-
Accelerate machine learning with Metal
Discover how you can use Metal to accelerate your PyTorch model training on macOS. We'll take you through updates to TensorFlow training support, explore the latest features and operations of MPS Graph, and share best practices to help you achieve great performance for all your machine learning needs.
For more on using Metal with machine learning, watch "Accelerate machine learning with Metal Performance Shaders Graph" from WWDC21.Resources
Related Videos
WWDC23
WWDC22
- Discover Metal 3
- Explore the machine learning development experience
- Meet the Presenter: Accelerate machine learning with Metal
- Meet the Presenter: Explore the machine learning developer experience
WWDC21
-
Search this video…
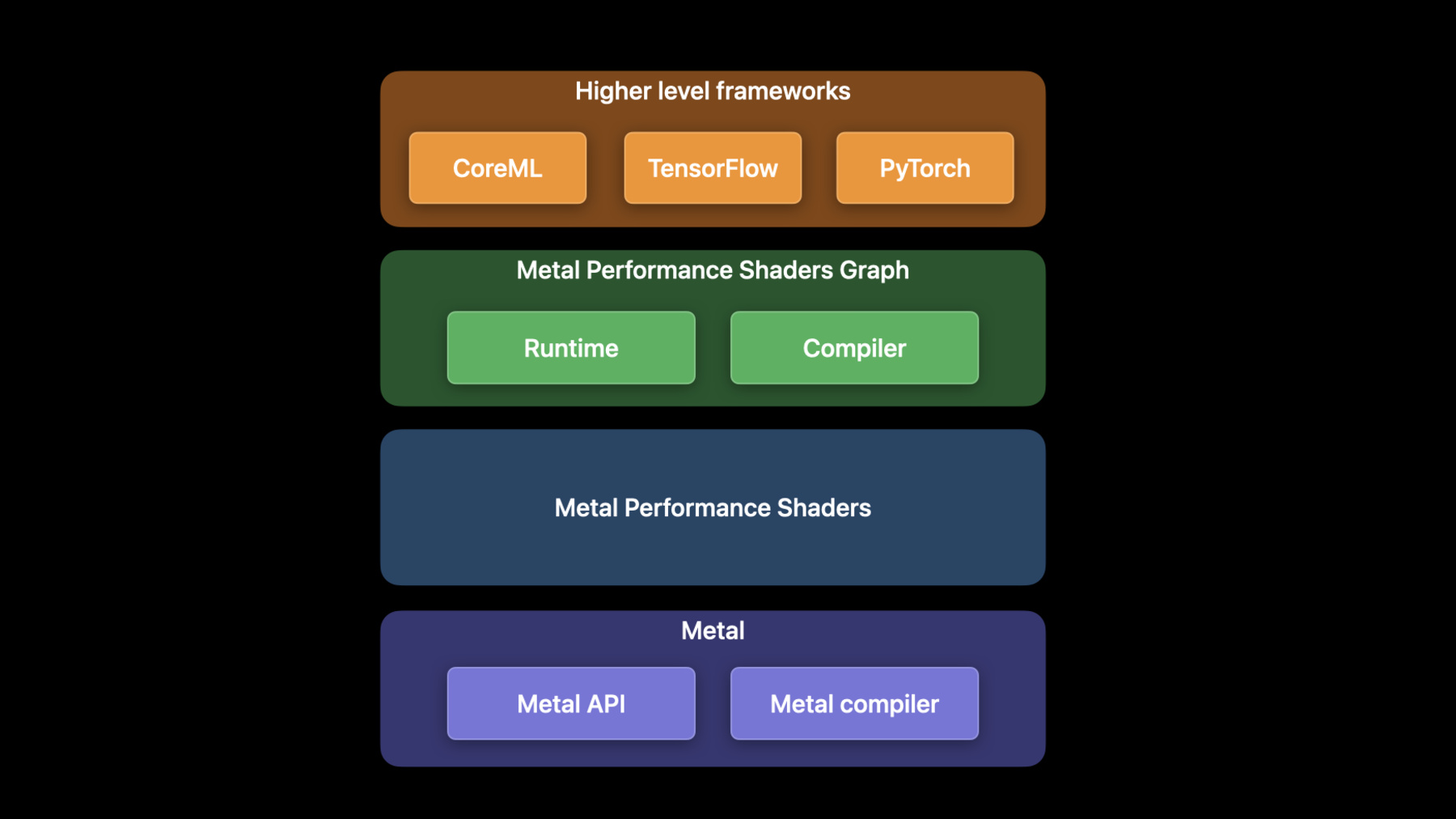
♪ ♪ Dhruva: Welcome to WWDC 2022. My name is Dhruva, and I am a GPUSW Engineer. Today, Matteo and I will explore all the new features and enhancements introduced for machine learning this year in Metal. Machine learning training is the most computationally intensive process of the ML pipeline. Due to their parallel nature, GPUs excel at ML workloads. The Metal machine learning APIs are exposed through a framework called Metal Performance Shaders, or MPS. MPS is a collection of high performance GPU primitives for various fields like Image Processing, Linear Algebra, Ray Tracing, and machine learning. These Metal kernels are optimized to provide the best performance on all of our platforms. For example the MPSImageCanny filter returns an edge-map for an input-image. This is a common operation in image segmentation applications. This year, the Canny filter is able to process 4K, high-resolution images up to eight times faster. MPS Graph, is a general purpose compute graph for the GPU which sits on top of the MPS framework and extends support to multidimensional tensors. I recommend watching the previous session to get more details on how to use MPS Graph. High level ML frameworks like CoreML and Tensorflow sit on top of MPS Graph. You can accelerate your TensorFlow networks on the GPU with the TensorFlow Metal plug-in. For more on how to make the most of TensorFlow, check out last year's session. Matteo and I have three topics to cover in this session. First, I'll introduce the newest ML framework coming to Apple GPUs, PyTorch. Next, I'll dive into the enhancements made to TensorFlow over this year. Finally, Matteo will talk about what's new in the MPS Graph framework.
