-
What's new in CloudKit
CloudKit provides a secure, convenient, and reliable cloud database for your apps — and it's only getting better. Discover how you can unravel your threads with support for async/await and convenience API additions. We'll also show you how to encourage collaboration between people using your app through sharing entire record zones of data, and explore how to adopt CloudKit features like encrypted values and help protect sensitive data within your app.
To get the most out of this session, we recommend being familiar with CloudKit and its operations on containers, as well as a basic understanding of record and data types.Resources
Related Videos
WWDC23
WWDC22
WWDC21
- Build apps that share data through CloudKit and Core Data
- Meet async/await in Swift
- Meet CloudKit Console
Tech Talks
-
Search this video…
Nihar: Hello, and welcome to "What's new in CloudKit." My name is Nihar Sharma and I'm an engineer on the CloudKit team, and I'll be joined by my colleague Qian. We're going to start by highlighting some changes to the CloudKit API that take advantage of Swift concurrency. Then, Qian will walk us through the use of encrypted fields on records.
Finally, we'll dig deeper into a new feature that allows you to easily share record zones.
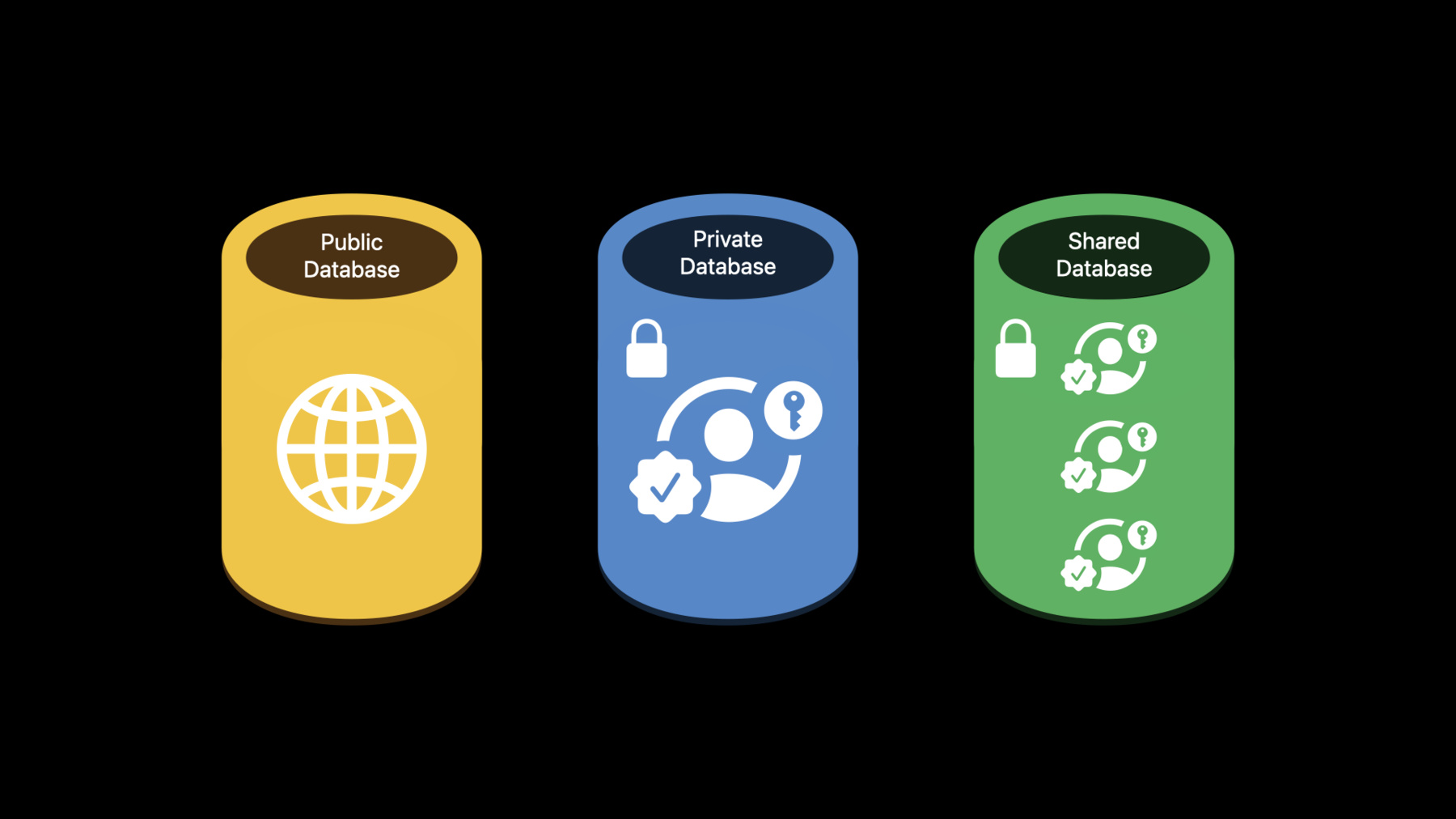
First up, we have CloudKit and Swift concurrency. As a bit of background, CloudKit is a framework that gives your application access to a database on iCloud. This is exposed in the API as a CKContainer through which you can access multiple CKDatabases.
Each container has one public database where all users can potentially read and write records. If the device has a logged-in iCloud account, then your app also has access to a private database, which contains that user's data. And if your app supports sharing, then data which is shared to the current iCloud user will be available to your app in the shared CKDatabase. When writing code against CloudKit, there are two general areas of API. First, the functions, which are available on CKContainer and CKDatabase. This API is useful for new adopters of CloudKit, and is meant to provide a low barrier to entry. Instead of providing you with all of the available configurations, the framework chooses a default behavior, which is most appropriate for a UI application that the user is interacting with. Next is the Operation API, which is exposed as a set of NSOperation subclasses. This API provides a number of features not available as CKContainer or CKDatabase functions.
