-
Get to know Create ML Components
Create ML makes it easy to build custom machine learning models for image classification, object detection, sound classification, hand pose classification, action classification, tabular data regression, and more. And with the Create ML Components framework, you can further customize underlying tasks and improve your model. We'll explore the feature extractors, transformers, and estimators that make up these tasks, and show you how you can combine them with other components and pre-processing steps to build custom tasks for concepts like image regression.
For more information on creating complex customizable tasks, we recommend watching "Compose advanced models with Create ML Components" from WWDC22.Resources
Related Videos
WWDC23
WWDC22
- Compose advanced models with Create ML Components
- Meet the Presenter: Compose advanced models with Create ML Components
- Meet the Presenter: Get to know Create ML Components
- Q&A: Create ML
- What's new in Create ML
WWDC21
Tech Talks
WWDC20
WWDC19
-
Search this video…
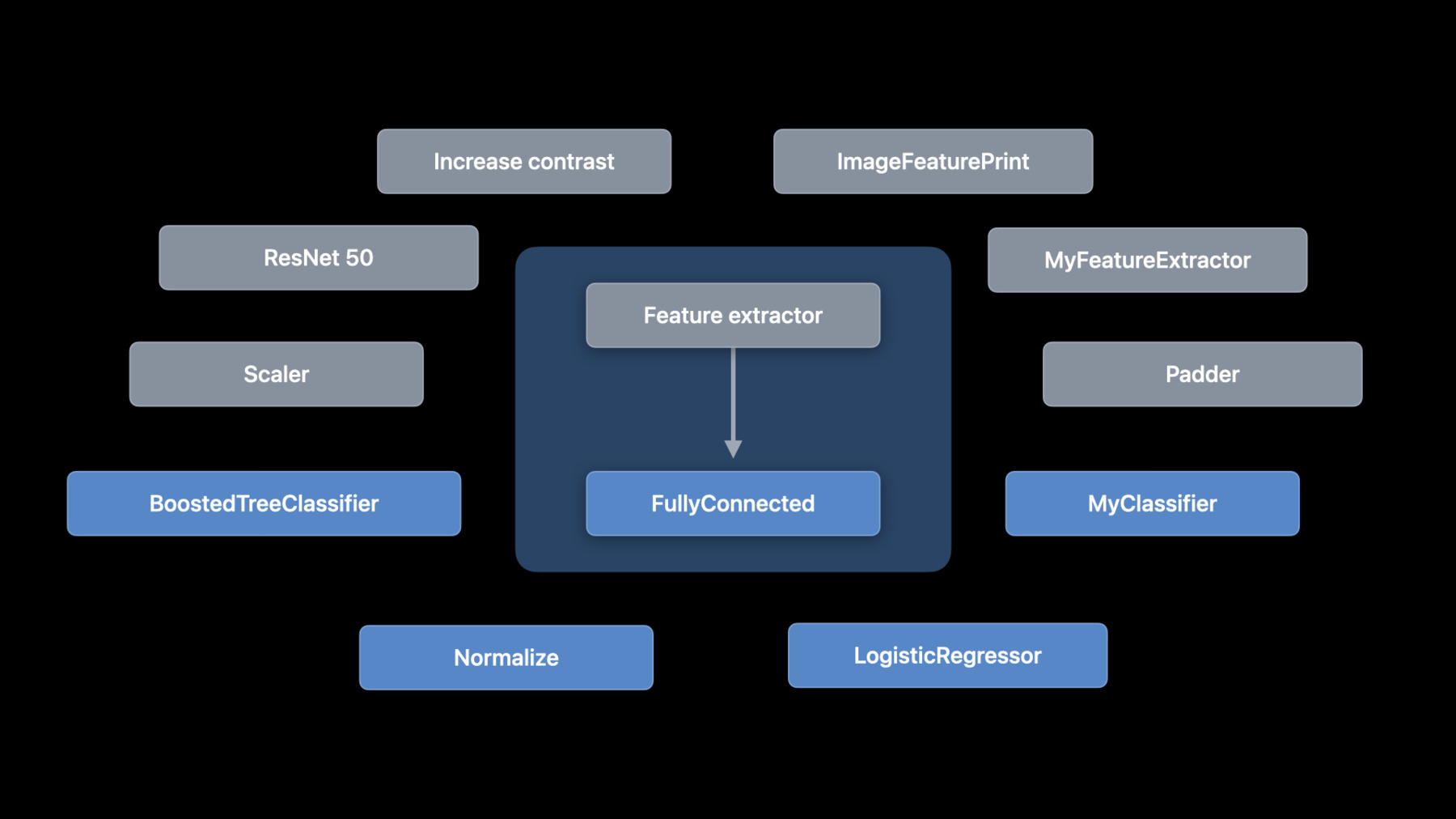
♪ instrumental hip hop music ♪ ♪ Hello, I'm Alejandro. I'm an engineer on the CreateML team. Today I'm going to talk about a brand-new API for building machine learning models using components. Create ML provides a simple API for training machine learning models. It is based on a set of supported tasks like image classification, sound classification, and so on. At WWDC 2021, we presented two great talks on the Create ML framework. Make sure to check those out if you haven't. But I want to talk about going beyond predefined tasks. What if you wanted to customize a task to your particular problem beyond what Create ML offers? Or what if you wanted to build a different type of task? Using components, you can now compose tasks in new and creative ways. Let's dig in. I'll start by breaking up an ML task and explaining what each component does. Then, I'll talk about how you can piece components together. Followed with an example of a custom image task. Then, I'll talk about tabular tasks. And I'll end with deployment strategies. Let me start by exploring the insides of a machine learning task so that you understand what goes into it and how it works. This way, when we start building custom tasks, you know what I'm talking about. I'm going to use an image classifier as an example. An image classifier uses a list of labeled images to train a model. In this example, I have images of cats and dogs with their respective labels. But let's explore how images are transformed at each step. To do that, I'll expand the image classification task to see what's inside. Conceptually, an image classifier is very simple. It consists of a feature extractor and a classifier. But the important part is that Create ML components gives you access to these components independently. You can add, remove, or switch components to compose new tasks. I'm going to represent components as boxes. Arrows represent the flow of data. Let's zoom into the first step of the image classifier: feature extraction. Generally, feature extractors reduce the dimensionality of the input by keeping only the interesting parts -- the features. In the case of images, a feature extractor looks for patterns in the image. Create ML uses Vision Feature Print, which is an excellent image-feature extractor provided by the Vision Framework. Now, let's talk about the second piece: the classifier. A classifier uses a set of examples to learn a classification. Some common implementations are logistic regression, boosted trees, and neural networks. So training an image classifier starts with annotated images, goes to