We are really excited that you will now be able to accelerate your PyTorch networks on your Mac GPUs. PyTorch, is a popular open source machine learning framework. The number one most requested feature, in the PyTorch community was support for GPU acceleration on Apple silicon. We are bringing the power of Metal to PyTorch by introducing a new MPS backend to the PyTorch ecosystem. This backend will be part of the official PyTorch 1.12 release. The MPS backend implements the PyTorch operation kernels, as well as a Runtime framework. The operations call into MPS Graph and MPS and the Runtime component uses Metal. This enables PyTorch to use the highly efficient kernels from MPS along with Metal's Command queues, Command buffers, and synchronization primitives.
The operation kernels and PyTorch MPS Runtime components are part of the open source code and merged into the official PyTorch GitHub repo. Using the MPS PyTorch backend is a simple three-step process. First, starting with PyTorch 1.12, you can install the base package using ‘pip install torch'. This package is available in the official python package repository. For more details on environment setup and installation, please refer to the Metal Developer Resources web page. Second, import PyTorch and create the MPS device. This code snippet uses the MPS device backend if it is available, otherwise it'll fall back to the CPU. The last step is to convert your models and inputs to use the MPS device. To demonstrate how to do this, I will use an example which runs inference on a pre-trained ResNet50 model from torchvision. By default, the model will run on the CPU. You can use the "to" method to convert the model to use the MPS device. This ensures that intermediate tensors inside the model will also use the accelerated MPS backend. Finally, you can run the model. This example passes a random input tensor to the MPS model. By default, all tensors are allocated on the CPU. In order to use the MPS backend, you will also need to provide the mpsDevice here as well. All subsequent operations on this tensor will be accelerated on the GPU. Finally, pass the sample input to the MPS model to get a prediction. Now that you know how to use the MPS device, I'll show you an example of PyTorch in action. I've always wanted to be a famous artist. So I decided to use machine learning and my GPU to help create my artwork using the StyleTransfer network. This network allows you to apply a different artistic style to an image. In this case, the goal is to learn how to apply Van Gogh's style in Starry Night to this picture of a cat. With the new MPS device, you will be able to use the GPU to train your PyTorch networks significantly faster. To demonstrate this, I'll start training this network on both the CPU and GPU simultaneously on an M1 Max. It takes thousands of iterations to learn this style, but the GPU is able to converge to a reasonable model in much less time.
