:47 - Register a Sound Event Asset
// Create a Channel Layout from a Mono Layout Tag. let channelLayout = AVAudioChannelLayout(layoutTag: kAudioChannelLayoutTag_Mono)! // Create a Channel Mixer from the Channel Layout. let channelMixerDefinition = PHASEChannelMixerDefinition(channelLayout: channelLayout) // Create a Sampler Node from "drums" and hook it into the downstream Channel Mixer. let samplerNodeDefinition = PHASESamplerNodeDefinition(soundAssetIdentifier: "drums", mixerDefinition: channelMixerDefinition) // Set the Sampler Node's Playback Mode to Looping. samplerNodeDefinition.playbackMode = .looping; // Set the Sampler Node's Calibration Mode to Relative SPL and Level to 0 dB. samplerNodeDefinition.setCalibrationMode(.relativeSpl, level: 0) // Register a Sound Event Asset with the Engine named "drumEvent". let soundEventAsset = try engine.assetRegistry.registerSoundEventAsset(rootNode:samplerNodeDefinition, identifier: "drumEvent") -
22:21 - Start a Sound Event
// Create a Sound Event from the Sound Event Asset "drumEvent". let soundEvent = try PHASESoundEvent(engine: engine, assetIdentifier: "drumEvent") // Start the Engine. // This will internally start the Audio IO Thread. try engine.start() // Start the Sound Event. try soundEvent.start() -
23:05 - Cleanup
// Stop and invalidate the Sound Event. soundEvent.stopAndInvalidate() // Stop the Engine. // This will internally stop the Audio IO Thread. engine.stop() // Unregister the Sound Event Asset. engine.assetRegistry.unregisterAsset(identifier: "drumEvent", completionHandler:nil) // Unregister the Audio File. engine.assetRegistry.unregisterAsset(identifier: "drums", completionHandler:nil) // Destroy the Engine. engine = nil -
25:14 - Create a Sound Event Asset
// Create a Spatial Pipeline. let spatialPipelineOptions: PHASESpatialPipeline.Options = [.directPathTransmission, .lateReverb] let spatialPipeline = PHASESpatialPipeline(options: spatialPipelineOptions)! spatialPipeline.entries[PHASESpatialCategory.lateReverb]!.sendLevel = 0.1; engine.defaultReverbPreset = .mediumRoom // Create a Spatial Mixer with the Spatial Pipeline. let spatialMixerDefinition = PHASESpatialMixerDefinition(spatialPipeline: spatialPipeline) // Set the Spatial Mixer's Distance Model. let distanceModelParameters = PHASEGeometricSpreadingDistanceModelParameters() distanceModelParameters.fadeOutParameters = PHASEDistanceModelFadeOutParameters(cullDistance: 10.0) distanceModelParameters.rolloffFactor = 0.25 spatialMixerDefinition.distanceModelParameters = distanceModelParameters // Create a Sampler Node from "drums" and hook it into the downstream Spatial Mixer. let samplerNodeDefinition = PHASESamplerNodeDefinition(soundAssetIdentifier: "drums", mixerDefinition:spatialMixerDefinition) // Set the Sampler Node's Playback Mode to Looping. samplerNodeDefinition.playbackMode = .looping // Set the Sampler Node's Calibration Mode to Relative SPL and Level to 12 dB. samplerNodeDefinition.setCalibrationMode(.relativeSpl, level: 12) // Set the Sampler Node's Cull Option to Sleep. samplerNodeDefinition.cullOption = .sleepWakeAtRealtimeOffset; // Register a Sound Event Asset with the Engine named "drumEvent". let soundEventAsset = try engine.assetRegistry.registerSoundEventAsset(rootNode: samplerNodeDefinition, identifier: "drumEvent") -
27:05 - Set Up a Listener
// Create a Listener. let listener = PHASEListener(engine: engine) // Set the Listener's transform to the origin with no rotation. listener.transform = matrix_identity_float4x4; // Attach the Listener to the Engine's Scene Graph via its Root Object. // This actives the Listener within the simulation. try engine.rootObject.addChild(listener) -
27:46 - Set Up a Volumetric Source