annotated features, and ends with the classifier. But why do we want to break it into pieces? The reason is we want to expand the possibilities. Maybe you want to do some preprocessing by increasing the contrast. Or maybe you want to normalize all images so they have uniform brightness before you extract features. Or maybe you want to try a different feature extractor. Or maybe you want to try a different classifier. The possibilities are endless. These are just a few of the options. That's why we've added support for ML components in macOS, iOS, iPadOS, and tvOS. Our hope is that you can compose new models using some of the components we provide together with your own components, or even components built by others in the community. And you can leverage it across all of our platforms. Here are some of the components built into Create ML Components. But let me take a step back and introduce some concepts. There are two types of components: transformers and estimators. A transformer is simply a type that is able to perform some transformation. It defines an input type and an output type. For example, an image-feature extractor takes an input image and produces a shaped array of features. An estimator, on the other hand, needs to learn from data. It takes input examples, does some processing, and produces a transformer. We call this process "fitting." Great. With those concepts out of the way, let me talk about how Create ML Components lets you build an image classifier from its individual components using composition. This is an image classifier using components. It has ImageFeaturePrint as the feature extractor and LogisticRegressionClassifier as the classifier. Regardless of whether a component is a transformer or an estimator, you combine them using the appending method. And this is where components provide unlimited possibilities. You can use a fully connected neural network as a classifier instead of logistic regression with a simple change. Or you can use a custom feature extractor in a CoreML model. For example, the headless ResNet-50 model you can find in the model gallery. When composing two components, the output of the first component must match the input of the second. In the case of our image classifier, the output of the feature extractor is a shaped array, from the CoreML framework. Which is also the input of a logistic regression classifier. If you get a compiler error when using the appending method, this is the first thing to check. Make sure the types match. But let me clarify an important point around fitting. I said before that fitting is the process of going from an estimator to a transformer. Let's look at this from the perspective of a composed estimator. When your composed estimator has both transformers and estimators, like in the case of the image classifier, only the estimator pieces are fitted. But the transformers are an important part of the process because they are used to feed the correct features to the estimator's fitted method. Here is the code. The image classifier needs a collection of annotated features where the features are images and the annotations are strings. We'll talk about loading the features when we go into the demo. Once I have the data, I can call the fitted method. This returns the trained model, a transformer. And it's important to note that the types used when fitting are related but different from the types of the resulting transformer. In particular, the types used in the fitted method are always collections. And in the case of supervised estimators, the features must include the annotations. Create ML Components uses the AnnotatedFeature type to represent a feature along with