This includes sending and receiving batches of items in a single round-trip to the server, paging through large result sets by incrementally fetching them from the server, requesting database and record zone changes from the server since some point in the past, and lastly, grouping different operations together. This allows them to be logged as a unit and lets you inform the system about the size of your operation-spanning workload. Many developers eventually use this API when writing production-quality code. Taking advantage of the new Swift concurrency functionality, CloudKit has made several improvements. First, I'll cover how you can use the new Swift async/await feature alongside CloudKit APIs. Then, I'll talk about new API that helps to clarify the difference between a per-item and a per-operation callback, and how CloudKit takes advantage of the Swift.Result type to clarify the role of parameters to those callbacks. And finally, I'll go over enhancements we've made to our container and database functions which help bring over some of the features and configurability previously available only via the operation APIs.
CloudKit API is introducing async variants for functions on container and database. You can use async functions to improve your code that deals with concurrency. It helps with making error handling more natural, and simplifies the visual control flow in your code. For more detail on async functions, please refer to the "Meet async/await in Swift" session. Let's check out an example.
This snippet is taken from the PrivateDatabase code sample. This is one of several CloudKit-specific code samples that Apple recently posted to GitHub, and they are available to you. This specific function wants to delete a record from the server and inform the caller when it's done.
Note that there are many optionals and conditional unwrappings sprinkled around. And when you first try to understand this function, the control flow isn't immediately obvious.
Now, let's compare this to code updated to use CloudKit's async functions. Here, the optionals and unwrappings have been eliminated, and the control flow is linear and easier to follow.
I'm happy to say that each of our code samples on the GitHub repository have updates which demonstrate how the code can be similarly refactored to use Swift concurrency.
Let's talk about per-item callbacks. As an example, here's a CKFetchRecordsOperation sending four CKRecord.IDs to the server, to ideally get back four CKRecord payloads. This operation can go one of three different ways.
In the first case, the operation succeeds. There are no errors, your records are successfully fetched from the server.