In addition to StyleTransfer, we have seen amazing speedups on all these PyTorch benchmarks. On the M1 Ultra, we saw speedups of up to 20 times faster with an average of 8.3 times faster. PyTorch makes it easy to develop machine learning models, and you'll be able to save a lot of time by using Apple GPUs to train them. Next, I'll dive into all the enhancements we've made this year to TensorFlow. TensorFlow Metal acceleration has been available since TensorFlow version 2.5 through the TensorFlow Metal plug-in. Since then, several additional features and improvements have been added. These include improved training with bigger batches, new operations and custom op support, RNN improvements, and distributed training. The TensorFlow Metal plug-in releases are aligned with major TensorFlow releases, so make sure you update your TensorFlow packages to get the latest features and improvements. Let's start with bigger batch sizes. This year software improvements in TensorFlow Metal allow you to leverage the unique benefits of the Apple silicon architecture. This graph shows speedups training a ResNet50 model with various batch sizes. The data shows that performance improves with bigger batch sizes because each gradient update corresponds more closely to the true gradient. Apple silicon's unified memory architecture allows you to run larger networks or larger batch sizes. Now you can run your workload on a single Mac Studio instead of splitting it across a cloud cluster, which is awesome! The Apple Silicon architecture also has high performance per watt, meaning your networks run more efficiently than ever. Next l'll talk about the new operations and custom operations. The Tensorflow Metal plug-in now has GPU acceleration for a variety of new operations, including argMin, all, pack, adaDelta, and many more. But what if you want GPU acceleration for an operation that's currently not supported in the TensorFlow API? To do this, you will need to create a custom operation. Here's an example of a simple convolutional network running for two iterations. The timeline represents the work done on the GPU and CPU, above and below respectively. The network does a convolution followed by maxpool-ing and then a softmax cross entropy loss. All of these operations are GPU accelerated in the TensorFlow Metal plug-in through MPS Graph But you might want to use a custom loss function. Without MPS GPU acceleration for this custom loss, that work will need to be performed on the CPU timeline which introduces synchronization overhead and starves the GPU. You can achieve far better performance by doing this custom loss on the GPU. In order to implement a custom operation, you will need to understand the TensorFlow Metal Stream protocol. This is a protocol which you use to encode GPU operations. The Metal stream holds a reference to the MTLCommandBuffer you use to encode your GPU kernel. It also exposes the dispatch_queue to use for CPU side synchronization while encoding as there may be multiple threads submitting work. Use the commit or commitAndWait methods to submit the work to the GPU. CommitAndWait is a debugging tool that will wait until the current command buffer is done so you can observe serialized submissions. Now let's see how these concepts can be used to implement a custom op. There are three steps to write a custom operation. First, register the operation. Next, implement the operation using a MetalStream. And finally, import the operation into your training scripts and begin using it. I'll start with registering the operation. Use the REGISTER_OP macro exposed by TensorFlow core to specify the semantics of the op and how it should be defined in the TensorFlow Metal plug-in. Next, implement the op using the TensorFlow_MetalStream. Start by defining the "compute" function. Now, inside this function, get the TensorFlow_Tensor objects for the input and define the output, which might require an allocation. Then create an encoder using the Metal stream's command buffer. Next, define the custom GPU kernel. Your op should be encoded inside the dispatch_queue provided by the Metal stream. This ensures submissions from multiple threads are serialized.
Then commit the kernel by using the method provided in the TensorFlow_MetalStream protocol.
Finally, delete the references to the allocated tensors.
Last, import the operation into your training script to begin using it. In this step, build the custom op's shared dynamic library file called zero_out.so. Refer to Metal Developer Resources for info on how to build and import .so files. This example imports the operation into the training script by using the TensorFlow load_op_library, which is an optional step. Now, this works like a python wrapper and our custom op can be invoked in the training script. Next, I'd like to show you an example of an interesting application called Neural Radiance Fields, or NeRF. We wrote a custom operation that elevated the network's performance by enabling GPU acceleration for a better algorithm.
NeRF is a network used to synthesize 3D views of a model. For training, NeRF takes as input, images of an object from different angles. The NeRF network consists of two stacked Multi-layer perceptrons, and the output is a volumetric representation of the model. A key performance optimization for real time training uses a hash table implementation. This updated network allows a much smaller multi-layer perceptron. TensorFlow does not support hash tables natively so we use the custom op feature to implement them in the Metal plug-in. The GPU acceleration for hash tables makes it possible to train NeRF much faster. I'll start on this MacBook and run original multi-layer perceptron implementation.
