-
Developing a Great Profiling Experience
Learn how to add useful tracing to your reusable classes, subsystems, or frameworks. By making it easy to trace your code, you provide adopters with valuable insight and confidence. We'll show you best practices for tracing your Swift and Objective-C code, building custom instruments, and visualizing data in Instruments 11. Share your expertise in a tools experience so others can understand the contracts of your APIs and avoid anti-patterns that impact performance.
Resources
Related Videos
WWDC19
-
Search this video…
Good afternoon and welcome to our session on Developing a Great Profiling Experience. I'm Daniel Delwood and I'll be joined by Kasper Harasim . And today we're here to talk about making great Custom Instruments packages.
Now as developers, we all strive to create excellent, maintainable, modular and reusable code. And we've all used frameworks designed by others and created code that we want others to be able to use well.
And good API design and documentation are critical to the user's experience with your framework. But my hope is today that you consider developing an Instruments package as well.
To see why, take Metal as an example. API design is central and the calls are organized around a set of core concepts, devices, command buffers, textures and more. But that's not the whole story. An API surface expresses what's possible, but documentation and example code are how others learn to compose these concepts into a great app. But that's not the whole story either. Both of the first two help developers write code using your classes or framework. But what happens when something goes wrong? Well, custom Instruments are a way for you as the author to teach others how to debug, optimize and really get the most out of your APIs. If you've used the Metal System Trace template in Instruments, then you've seen some of what's possible. Creating visual tools designed specifically for the concepts and APIs that you define. An Instruments package is a way for you to build transparency that under the hood your framework is tested, understandable and well-supported. And investing that time to create a custom instrument helps create confidence and trust that the code's doing exactly what you expect.
Tools are also a great way to develop a cost model to know which calls are expensive and which are inexpensive. And when there's a performance problem, they're the best way to differentiate between a framework bug or a bug in the client code. Most importantly though, an instrument is an opportunity for you to tell your story. An Instruments package is your chance to explain what's going on to help visualize important metrics and help users quickly find problems when they arise. So today, we're going to cover how to build great instrumentation from the inside out, starting from the inside out of developing great trace points in your framework, and then building on them with schemas, modeling and structure inside Instruments before finally moving on to talking about visualization and the instrument's UI. So with tracing, modeling and visualization as our roadmap for today, let's dive right in and talk about OSSignpost.
Now OSSignpost is a low-cost tracing primitive introduced in 2018. And signposts come in two different kinds: .events and intervals. Now they support recording any kind of data through their printf like formatString in arguments. And different from printf, all signposts are named with a static string.
Now in Swift, OSSignpost is just one core API with three different types: begin, end and event. And in C, their interface is exposed through three helpful macros.
Now it's important to note that OSSignpost is built on OSLog which means that much of the tracing behavior and configurability is determined by the provided log handle.
Now log handles are effectively named spaces for your tracing. They allow you to specify subsystem and category and together with that static name for each signpost, this provides the logical structure and hierarchy for your trace points.
Now custom Instruments are built on OSSignpost for two main reasons. First, they're temporal.
All signposts, whether .events or intervals, implicitly record a high-accuracy timestamp.
It's also important to have first class support for overlapping intervals in our highly-concurrent world. And OSSignpost does this with Signpost IDs. These record enough context for matching up the related events, even when the begin or end event happen on different threads or different dispatch queues. Now the second reason for OSSignpost is that they're low-cost. The logging mechanism is designed with efficiency in mind and it records a minimal amount of data whenever you admit an OSSignpost. Now there are optimizations around static strings, so things like your format string and your signpost name are actually emitted as just an offset into your binary text segment. Now in fact the overhead of OSSignpost is low enough that in most cases you can leave them in production code. So this is what makes them useful for building tools that debug optimized code in addition to helping you solve problems at your desk. Now when Instruments record signpost data, you'll get access to all the explicitly specified fields including that format string and then the arguments you provide. But in Instruments you'll also get access to all of the implicitly specified fields. Things like the timestamp or the calling thread which comes in really useful. If you're using a log handle that has backtraces enabled, then the call stack will also be recorded and made available to you in Instruments.
So when adding tracing to your code, it's important to note that OSLog and OSSignpost behaves in three different modes. By default, OSLog is -- each OSLog handle has signposts enabled. And so they're still low-cost and only logged to a ring buffer.