its annotation. Once I have the model, I can do predictions. It doesn't matter if it's a model I just fitted, or if I'm loading the parameters from a disk. The API is the same in both cases. Since I am training a classifier, the result is a classification distribution. The distribution includes a probability for each label. In this case, I'm just printing the most likely label for the image. The fitted method also provides a mechanism to observe training events, including validation metrics. In this example, I'm passing validation data and printing the validation accuracy. Note that only supervised estimators provide validation metrics. Once you train a model, you can save the learned parameters, either to reuse later or to deploy to an app. You do this using the write method. Later, you can read using the read method. And that's composition. This is where it gets interesting. Let me talk about writing a new task, something that Create ML didn't support until now.
What if you wanted to train a model to score images? Let's say you have photos of fruit, but instead of classifying the fruit, you wanted to rate it. Give it a score based on how ripe it is. To do this, you need to do regression instead of classification. So let me write an image regressor that gives a score to images of bananas based on ripeness. I'll give each image a ripeness value between one and 10. An image regressor is very similar to an image classifier. The only difference is that our estimator is going to be a regressor instead of a classifier. As you may have already guessed, this is going to be easy. To refresh your memory, here is our image classifier. And this is an image regressor. I substituted the logistic regression classifier with a linear regressor. This simple change also changes the expected input to the fitted method. Before, it expected images and labels. Now, it expects images and scores. But enough about concepts. Let me demo this with some actual code.
Let me show you how to write a custom image regressor. I'll start by defining an ImageRegressor struct to encapsulate the code.
I have a folder with images of bananas at different levels of ripeness. I'm going to start by defining that URL.
The next step is to add a train method. This is where you use training data to produce a model. I'm going to use the "some" keyword on the return type so that the return type doesn't change as I add or modify steps in the composed estimator. Now, I'm going to define the estimator. It's simply the feature extractor with the linear regressor appended. And now, I need to load the training images with their score. I can use AnnotatedFiles, which is a collection of AnnotatedFeatures containing URLs and string labels. It provides a convenience initializer that fits my needs. My files consist of a name, followed by a dash, followed by the ripeness value. So I'm going to specify that the separator is a dash and the annotation is at index: 1 of the filename components. I'm also going to request only image files by using the type argument. Now that I have URLs, I need to load the images. I can use the mapFeatures method and the ImageReader to do this. I also need to convert the scores from strings to floating point values. I can use the mapAnnotations method to do this.
And with that, I have the training data. But I want to put some of it aside for validation. I can use the randomSplit method to do this. I'll keep 80 percent for training and use the rest for validation. Now, I'm ready to fit.
And I'm going to save the trained parameters so that I can deploy to my app. I'll choose a location to save to.
And I'll call the write method.
Finally, I'll return the transformer.