The second possibility is that you hit an operation-wide error. This is an error that causes the entire operation to fail. As an example, maybe the device lacks a network connection. In that case, the entire operation would fail with a networkUnavailable error code.
Here's the third option. In this scenario, your operation has successfully round-tripped to the server. The server has successfully returned three of the requested CKRecords, alongside an error indicating that the fourth requested record does not exist. In this example, the per-item error is unknownItem, and it gets bundled into a per-operation error called partialFailure. So, how is this handled in code? On top, CKFetchRecordsOperation declares its perRecordCompletionBlock and per-operation completion block, alongside a sample implementation of each of these on the bottom.
Note the overlap between these two callbacks. From the missing record example from before, the code expects a per-item error twice-- once as a top-level unknownItem error in the per-item callback and again bundled inside a partialFailure error in the per-operation callback. Similarly, it also expects per-item successes in two places for the records which are fetched successfully-- first, as a top-level parameter to a per-item callback, and once again, wrapped in the recordsByRecordID dictionary of successful results in the per-operation callback.
By leveraging Swift.Result type, CloudKit has replaced both of these callbacks to make the API clearer.
Notice the top-level of separation of block parameters in the new result-based callbacks. perRecordResultBlock has an ID, identifying the item that CloudKit is calling back about. And it has its per-item result. The result is now strongly typed, so you know you're getting either a successfully fetched CKRecord payload, or a per-item error.
Similarly, the operation-scoped completion block has also been updated to an operation-scoped result block which no longer duplicates any success or failure already reported by the per-item result block.
So, CloudKit has now formally separated their concerns. One block is used exclusively for per-item reporting, and another exclusively for per-operation reporting.
Going back to our missing record example, the expectation is three invocations of the per-item result block with successfully fetched CKRecord payloads, one invocation of the per-item result block with an unknownItem error, and one invocation of the per-operation result block with no error, as the operation succeeded overall. One of CloudKit's new improvements is to surface separate per-item and per-operation callbacks everywhere. Previously, only the highlighted operations have had per-item callbacks that surface per-item errors.
I'm happy to announce that all CKOperations now expose per-item callbacks that pass back per-item errors when appropriate. Now, let's take a look at some enhancements and expansions we've made to our container and database APIs. The enhancements take the form of new functions on CKContainer and CKDatabase.
Together, these new functions make a large chunk of CKOperation APIs available as functions on CKContainer and CKDatabase.
Importantly, this isn't a one-to-one mapping of the operation API. Instead, we've leveraged default parameters and the Swift.Result type to craft an API that is approachable, powerful, and works with async/await. That is, each new function is exposed twice-- once taking a completionHandler, and again as an async function. With this enhanced API, functions on the container and database now support some of the features from the Operation API, like batching multiple items, paging through large data sets, and fetching changes. You can also group function invocations together for logging, and informing the system about combined workload size.
Function invocations can now also be configured, such as by setting timeouts. So, how does this work? Here, once again, is the GitHub PrivateDatabase code sample we saw earlier, using async functions to delete a record.
Let's see how this code can be updated to take advantage of item batching. I'm going to change the behavior of this function to delete two records atomically by taking advantage of the enhanced function API on database.
Notice the separation of concerns. The highlighted areas operate at the function scope. They kick off the function and catch any function-scoped errors that are thrown.
And if the function successfully completes, this highlighted area will inspect the per-item successes or failures. We have similar examples covering each of these features in the code sample repositories on GitHub, and the notes for this session will include links to those repositories. We hope you'll find them useful. And with that, I'd like to turn it over to Qian to walk us through encrypted fields. Thanks, Nihar. I'm Qian, and I will be talking about a new feature in CloudKit that will make it super easy to protect your users' data privacy. To do this, I will first give an overview of how CloudKit protects your users' data, then I'll introduce the new data encryption feature, and finally, some prerequisites on the user’s account for encryption. At Apple, privacy is one of our core values that we build into all of our products. As the framework that powers many Apple apps and services, CloudKit has been innovating privacy technologies constantly to offer protection for any data stored and synced with CloudKit. Firstly, let me review how CloudKit protects your users' data. CloudKit's approach includes two primary data protection methods, account-based protection and cryptographic protection.