In order to render anything reasonable, we need at least 20 epochs but each epoch takes about 100 seconds. That means it will take about 30 minutes before anything is seen. So now I will restart training from a pre-trained checkpoint file, which was left to train for 30 minutes beforehand. This starts at epoch 20. The 3D model is blurred and unclear even after 30 minutes of training. It would require a much longer training time for the network to learn a clearer model. The original two stacked multi-layer perceptron approach without custom hash tables is too slow. Now on this MacBook I'll kick off the optimized version that uses custom hash tables. This implementation is already able to render a much clearer model and each epoch takes only 10 seconds to learn. For more information on this project, check out the sample code which we have uploaded to Metal Developer Resources.
NeRF is just one of the many networks which demonstrates how you can implement GPU acceleration for your own custom operations to make your networks run blazing fast. I look forward to learning about all the creative customizations you make, going forward. Now I want to show you how to use Apple GPUs to distribute training of ML workloads. In order to distribute training of workloads, you can run multiple instances of the training script in separate processes where each process evaluates a single iteration of the model.
Each process will read data from a central data store. After which, it will run through the model and calculate the model gradients. Next, the processes will average the gradients and communicate this to each other so each process has the same gradients before the next iteration. Finally, the model is updated and you can repeat this process until all the iterations are exhausted. To demonstrate this on TensorFlow, I will use an example of distributed training using a popular open source framework called Horovod.
Horovod uses a ring all-reduce approach. In this algorithm, each of N nodes communicates with two of its peers multiple times. Using this communication, the worker processes synchronize gradients before each iteration. I'll show this in action using four Mac Studios connected to each other with Thunderbolt cables. For this example, I will train ResNet, a classifier for images. The bar to the side of each Mac Studio shows the GPU utilization while training this network. For a single Mac Studio, the performance is about 200 images per second. When I add another Mac Studio connected via Thunderbolt, the performance almost doubles to 400 images per second since both GPUs are utilized to the fullest. Finally, when I connect two more Mac Studios, the performance is elevated to 800 images per second. This is almost linear scaling on your compute bound training workloads.
Now here's a look at the Distributed training performance of TensorFlow. This chart shows the relative speedup for one, two, and four Mac Studios. They are connected in a ring topology and run compute bound TensorFlow networks such as resNet and DistilBERT with the latest TensorFlow Metal plug-in and Horovod. The base is the performance on a single Mac Studio. The graph show that network performance scales with the addition of each GPU so you can now leverage GPUs on multiple devices, to speed up your training time and make the most out of all your Apple devices.
All the improvements and features unlocked for TensorFlow this year culminate into this chart showing the relative performance against the CPU implementation with more improvements to come in the future. Now Matteo will share what's new in the MPSGraph framework.
Matteo: Thanks, Dhruva. Hi, my name is Matteo, and I'm a GPU software engineer. PyTorch and TensorFlow sit on top of the MPSGraph framework. In turn, MPSGraph uses the parallel primitives exposed by the MPS framework to accelerate work on the GPU. Today I am going to talk about two features that you can use to accelerate your compute workloads even further with MPSGraph. First, I will show the new shared events API which allows you to synchronize work between two graphs. Second, I will go over new operations, which you can use to do even more with MPSGraph. I'll begin with the Shared Events API. Running applications on the same command queue ensures synchronization between workloads. In this example, the compute workload is guaranteed to always terminate before other workloads, such as post processing and display, are dispatched. In cases like this, you will leverage the GPU parallelism within each single dispatch. However, some applications could benefit from more parallelism, where a first portion of the GPU is used for the compute, and a second portion is used for the post processing and display. This could be achieved by submitting work to the GPU on multiple command queues. Unfortunately, in this case, the post processing pipeline may be dispatched before the compute has produced the results, introducing a data race. The Shared Events API can be used to solve this problem and introduce synchronization across command queues to make sure that workflow dependencies can be satisfied. Using shared events within your code is very simple. Let's assume you are working with two graphs. The first is responsible for the compute workload. The second, is responsible for the post processing workload. Let's also assume that the result of the compute graph is used as input for the post processing graph, and that they run on different command queues. The new MPSGraph track in the Metal System Trace indicates that the command queues are overlapping with each other. This produces a data race. You can solve this problem using a shared event. First, create the event using the Metal device. Next, invoke the signal method in the execution descriptor, providing the event, the action, and the value. Then all you have to do is to call the wait method on the second descriptor, providing event variable and the value.