This is the essence of defining and training a model using components. I defined my composed estimator, I loaded my training data, I called the fitted method, and I used write to save the parameters. But there are some things I can improve. For starters, I am passing a validation data set but not observing the validation error, so I'll do that. The fitted method takes an event handler that you can use to gather metrics.
For now, I'll just print both the training and validation maximum-error values. I also want the mean absolute error for the final model.
I compute that by applying the fitted transformer to the validation features and then passing that along with the actual scores to the meanAbsoluteError function. I ran this but I didn't get a great model - the error was high. This is because I don't have that many images of bananas. I should get more images, but before I do that, I can try augmenting my dataset. I can rotate and scale my images to get more examples. To do this, I'm going to write a new method that takes an annotated image and augments it. It returns an array of annotated images.
The first augmentation I'm going to do is rotation.
I'll randomly choose an angle between -pi and pi and use it to rotate the image. I'll also do a random scale.
And I'll return three images: the original, the rotated one, and the scaled one.
Now that I have my augment function, I'll use it to augment my training images using flatMap.
Each element of my dataset will be converted to an array. FlatMap flattens that array of arrays into a single array, which is what I need for the fitted method. Note that augmentations only apply when fitting, not when doing predictions. OK, this increased my accuracy. But let me talk about one more improvement that is going to make my model even better. I want to use the Vision framework to crop the images to the salient object. This is one of the images in my training data. Someone is holding bananas with other fruits in the background. The model may get confused by the other objects in the photo. Using the Vision framework API, I can automatically crop the image to the most salient object. To do this, please check out the Vision talk from WWDC 2019. I can easily apply this transformation to all my images, both when fitting and when getting predictions if I write a custom transformer. Let me show you how. The only thing I need to do to conform to a transformer protocol is implement the applied method. And in this case, I want it to take an image and return an image. I'm not going to go into this code, except to say that if I don't get a salient object, I'll just return the original image. Now that I have my custom transformer, I'll add it to my image regressor.
I just need to use my custom transformer before feature extraction.
Now that saliency is part of my task definition, it will be used to crop every training image, and it will also be used when doing inference. This is one of the advantages of sharing the task definition between training and inference. Before we go on to the next task, let me highlight some important points. Using components, I can now create custom tasks. I did this by using the appending method. I used AnnotatedFiles to load my files with annotated file names, but you can also load files annotated by directories. I mapped the URL to images using ImageReader and mapped the annotations from strings to values. I used randomSplit to set aside a validation dataset, and I saved the trained parameters for use later. Then I added augmentations and defined a custom transformer to improve my model. But this works for more than just images. I'll switch gears and talk about another type of task: tabular tasks. These are tasks that use tabular data. Tabular data is characterized by having multiple features of different types. It can include both numerical data as well as categorical data. A popular example is house-pricing data. You have things like area and age, but also things like neighborhood, type of building, et cetera. And you want to learn to predict a value; for example, the sale price. In 2021, we introduced the TabularData framework. Now you can use the TabularData framework together with Create ML Components to build and train tabular classifiers and regressors. I also recommend the tech talk on TabularData. It's a great introduction to data exploration, which you will likely need when building a tabular task. Let's dive in. When dealing with tabular data, each column of the table will have a different type of feature. And you may want to process each column differently, based on what type of information it contains; the distribution, range of values, and other factors. Create ML Components lets you do this using the ColumnSelector. Here is an example. I mentioned house prices, but those are ridiculous. I'm going to use avocado prices instead. I have this table of avocado prices. I want to build a tabular regressor to predict avocado prices based on this. It contains columns with numeric data such as bags, year, and volume and columns with categorical data such as type and region. Some regressors benefit from having a better representation of these values. For instance, this is the distribution of volume values in the dataset. It is close to a normal distribution, but with large values centered around 15,000. I think this is a great example of a dataset that could benefit from normalization. So the first thing I want to do is normalize these values. To do this, I can pass the column names I want to normalize to the ColumnSelector and then use a standard scaler. Here is the code. First I create a column selector. Then I pass the column names I want to scale. All columns must contain the same type of element; in this case, Double. Then I unwrap optionals. I can do this because I know there are no missing values. But I could also use an imputer which replaces missing values. And then I append the StandardScaler to the unwrapper. So I started with this table where bags numbers were in the tens of thousands and volumes were in the hundreds of thousands. And after scaling those columns, I end up with values that now have a magnitude close to one, which could improve the performance of my model. To be more specific, my values now have a mean of zero and a standard deviation of one. Here is a similar example, but in this example, I'm selecting the type and region columns, which are of type string and performing a one-hot encoding. One-hot encoding refers to encoding categorical data using an array to indicate the presence of each category. In this example, I have three categories: Bronze, Silver, and Gold. Each gets a unique position within the array, indicated by a one in that position. An alternative is to use an ordinal encoder, which gives a consecutive number to each category. Use a one-hot encoder when there are only a few categories and an ordinal encoder otherwise. Now let me put all this together and build a tabular regressor.