Any data stored with CloudKit is by default protected by account-based authentication. This includes your CloudKit-backed apps and all the Apple CloudKit-backed apps. Upon storage and retrieval, CloudKit uses secure tokens to enforce that only authorized users can access their data and not Apple nor any third party.
As a reminder, only data in private and shared databases are covered by account-based protection. In those databases, data either belongs to or is shared to a specific iCloud account, and access to the shared data needs authentication. However, in public databases, data can be accessed by all users, and therefore, account-based data protection is not applicable by default.
Now, moving on to the other data protection technology-- cryptographic protection. CloudKit provides cryptographic protection for sensitive data stored in Apple-owned apps and services as well as all of your users' data stored in the form of CKAsset. These data are preprocessed and encrypted locally before it's sent to the CloudKit server for storage, and is decrypted locally upon retrieval.
This encryption functionality uses key material that is stored in the iCloud Keychain belonging to the iCloud account signed in on the device. It's also compatible with CloudKit's sharing functionality, ensuring that only the users on the CKShare can decrypt the relevant encrypted fields.
Cryptographic protection adds another layer on top of account-based protection. Because even if an unauthorized party somehow bypasses the authorization, they cannot decrypt the data retrieved.
Cryptographic protection should be used for data that is sensitive or private to your users. Many CloudKit-backed apps within Apple take advantage of this functionality with Photos and Notes as two examples.
Until now, CloudKit's protection for your users' non-asset data provides account-based protection by default. CloudKit is now offering the cryptographic protection in addition to save you from all the key derivation, management, and the encryption/decryption processes, and this will help you build CloudKit-backed apps with stronger than ever privacy promises.
Let's check out the new API to help you do that. You can add any key value pair in the new property encryptedValues on CKRecords for encryption, and the same exact property to get back the decrypted original value.
I'm going to go over how the encryptedValues API enables you to sync encrypted data over the CloudKit server. Here, you have two devices and one CloudKit server. If you set the encryptedValues key value pair, CloudKit will automatically encrypt the record values locally in CKModifyRecordsOperation to the server. On another device, after retrieving the records from the server, you can call the same API and CloudKit will automatically unwrap the key value pair.
You only need minimum code changed to achieve this process. On the first device, using the encryptedValues API, you can set the key value pair on the record. In this case, the key is "encryptedStringField" and the value is a string object. After that, you can then call CKModifyRecordsOperation to save the new records to the server.
On the second device, you can call CKFetchRecordsOperation to retrieve the encrypted record, and by using the same encryptedValues property, you get the string back. That's it. One simple property will handle all of the encryption and decryption processes for you. And you can encrypt almost all of the CKRecord value types except for CKReference because they need to be visible to the server. Note that because CKAsset field, as mentioned previously, already employs encryption by default, they cannot be set as an encryptedValue.
You can visualize the encrypted fields by going to the CloudKit database schema, just like for the regular fields. There is a CloudKit Console session, "Meet CloudKit Console," that shows you other changes made to the Console, and feel free to check it out. In the Console, all encrypted fields will be shown in the drop-down for record value data types.
They will have the prefix "encrypted" such as "Encrypted Double," "Encrypted Timestamp," to help you differentiate them from the unencrypted ones. You can also manage encrypted fields through the CloudKit Console directly, without any code change. For example, you can add a new encrypted field to a new record type in your development database schema.
Moving on to the prerequisite on accounts for operations involving encryption. As any other operations in private and shared databases, they require a valid logged-in account. You need to check the status of your current account in your initialization logic by calling CKContainer accountStatus(completionHandler:).
As a reminder, the status will need to be "available" for operations in private and shared databases.