Now, the Metal system trace indicates that the two command queues are run sequentially, and the dependency between compute and post processing graph has been resolved. That's how you can use shared events to solve synchronization problems in your applications. Second, I'll talk about the new operations supported by MPSGraph. These operations allow you to do even more with the framework. I'll go through some of the details of each of these new ops, starting with RNNs.
MPSGraph now exposes three operations commonly used within Recurrent Neural Network applications. These are the RNN, LSTM, and GRU layers. These operations all work similarly, so I'll just focus on LSTMs today. The LSTM operation is commonly used for natural language processing and other applications. This diagram shows how the LSTM operation works. To learn more about it, check out our previous WWDC session. You could implement the LSTM unit yourself, but to do so, you would have to build this rather complicated custom subgraph. Instead, you can use the new LSTM operation, which efficiently encodes all the GPU work required by the recurrent unit. This new operation makes LSTM-based CoreML inference models significantly faster.
To use the new LSTM operation, first create an MPSGraphLSTMDescriptor. You can modify the descriptor properties as needed, for example selecting the activation functions. Next, add the LSTM unit to the graph, providing the input tensors. You can also provide a bias vector, as well as the initial state and cell for the operation. Finally, provide the descriptor. That's all you need to do to set up an LSTM. The other RNN operations work similarly. I encourage you to try these operations out and see what kind of speedups you can get in your application. Next, I'll show you the improved support for Max Pooling. The Max Pooling operation takes an input tensor and a window size and computes, for each application of the window, the maximum value of the input within the window. It is commonly used in computer vision to reduce the dimensionality of an image. The API has been extended to return the indices of the maximum value location extracted by the pooling operator. You can use indices in the gradient pass, where the gradients must be propagated through the locations where the maximum values were extracted. The new API works for training too. Reusing the indices during training can be up to six times faster for PyTorch and TensorFlow.
To set this up in code, first, create the GraphPooling descriptor. You can specify the returnIndicesMode, for example, globalFlatten4D. Then you can call the pooling operation on the graph with the Return Indices API. The result of the operation is twofold. First, the poolingTensor, and second, the indicesTensor. You can cache the indicesTensor for later use, for example, on a training pipeline.
MPS Graph now exposes a new parallel random number generator, which can be used, for example, to initialize the weights of a training graph. The new random operation uses the Philox algorithm and returns the same results as TensorFlow for a given seed. The new operation takes, as input, a state tensor; it returns as output a random tensor and a new state tensor that can be used, for example, as input for a second random operation. To use the new random operation, call the randomPhiloxStateTensor method. This method initializes an input stateTensor with the given seed. Then declare the RandomOp descriptor, which takes as input the distribution and the data type. In the example, the descriptor specifies a truncatedNormal distribution of 32bit floating point values. You can also use Normal and Uniform distributions.
You can further define the distribution characteristics by specifying the mean, standard deviation, minimum, and maximum values. Finally, you can create the random operation, providing a shapeTensor, the descriptor, and the stateTensor just created.
In addition to Random, MPSGraph now supports a new GPU accelerated operation to compute the Hamming distance between two bit vectors. The hamming distance, defined as the number of bits that differ between two inputs with same length, is a measure of the edit distance between two sequences, and it is used on several applications, from bioinformatics to cryptography. To use HammingDistance, call the API on the graph, providing primaryTensor, secondaryTensor, and the resultDataType. Note that the new kernel supports broadcasting over batch dimensions on the GPU. Now, I'll show you all about the new tensor manipulation operations, which are very easy to use. You can now expand the dimensionality of the tensor, for example, from two to three dimensions. And you can squeeze the dimensions back.
You can also split a tensor evenly providing a number of slices and an axis. or stack tensors along a given axis.