// Create an Icosahedron Mesh. let mesh = MDLMesh.newIcosahedron(withRadius: 0.0142, inwardNormals: false, allocator:nil) // Create a Shape from the Icosahedron Mesh. let shape = PHASEShape(engine: engine, mesh: mesh) // Create a Volumetric Source from the Shape. let source = PHASESource(engine: engine, shapes: [shape]) // Translate the Source 2 meters in front of the Listener and rotated back toward the Listener. var sourceTransform: simd_float4x4 sourceTransform.columns.0 = simd_make_float4(-1.0, 0.0, 0.0, 0.0) sourceTransform.columns.1 = simd_make_float4(0.0, 1.0, 0.0, 0.0) sourceTransform.columns.2 = simd_make_float4(0.0, 0.0, -1.0, 0.0) sourceTransform.columns.3 = simd_make_float4(0.0, 0.0, 2.0, 1.0) source.transform = sourceTransform; // Attach the Source to the Engine's Scene Graph. // This actives the Listener within the simulation. try engine.rootObject.addChild(source) -
29:15 - Set Up an Occluder
// Create a Box Mesh. let boxMesh = MDLMesh.newBox(withDimensions: simd_make_float3(0.6096, 0.3048, 0.1016), segments: simd_uint3(repeating: 6), geometryType: .triangles, inwardNormals: false, allocator: nil) // Create a Shape from the Box Mesh. let boxShape = PHASEShape(engine: engine, mesh:boxMesh) // Create a Material. // In this case, we'll make it 'Cardboard'. let material = PHASEMaterial(engine: engine, preset: .cardboard) // Set the Material on the Shape. boxShape.elements[0].material = material // Create an Occluder from the Shape. let occluder = PHASEOccluder(engine: engine, shapes: [boxShape]) // Translate the Occluder 1 meter in front of the Listener and rotated back toward the Listener. // This puts the Occluder half way between the Source and Listener. var occluderTransform: simd_float4x4 occluderTransform.columns.0 = simd_make_float4(-1.0, 0.0, 0.0, 0.0) occluderTransform.columns.1 = simd_make_float4(0.0, 1.0, 0.0, 0.0) occluderTransform.columns.2 = simd_make_float4(0.0, 0.0, -1.0, 0.0) occluderTransform.columns.3 = simd_make_float4(0.0, 0.0, 1.0, 1.0) occluder.transform = occluderTransform // Attach the Occluder to the Engine's Scene Graph. // This actives the Occluder within the simulation. try engine.rootObject.addChild(occluder) -
30:33 - Start a Spatial Sound Event
// Associate the Source and Listener with the Spatial Mixer in the Sound Event. let mixerParameters = PHASEMixerParameters() mixerParameters.addSpatialMixerParameters(identifier: spatialMixerDefinition.identifier, source: source, listener: listener) // Create a Sound Event from the built Sound Event Asset "drumEvent". let soundEvent = try PHASESoundEvent(engine: engine, assetIdentifier: "drumEvent", mixerParameters: mixerParameters) -
31:28 - Example 1: Footstep on creaky wood
// Create a Sampler Node from "footstep_wood_clip_1" and hook it into a Channel Mixer. let footstep_wood_sampler_1 = PHASESamplerNodeDefinition(soundAssetIdentifier: "footstep_wood_clip_1", mixerDefinition: channelMixerDefinition) -
31:54 - Example 2: Random footsteps on creaky wood
// Create a Sampler Node from "footstep_wood_clip_1" and hook it into a Channel Mixer. let footstep_wood_sampler_1 = PHASESamplerNodeDefinition(soundAssetIdentifier: "footstep_wood_clip_1", mixerDefinition: channelMixerDefinition) // Create a Sampler Node from "footstep_wood_clip_2" and hook it into a Channel Mixer. let footstep_wood_sampler_2 = PHASESamplerNodeDefinition(soundAssetIdentifier: "footstep_wood_clip_2", mixerDefinition: channelMixerDefinition) // Create a Random Node. // Add 'Footstep on Creaky Wood' Sampler Nodes as children of the Random Node. // Note that higher weights increase the likelihood of that child being chosen. let footstep_wood_random = PHASERandomNodeDefinition() footstep_wood_random.addSubtree(footstep_wood_sampler_1, weight: 2) footstep_wood_random.addSubtree(footstep_wood_sampler_2, weight: 1) -
32:47 - Example 3: Random footsteps on creaky wood or soft gravel