Any other states will result in error: "CKErrorNotAuthenticated," including the new state, temporarilyUnavailable, introduced this year to indicate that an account is logged in but not ready, and you may direct users to verify their credentials in the Settings app.
If your user's account is not in "available" state, you should listen to CKAccountChanged notification, which posts whenever the account changes, to be notified when the state may be ready.
That's all you need to know about encrypting data with CloudKit. It will protect your users' data and will save you all the time and energy from implementing your own custom solution. Now, back to my amazing colleague Nihar to talk about zone sharing. Thanks, Qian! Let's talk about CloudKit sharing.
CloudKit is your secure, privacy-conscious iCloud database in the sky that helps you store and sync user data across all of your users' devices. iOS 10 and macOS Sierra introduced CloudKit sharing, a way to securely share data with other iCloud users. Before diving into what's new in sharing, let's take a closer look at how CloudKit sharing works today.
As a reminder, CloudKit sharing is initiated via the creation of a CKShare object which separates the data being shared from sharing-related details, like who the data is being shared with, what permissions those share participants have, et cetera.
Behind the scenes, CloudKit establishes cryptographic access to the shared data for participants, on top of requiring account-based authentication for all requests.
Now, there are two main ways that you can add sharing support in your apps. You can either get started quickly by using the system-provided UI for share management, vended via UICloudSharingController on iOS, and NSSharingService on macOS. Or, you can also build your own custom UI for letting users interact with the share setup by using these framework operations.
Like I mentioned earlier, CKShares separate what's being shared from who it's shared with. Today, we're going to be focusing on the first half of that equation, and more specifically, take a look at a couple of different ways you can model your data, and how that affects the way that you leverage the CloudKit sharing APIs.
Let's start with an example that takes advantage of existing CloudKit sharing functionality. iCloud Drive folder sharing is built on top of CloudKit. Let's see how you could go about building something similar in your own apps. So, the data model here represents a filesystem hierarchy, and so you would start off with records of type "file" and "folder," and you want to give users the ability to easily share any folder record along with all of the records, file or folder, that are contained within it.
The way to represent this hierarchical relationship in CloudKit and leverage it for sharing is to use CKRecord.parent references from child to parent records.
This makes it so that CloudKit will treat the resulting hierarchy as a single shareable unit, and so you'll want to go ahead and add those references here. This is very important and what makes parent references special in CloudKit. Note that if you don't plan to support sharing, you don't need to use parent references, and any plain CKReference field in your own schema will suffice.
With that set up, folder sharing can now be supported simply by initializing a CKShare, with the folder record as a CKShare's root record.
Using the folder as the root record means that CloudKit will automatically share all records that are part of the parent-reference based hierarchy ultimately pointing at that folder record. This also means that records added or removed from this hierarchy at a later point are automatically shared or unshared respectively. So how is this simple folder sharing model set up in code? Continuing our example, here are the two file records along with the folder record to be shared in a custom zone in the private database.
First, the parent references are set on both file records pointing to the folder record, and the file records are then saved. Note that it is good practice to save the parent references as early as possible in order to minimize the number of records that need to be modified when the folder is being shared.
Then, all three records are shared by initializing a CKShare with our folder as the root record, and saving the CKShare along with the folder record in the private database. Note that since the parent references were previously saved to the server, only the root folder record needs to be modified along with the share at share-time.
And that's it, your app is now sharing folder records along with the records underneath them. CloudKit can support multiple CKShares within the same zone, as long as their record hierarchies don't overlap.
Now, let's say instead of a hierarchical folder sharing model, you have records representing a few distinct types in your zone, and no logical hierarchy between them.
In other words, the zone is being treated as a bucket of records, and you want to quickly get started with sharing all of the records in it.
Ideally, you'd just be able to mark an entire record zone as "shared" without manipulating any records within it.
Now, with zone sharing, you can do just that. So, let's set this up in code.