As before, I'll start creating a struct and defining the data URL and the parameters URL.
I also want to define a column ID for the column I want to predict: price.
I'll define my task separately so that I can use it both from the train method and the predict method.
As I mentioned, I'm going to normalize the volume.
Then I'm going to use a boosted tree regressor to predict the price. It takes the name of the annotation column -- which is also the column of the resulting predictions -- and it takes the names of all three feature columns. I'll start with these three columns. Then I'll combine the pieces using the appending method and return the task.
Now that I have my task definition, I'll add a train method as before.
And as before, I want to make sure that the return type doesn't depend the specifics of my model. The first step is to load the CSV file into a data frame. I'm using the TabularData framework to do this. And as before, I want to split off some of the data for validation.
I'll pass the training and validation datasets to the fitted method.
I'll also report validation error as before, and I'll save the trained parameters for use later.
Finally, I'll return the transformer.
Once I have a trained transformer, I can use it to make price predictions on data frames. I'm going to write a predict method to do this.
I'll start by loading the model from the task definition and the parameters URL.
I need to make sure the data frame I use for predictions has the columns I used as features: type, region, and volume. The predicted value will be in the price column. I'll use the column ID I defined at the top.
And that concludes my tabular regressor. I have a train method, that I only need to call once to produce my trained parameters, and a predict method that returns the avocado price, predictions based on the type, region, and the volume of avocados. That's all I need to use this in my app. Here are some things to keep in mind when working on tabular tasks. You can use ColumnSelector operations to process specific columns. It's worth noting that tree classifiers and regressors are all tabular, but you can also use a nontabular estimator, such as a linear regressor, in a tabular task using AnnotatedFeatureProvider. Please refer to the documentation. When doing predictions, build a data frame with the required columns, making sure to use the correct types. Now that you know how to build a custom task, let's talk about deployment. So far, I've used the same API for training and inference. I want to point out that when using Create ML Components, your model is your code. You need the task definition, even when loading the trained parameters from a file. This is useful in some situations, but sometimes you may want to use Core ML for deployment. When using Core ML, you leave the code behind. The model is fully represented by a model file. If you are all ready using Core ML, this may be a good workflow. And it has the advantage of optimized tensor operations. But there are some considerations you should keep in mind. Not all operations are supported in Core ML. Specifically, custom transformers and estimators are not supported. And Core ML only supports a few types like images and shaped arrays. If you are using custom types, you may need to convert those in your app when using the Core ML model. This is how you can export your transformer as a Core ML model. If your transformer contains unsupported operations, this will throw an error. If you'd rather stick with deploying your task definition along with the trained parameters, you should consider bundling them in a Swift package. This way, you can provide simple methods to load the parameters and perform a prediction. For more information on Swift package resources, check out the Swift packages talk from WWDC 2020. That's all I have. The main thing to remember is that you can now create custom tasks with composition. The possibilities are endless. I look forward to seeing what you build. For more advanced techniques, including audio and video tasks, check out "Compose advanced models with Create ML Components" where my colleague David will present more advanced custom tasks. Thank you and enjoy the rest of WWDC 2022! ♪