Now when Instruments or another client requests to display this data immediately, the OSLog system goes into a streaming mode which is a bit higher-cost.
This year though there are two new dynamic categories that are only enabled when Instruments is recording. Now these dynamic categories are configured to record stack traces for the second one which adds a little bit of additional overhead. So with this in mind, what is the actual cost of OSSignpost? Well, many factors impact the real-world performance. Things like device type, hardware model, OS version, system load, thermals and more. So it's hard to give an exact number. But I'd like to give some order of magnitude approximations on a logarithmic scale, because I think it's useful for understanding the relative costs. If we look at Signposts in a release build, all of them clock in at under a microsecond. The new off-by-default dynamic categories are actually in the low nanosecond range.
Now when Instruments is recording in deferred or last few second mode, these dynamic categories turn on to match the behavior of the on-by-default categories. And they are the same expense except for that dynamic stacks category which is a little bit more expensive in the low microsecond range due to the recording a call stack. Now when streaming mode is required though, all of these become significantly more expensive, moving into the tens of microseconds range. So with this in mind, what can you do to minimize the OSSignpost overhead while recording if you're concerned about that runtime cost or they start showing up in your profiles? Well, there's two easy things you can do. First of all, you can use Instruments' deferred or last few seconds mode instead of immediate mode. This keeps OSSignpost out of that streaming mode and reduces the overhead. And it's easy to configure a template to record in one of these modes when you open it.
Also, if you use the new dynamic tracing categories, that's a great way to minimize overhead while not recording. Because the signposts will be off by default. They can only be enabled by custom instruments, so this data also won't crowd the tracks in the built-in OSSignpost tool. So as the author of a framework or a subsystem, just how many signposts is it reasonable to emit while you're profiling? Well, you can emit a lot. But let's assume a very conservative goal of staying under 1% CPU of even a single core while you're profiling. And then let's assume that the signposts have a rough cost, about half a microsecond per signpost enabled.
Well, that math works out to 20,000 signposts per second. And even in a display-link context on an iPad Pro running at 120 frames per second, that's still enough for 83 intervals per frame.
Now again, the real-world performance will change and these are just estimates. So it's important to remember that signposts are a shared resource. The more you use, the more it will impact the logging system. That said, they're designed to allow for this high-rate tracing and it can come in really useful sometimes. Sometimes it's the key to figuring out a pipeline install or an ordering issue in your code. Keep in mind though that you may want to separate signposts out into different categories per audience. It's likely that your clients of your framework will need less detail than contributors of your framework who might need tracing of more implementation details. And if you split your trace points across multiple log handles, this allows your tools to only enable the necessary subset.
Now as tracing is the basis for instrumentation, I want to quickly cover four best practices.
First and most importantly, always end any intervals you begin. It's critical for correctness and permanently open intervals can really slow down Instruments' analysis as well.
In this example, we have OSSignpost calls wrapping an expensive and potentially error-throwing piece of code. The problem is that if an error is thrown, then control flow jumps to the catch scope and skips our end signpost entirely.
Now Swift's defer statement is really a great way to handle this, making sure that regardless of early returns or errors being thrown, that OSSignpost end call will still be called when we exit the current scope.
So second, for efficiency, avoid logging identical data in both the begin and end trace points and log it in the first point it's available. This avoids that duplicate work and it gives Instruments a value as soon as possible. In this example, we don't need to repeat the request number or raw size, and instead of using the request number to match up the intervals in case of overlap, these points could actually use and generate a unique Signpost ID for this log handle per interval pair.
So third, avoid doing unnecessary work when signposts aren't enabled. If your log handle is configured to use one of the dynamic tracing categories, then the signposts enabled property will indicate whether or not Instruments is recording at the time, which means it's a great way to put your expensive data computation behind that OSSignpost-enabled check.
Fourth, only trace data that you actually need for your tools. Think about your guard statements and preconditions, because sometimes you'll want to trace these to include the short intervals. For example, if you've got a method and you want to see the difference between a cash hit and a cash miss.
But other times these early returns will be uninteresting. And for these cases, consider moving the signpost after the preconditions to reduce the amount of data you send to the signpost system.