You can also generate coordinate values along tensor dimensions for a given input shape. For example, you can populate a tensor of shape two by four with coordinates along the 0 axis. This can be also used to implement a range1D operation. For example, assume you want to generate the range of numbers between 3 and 27 with increments of 4. You can do so by first creating the coordinates along the dimension 0 of a tensor of shape 6. Then, all you have to do is to multiply by the increment, and add the offset. Those are all of the new operations added this year. With all these new operations, you will be able to do even more and get higher performance across the Apple ecosystem using MPSGraph. Now, I am going to show you the performance improvements you can get on Apple silicon out of MPSGraph.
Blackmagic has just released DaVinci Resolve version 18, which uses MPS Graph to accelerate machine learning workloads. Magic Mask is a feature of Resolve that uses machine learning to identify a moving object on screen and selectively apply filters on top of it. First I'll demonstrate how this works in the previous version of Resolve, and then I'll compare it to the current version. To create the mask, you just need to select the target object. You can view the mask by toggling the overlay. The mask is identified by the red area, which correctly marks the shape of the subject. Now, if I play the video, the mask will track the object as it moves on screen. This looks great, but it's running at a pretty low frame rate, as the machine learning pipeline runs under the hood. Now I'll switch to the newest version of Resolve, which uses MPSGraph to accelerate the Magic Mask network. Running the same timeline again, the frame rate is way faster than before. This results in a much better editing experience on Apple silicon.
These are the kind of speedups you can get just by adopting MPS Graph. I encourage you to explore what kind of performance it can bring to your app. To wrap up, you will now be able to leverage GPU acceleration for PyTorch, and the project is now open source. You will find new ways to accelerate training workloads using the TensorFlow Metal plug-in, for example, using custom operations and distributed training. Finally, you will be able to optimize the most demanding machine learning tasks with the MPSGraph framework to make the best out of Apple silicon, using shared events and new operations. Dhruva and I can't wait to see how you will use these new features in your applications. Thank you for watching the session, and have a great WWDC.
-
-
3:44 - Install PyTorch using pip
python -m pip install torch -
3:59 - Create the MPS device
import torch mpsDevice = torch.device("mps" if torch.backends.mps.is_available() else “cpu”) -
4:15 - Convert the model to use the MPS device
import torchvision model = torchvision.models.resnet50() model_mps = model.to(device=mpsDevice) -
4:46 - Run the model
sample_input = torch.randn((32, 3, 254, 254), device=mpsDevice) prediction = model_mps(sample_input) -
9:27 - TensorFlow MetalStream protocol
@protocol TF_MetalStream - (id <MTLCommandBuffer>)currentCommandBuffer; - (dispatch_queue_t)queue; - (void)commit; - (void)commitAndWait; @end -
10:25 - Register a custom operation
// Register the operation REGISTER_OP("ZeroOut") .Input("to_zero: int32") .Output("zeroed: int32") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c —> set_output(0, c —> input(0)); return Status::OK(); }); -
10:41 - Implement a custom operation
// Define Compute function void MetalZeroOut::Compute(TF_OpKernelContext *ctx) { // Get input and allocate outputs TF_Tensor* input = nullptr; TF_GetInput(ctx, 0, &input, status); TF_Tensor* output; OP_REQUIRES_OK(ctx, ctx->allocate_output(0, input.shape(), &output)); // Use TF_MetalStream to encode the custom op id<TF_MetalStream> metalStream = (id<TF_MetalStream>)(TF_GetStream(ctx, status)); dispatch_sync(metalStream.queue, ^() { id<MTLCommandBuffer> commandBuffer = metalStream.currentCommandBuffer; // Create encoder and encode GPU kernel [metalStream commit]; } // Delete the TF_Tensors TF_DeleteTensor(input); TF_DeleteTensor(output); } -
11:30 - Import a custom operation