-
-
8:59 - Image regressor
import CoreImage import CreateMLComponents struct ImageRegressor { static let trainingDataURL = URL(fileURLWithPath: "~/Desktop/bananas") static let parametersURL = URL(fileURLWithPath: "~/Desktop/parameters") static func train() async throws -> some Transformer<CIImage, Float> { let estimator = ImageFeaturePrint() .appending(LinearRegressor()) // File name example: banana-5.jpg let data = try AnnotatedFiles(labeledByNamesAt: trainingDataURL, separator: "-", index: 1, type: .image) .mapFeatures(ImageReader.read) .mapAnnotations({ Float($0)! }) let (training, validation) = data.randomSplit(by: 0.8) let transformer = try await estimator.fitted(to: training, validateOn: validation) try estimator.write(transformer, to: parametersURL) return transformer } } -
12:18 - Image regressor with metrics and augmentations
import CoreImage import CreateMLComponents struct ImageRegressor { static let trainingDataURL = URL(fileURLWithPath: "~/Desktop/bananas") static let parametersURL = URL(fileURLWithPath: "~/Desktop/parameters") static func train() async throws -> some Transformer<CIImage, Float> { let estimator = SaliencyCropper() .appending(ImageFeaturePrint()) .appending(LinearRegressor()) // File name example: banana-5.jpg let data = try AnnotatedFiles(labeledByNamesAt: trainingDataURL, separator: "-", index: 1, type: .image) .mapFeatures(ImageReader.read) .mapAnnotations({ Float($0)! }) .flatMap(augment) let (training, validation) = data.randomSplit(by: 0.8) let transformer = try await estimator.fitted(to: training, validateOn: validation) { event in guard let trainingMaxError = event.metrics[.trainingMaximumError] else { return } guard let validationMaxError = event.metrics[.validationMaximumError] else { return } print("Training max error: \(trainingMaxError), Validation max error: \(validationMaxError)") } let validationError = try await meanAbsoluteError( transformer.applied(to: validation.map(\.feature)), validation.map(\.annotation) ) print("Mean absolute error: \(validationError)") try estimator.write(transformer, to: parametersURL) return transformer } static func augment(_ original: AnnotatedFeature<CIImage, Float>) -> [AnnotatedFeature<CIImage, Float>] { let angle = CGFloat.random(in: -.pi ... .pi) let rotated = original.feature.transformed(by: .init(rotationAngle: angle)) let scale = CGFloat.random(in: 0.8 ... 1.2) let scaled = original.feature.transformed(by: .init(scaleX: scale, y: scale)) return [ original, AnnotatedFeature(feature: rotated, annotation: original.annotation), AnnotatedFeature(feature: scaled, annotation: original.annotation), ] } } -
20:23 - Tabular regressor
import CreateMLComponents import Foundation import TabularData struct TabularRegressor { static let dataURL = URL(fileURLWithPath: "~/Downloads/avocado.csv") static let parametersURL = URL(fileURLWithPath: "~/Downloads/parameters.pkg") static let priceColumnID = ColumnID("price", Double.self) static var task: some SupervisedTabularEstimator { let numeric = ColumnSelector( columns: ["volume"], estimator: OptionalUnwrapper() .appending(StandardScaler<Double>()) ) let regression = BoostedTreeRegressor<String>( annotationColumnName: priceColumnID.name, featureColumnNames: ["type", "region", "volume"] ) return numeric.appending(regression) } static func train() async throws -> some TabularTransformer { let dataFrame = try DataFrame(contentsOfCSVFile: dataURL) let (training, validation) = dataFrame.randomSplit(by: 0.8) let transformer = try await task.fitted(to: DataFrame(training), validateOn: DataFrame(validation)) { event in guard let validationError = event.metrics[.validationError] as? Double else { return } print("Validation error: \(validationError)") } try task.write(transformer, to: parametersURL) return transformer } static func predict( type: String, region: String, volume: Double ) async throws -> Double { let model = try task.read(from: parametersURL) let dataFrame: DataFrame = [ "type": [type], "region": [region], "volume": [volume] ] let result = try await model(dataFrame) return result[priceColumnID][0]! } }
-