All you need to do is to use the new initializer for CKShare that takes a record zone ID for an existing zone in the private database. Once this new zone-wide share record is saved, all records that exist in this zone on the server are automatically shared, and sharing new records or unsharing records going forward works by simply adding or removing those records from the zone. The entire record zone can be unshared at any point by deleting the zone-wide share record. Let's dive a little deeper into these new zone-wide share records.
For convenience, the zone-wide share record always has a well-known record name, CKRecordNameZoneWideShare, which can be used along with the zone ID to create the full share record ID.
Zones using zone sharing do not require any parent references to be set up between records in that zone.
Note that since zone sharing only allows a single share record per zone, this flavor of sharing cannot coexist with hierarchical shares within the same zone. So, you can either have one or more hierarchical shares in a zone, or a single zone-wide share record.
You can save zone-wide shares in any non-default record zone, and these are also marked with a new zone capability, CKRecordZoneCapability ZoneWideSharing.
All existing CloudKit sharing mechanics past the creation of the CKShare record remain the same and are fully supported for zone-wide shares, with one exception. Since there are no longer any root-records when using zone sharing, related properties on CKShareMetadata, like hierarchicalRootRecordID and rootRecord, will be nil when accepting zone shares.
Similarly, when using CKFetchShareMetadataOperation to bootstrap a custom share acceptance flow, properties "shouldFetchRootRecord" and "rootRecordDesiredKeys" will be ignored by the system when fetching share metadata for zone-wide shares.
So, there are now two flavors of CloudKit sharing available depending upon your data model.
If your app's schema logically forms hierarchies and hierarchical trees make sense as shareable units, then continue to use CKRecord parent references to represent those hierarchies, and then share their root records. At Apple, we do this for Notes, Reminders, and iCloud Drive folder sharing in a similar fashion to that explored today.
And for all other cases, you can now efficiently share an entire record zone simply by creating a single zone-wide share record and take full advantage of CloudKit sharing. At Apple, we already leverage zone sharing for several features, like HomeKit secure video sharing and HomePod multiuser.
So today we explored how you can start writing CloudKit code in a new way using async/await in Swift, including enhancements to the per-item progress and error reporting APIs.
We talked about how you can leverage encrypted fields on your records for sensitive user data, taking advantage of Apple's commitment to user privacy, without rolling your own cryptography.
And we learned about a faster way to get started with CloudKit sharing when your data model isn't hierarchical with zone sharing.
There's some great new documentation on these features and more available for you on developer.apple.com, so please take a look. There are many related sessions in the "Explore CloudKit" collection for you to check out as well, including one from Core Data, introducing sharing functionality built on top of CloudKit. Thank you, and hope you have a great WWDC. [upbeat music]
-
-
3:34 - CloudKit: Existing convenience API
// Sample code using existing Convenience API /// Delete the last person record. /// - Parameter completionHandler: An optional handler to process completion `success` or `failure`. func deleteLastPerson(completionHandler: ((Result<Void, Error>) -> Void)? = nil) { database.delete(withRecordID: lastPersonRecordId) { recordId, error in if let recordId = recordId { os_log("Record with ID \(recordId.recordName) was deleted.") } if let error = error { self.reportError(error) // If there is a completion handler, pass along the error here. completionHandler?(.failure(error)) } else { // If there is a completion handler, like during tests, call it back now. completionHandler?(.success(())) } } } -
4:04 - CloudKit: Async convenience API