// Create a Sampler Node from "footstep_gravel_clip_1" and hook it into a Channel Mixer. let footstep_gravel_sampler_1 = PHASESamplerNodeDefinition(soundAssetIdentifier: "footstep_gravel_clip_1", mixerDefinition: channelMixerDefinition) // Create a Sampler Node from "footstep_gravel_clip_2" and hook it into a Channel Mixer. let footstep_gravel_sampler_2 = PHASESamplerNodeDefinition(soundAssetIdentifier: "footstep_gravel_clip_2", mixerDefinition: channelMixerDefinition) // Create a Random Node. // Add 'Footstep on Soft Gravel' Sampler Nodes as children of the Random Node. // Note that higher weights increase the likelihood of that child being chosen. let footstep_gravel_random = PHASERandomNodeDefinition() footstep_gravel_random.addSubtree(footstep_gravel_sampler_1, weight: 2) footstep_gravel_random.addSubtree(footstep_gravel_sampler_2, weight: 1) // Create a Terrain String MetaParameter. // Set the default value to "creaky_wood". let terrain = PHASEStringMetaParameterDefinition(value: "creaky_wood") // Create a Terrain Switch Node. // Add 'Random Footstep on Creaky Wood' and 'Random Footstep on Soft Gravel' as Children. let terrain_switch = PHASESwitchNodeDefinition(switchMetaParameterDefinition: terrain) terrain_switch.addSubtree(footstep_wood_random, switchValue: "creaky_wood") terrain_switch.addSubtree(footstep_gravel_random, switchValue: "soft_gravel") -
34:08 - Example 4: Random footsteps on changing terrain with a variably wet surface
// Create a Sampler Node from "splash_clip_1" and hook it into a Channel Mixer. let splash_sampler_1 = PHASESamplerNodeDefinition(soundAssetIdentifier: "splash_clip_1", mixerDefinition: channelMixerDefinition) // Create a Sampler Node from "splash_clip_2" and hook it into a Channel Mixer. let splash_sampler_2 = PHASESamplerNodeDefinition(soundAssetIdentifier: "splash_clip_2", mixerDefinition: channelMixerDefinition) // Create a Random Node. // Add 'Splash' Sampler Nodes as children of the Random Node. // Note that higher weights increase the likelihood of that child being chosen. let splash_random = PHASERandomNodeDefinition() splash_random.addSubtree(splash_sampler_1, weight: 9) splash_random.addSubtree(splash_sampler_2, weight: 7) // Create a Wetness Number MetaParameter. // The range is [0, 1], from dry to wet. The default value is 0.5. let wetness = PHASENumberMetaParameterDefinition(value: 0.5, minimum: 0, maximum: 1) // Create a 'Wetness' Blend Node that blends between dry and wet terrain. // Add 'Terrain' Switch Node and 'Splash' Random Node as children. // As you increase the wetness, the mix between the dry footsteps and splashes will change. let wetness_blend = PHASEBlendNodeDefinition(blendMetaParameterDefinition: wetness) wetness_blend.addRangeForInputValues(belowValue: 1, fullGainAtValue: 0, fadeCurveType: .linear, subtree: terrain_switch) wetness_blend.addRangeForInputValues(aboveValue: 0, fullGainAtValue: 1, fadeCurveType: .linear, subTree: splash_random) -
// Create a Sampler Node from "gortex_clip_1" and hook it into a Channel Mixer. let noisy_clothing_sampler_1 = PHASESamplerNodeDefinition(soundAssetIdentifier: "gortex_clip_1", mixerDefinition: channelMixerDefinition) // Create a Sampler Node from "gortex_clip_2" and hook it into a Channel Mixer. let noisy_clothing_sampler_2 = PHASESamplerNodeDefinition(soundAssetIdentifier: "gortex_clip_2", mixerDefinition: channelMixerDefinition) // Create a Random Node. // Add 'Noisy Clothing' Sampler Nodes as children of the Random Node. // Note that higher weights increase the likelihood of that child being chosen. let noisy_clothing_random = PHASERandomNodeDefinition() noisy_clothing_random.addSubtree(noisy_clothing_sampler_1, weight: 3) noisy_clothing_random.addSubtree(noisy_clothing_sampler_2, weight: 5) // Create a Container Node. // Add 'Wetness' Blend Node and 'Noisy Clothing' Random Node as children. let actor_container = PHASEContainerNodeDefinition() actor_container.addSubtree(wetness_blend) actor_container.addSubtree(noisy_clothing_random)
-