# Import operation in python script for training import tensorflow as tf zero_out_module = tf.load_op_library('./zero_out.so') print(zero_out_module.zero_out([[1, 2], [3, 4]]).numpy()) -
19:29 - Using shared events
// Using shared events let executionDescriptor = MPSGraphExecutionDescriptor() let event = MTLCreateSystemDefaultDevice()!.makeSharedEvent()! executionDescriptor.signal(event, atExecutionEvent: .completed, value: 1) let fetch = computeGraph.runAsync(with: commandQueue1, feeds: [input0Tensor: input0), input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor) let executionDescriptor2 = MPSGraphExecutionDescriptor() executionDescriptor2.wait(for: event, value: 1) let fetch2 = postProcessGraph.runAsync(with: commandQueue2, feeds: [input0Tensor: fetch[finalTensor]!, input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor2) -
22:03 - Adding an LSTM unit to the graph
let descriptor = MPSGraphLSTMDescriptor() descriptor.inputGateActivation = .sigmoid descriptor.forgetGateActivation = .sigmoid descriptor.cellGateActivation = .tanh descriptor.outputGateActivation = .sigmoid descriptor.activation = .tanh descriptor.bidirectional = false descriptor.training = true let lstm = graph.LSTM(inputTensor, recurrentWeight: recurrentWeightsTensor, inputWeight: weightsTensor, bias: nil, initState: nil, initCell: nil, descriptor: descriptor, name: nil) -
23:35 - Using MaxPooling with return indices API
// Forward pass let descriptor = MPSGraphPooling4DOpDescriptor(kernelSizes: @[1,1,3,3], paddingStyle: .TF_SAME) descriptor.returnIndicesMode = .globalFlatten4D let [poolingTensor, indicesTensor] = graph.maxPooling4DReturnIndices(sourceTensor, descriptor: descriptor, name: nil) // Backward pass let outputShape = graph.shapeOf(destination, name: nil) let gradientTensor = graph.maxPooling4DGradient(gradient: gradientTensor, indices: indicesTensor, outputShape: outputShape, descriptor: descriptor, name: nil) -
24:42 - Use Random Operation
// Declare Philox state tensor let stateTensor = graph.randomPhiloxStateTensor(seed: 2022, name: nil) // Declare RandomOp descriptor let descriptor = MPSGraphRandomOpDescriptor(distribution: .truncatedNormal, dataType: .float32) descriptor.mean = -1.0f descriptor.standardDeviation = 2.5f descriptor.min = descriptor.mean - 2 * descriptor.standardDeviation descriptor.max = descriptor.mean + 2 * descriptor.standardDeviation let [randomTensor, stateTensor] = graph.randomTensor(shapeTensor: shapeTensor descriptor: descriptor, stateTensor: stateTensor, name: nil) -
25:59 - Use the Hamming Distance API
// Code example remember 2D input tensor let primaryTensor = graph.placeholder(shape: @[3,4], dataType: .uint32, name: nil) let secondaryTensor = graph.placeholder(shape: @[1,4], dataType: .uint32, name: nil) // The hamming distance shape will be 3x1 let distance = graph.HammingDistance(primary: primaryTensor, secondary: secondaryTensor, resultDataType: .uint16 name: nil) -
26:21 - Use the expandDims API
// Expand the input tensor dimensions, 4x2 -> 4x1x2 let expandedTensor = graph.expandDims(inputTensor, axis: 1, name: nil) -
26:30 - Use the squeeze API
// Squeeze the input tensor dimensions, 4x1x2 -> 4x2 let squeezedTensor = graph.squeeze(expandedTensor, axis: 1, name: nil) -
26:35 - Use the Split API
// Split the tensor in two, 4x2 -> (4x1, 4x1) let [split1, split2] = graph.split(squeezedTensor, numSplits: 2, axis: 0, name: nil) -
26:39 - Use the Stack API
// Stack the tensor back together, (4x1, 4x1) -> 2x4x1 let stackedTensor = graph.stack([split1, split2], axis: 0, name: nil) -
26:46 - Use the CoordinateAlongAxis API
// Get coordinates along 0-axis, 2x4 let coord = graph.coordinateAlongAxis(axis: 0, shape: @[2, 4], name: nil) -
27:04 - Create a Range1D operation
// 1. Set coordTensor = [0,1,2,3,4,5] along 0 axis let coordTensor = graph.coordinate(alongAxis: 0, withShape: @[6], name: nil) // 2. Multiply by a stride 4 and add an offset 3 let strideTensor = graph.constant(4.0, dataType: .int32) let offsetTensor = graph.constant(3.0, dataType: .int32) let stridedTensor = graph.multiplication(strideTensor, coordTensor, name: nil) let rangeTensor = graph.addition(offsetTensor, stridedTensor, name: nil) // 3. Compute the result = [3, 7, 11, 15, 19, 23] let fetch = graph.runAsync(feeds: [:], targetTensors: [rangeTensor], targetOperations: nil)
-