// Sample code updated to CloudKit Async API /// Delete the last person record. func deleteLastPerson() async throws { do { let recordId = try await database.deleteRecord(with: lastPersonRecordId) os_log("Record with ID \(recordId.recordName) was deleted.") } catch { self.reportError(error) throw error } } -
5:39 - CloudKit: Existing completion blocks
// Error reporting in CKFetchRecordsOperation extension CKFetchRecordsOperation { var perRecordCompletionBlock: ((CKRecord?, CKRecord.ID?, Error?) -> Void)? var fetchRecordsCompletionBlock: (([CKRecord.ID : CKRecord]?, Error?) -> Void)? } fetchRecordsOp.perRecordCompletionBlock = { record, recordID, error in // error is CKError.unknownItem. } fetchRecordsOp.fetchRecordsCompletionBlock = { recordsByRecordID, operationError in // operationError is CKError.partialFailure. // operationError.partialErrorsByItemID[missingRecordID] is CKError.unknownItem. } -
6:35 - CloudKit: Result type completion blocks
// Error reporting in CKFetchRecordsOperation extension CKFetchRecordsOperation { var perRecordResultBlock: ((CKRecord.ID, Result<CKRecord, Error>) -> Void)? var fetchRecordsResultBlock: ((Result<Void, Error>) -> Void)? } fetchRecordsOp.perRecordResultBlock = { recordID, result in // result is .failure(CKError.unknownItem) or .success(record). } fetchRecordsOp.fetchRecordsResultBlock = { result in // result is .success. } -
9:14 - CloudKit: Delete single item
// Single item delete func deleteLastPerson() async throws { do { let recordId = try await database.deleteRecord(with: lastPersonRecordId) os_log("Record with ID \(recordId.recordName) was deleted.") } catch { self.reportError(error) throw error } } -
9:37 - CloudKit: Delete batch
// Batched modifications func deleteLastPeople() async throws { do { let recordIds = [lastPersonRecordId, penultimatePersonRecordId] let (_, deleteResults) = try await database.modifyRecords(deleting: recordIds) for (recordId, deleteResult) in deleteResults { switch deleteResult { case .failure(let error): self.reportError(error, itemId: recordId) case .success: os_log("Record with ID \(recordId.recordName) was deleted.") } } } catch let operationError { self.reportError(operationError) throw operationError } } -
13:43 - CloudKit: Encrypted values
extension CKRecord { @NSCopying open var encryptedValues: CKRecordKeyValueSetting { get } } -
14:29 - CloudKit: Using encrypted values
// Device 1: Encrypt data before calling CKModifyRecordsOperation. myRecord.encryptedValues["encryptedStringField"] = "Sensitive value" // Device 2: Decrypt data after calling CKFetchRecordsOperation. let decryptedString = myRecord.encryptedValues["encryptedStringField"] as? String -
16:35 - CloudKit: Account status
open func accountStatus(completionHandler: @escaping (CKAccountStatus, Error?) -> Void) -
16:46 - CloudKit: CKAccountStatus
public enum CKAccountStatus : Int { case couldNotDetermine case available case restricted case noAccount case temporarilyUnavailable } -
21:10 - CloudKit: Setup a record hierarchy
// Share a record hierarchy let zone = CKRecordZone(zoneName: "MyZone") // Save zone... let fileRecordA = CKRecord(recordType: "File", recordID: CKRecord.ID(zoneID: zone.zoneID)) let fileRecordB = CKRecord(recordType: "File", recordID: CKRecord.ID(zoneID: zone.zoneID)) let folderRecord = CKRecord(recordType: "Folder", recordID: CKRecord.ID(zoneID: zone.zoneID)) fileRecordA.setParent(folderRecord) fileRecordB.setParent(folderRecord) // Save records... -
21:41 - CloudKit: Record Hierarchy, Share
// Share a record hierarchy let share = CKShare(rootRecord: folderRecord) do { let (saveResults, _) = try await database.modifyRecords(saving: [folderRecord, share]) for (recordID, saveResult) in saveResults { // Handle per-record result. } } catch let operationError { // Handle operation error. } -
22:51 - CloudKit: Share a Record Zone
// Share a record zone let zone = CKRecordZone(zoneName: "MyZone") // Save zone... let share = CKShare(recordZoneID: zone.zoneID) do { let (saveResults, _) = try await database.modifyRecords(saving: [share]) for (recordID, saveResult) in saveResults { // Handle per-record result. } } catch let operationError { // Handle operation error. }
-