Now with all these tips, it's important to remember that trace points are really the basis for all of the tools that you build on top. And most of the time they'll be present in your production code. So that's why it's important to think about performance and maintainability of your trace points. And since they're at the core, changes to your signpost calls might result in needing to change the tools that you build on top. So to keep your trace points stable, avoid tracing implementation details and try to add your OSSignpost calls closer to the API layer when possible.
Now moving your trace points around your code base isn't a problem. Now you don't need to worry about compiler optimizations like inlining that might move them for you.
The things that you need to make sure don't change are the static strings, specifically I mean the subsystem, the category, the signpost name or the format string. If you change any of these, you'll need to remember to update your Instruments package as well.
So with that, let's move on to talking about modeling and adding structure to your data within Instruments.
Instruments' architecture is based on everything being stored in tables. And schemas define the structures of those tables, all of which are measured by Instruments instant analysis core. For more in-depth intro to Instruments architecture, I'd recommend the Creating Custom Instruments talk from 2018. For now though, let's look at where modeling fits into creating a profiling experience. On the left, we've covered OSSignpost which is one of the main data sources that Instruments records from. This data is filled in the tables with the pre-defined schema for use by your Custom Instruments.
Modeling is that next phase in the middle. A modeler observes data from one or more input tables, reasons about it and then emits data to one or more output tables of your specification.
The modeler is where your domain-specific logic resides, and the schemas of the output tables are yours to specify which types and formatters to apply to your data.
The final step on the right is visualization which is described in XML to the standard UI in Instruments. It's where you specify how to graph and display the data in your modeler's output tables. Things like which columns to plot and uses the value. Or which columns to use for labels in color.
Since all of the custom instrument's visualization is based on your schemas and your modelers' output, it's important to talk through that process of checking that your OSSignpost trace point are good, and then how to get this data into your custom-defined schema.
So all data in a custom instrument must be stored in tables that handle data in one of two ways. Point schemas have a timestamp column, and interval schemas have both a timestamp and a duration column. This means you'll need to define at least one pointer interval schema and then give names and types to the rest of the columns.
Now the data will be filled in by modeling rules that operate on the input data. And these rules are expressed in Eclipse language. The good news is that Instruments provides a few schemas that will auto-generate modelers. So you don't have to jump into writing Eclipse code until you want to.
In fact, if you're just starting and you want to make sure that your data's correct, Instruments provides a built-in OSSignpost tool in the library that's great for recording and checking that your OSSignpost intervals look reasonable. And the inspector can help you verify that the raw data is exactly what you expect.
Now once you've checked your data, a new instruments target is a great way to start for building your own tool. With Xcode's built-in XML snippets for custom instruments, you're only a few elements away from an automatic modeler and an instrument in the library. And the best way to see what this looks like is with a demo. And for that, I'd like to invite up Kasper. Thank you, Daniel. And hello, everyone.
Our Solar System application on the Mac is dealing with a large amount of data about planets, images, videos and binary data. In order to optimize this usage, I built a framework called solar compression that uses samples compression library to efficiently encode and decode data from the disk.
Now I want to build instrumentation for my framework to provide insights to the future users.
We have two concepts that are worth tracking and presenting visually. Firstly, CompressionManager is an object that coordinates compression tasks. It's created with a number of channels which specifies how many tasks can be executed concurrently.
Secondly, I would like to measure how well compression did for specific file types and algorithms by capturing compression ratio. By examining this, users can decide whether it's worth it to compress their data. I wrote intervals that represent this concept of my framework in OSSignpost API, so let's jump to the CompressionManager Swift file to take a look.
Firstly, let's take a look at the log handle. My log handle specifies my framework's bundle identifier as a subsystem and my class name as a category.
Compress and decompress are part of the public interface of compression manager.
They both start by creating compression work item instance which encapsulates information about certain compression tasks. Next, they call into private SubmitWorkItemMethod.
Because compression channels can be busy with work, there might be significant time between compression item creation and execution on the channel. And this is the perfect place to start measuring this delay.
We'll do it by calling our signpost of type begin with CompressionItemWait name.
Next, we can see our guard condition here which ensures that source file exists before we proceed any further. Following Daniel's advice, I will move it to the top of the function to ensure that my intervals are always closed.
Next, we have ExecuteWorkItemMethod which is called when the compression task is ready to be executed on the channel. At first we need to indicate end of the wait time for the item by calling our signpost of type end with the same name as before. Next, we indicate beginning of the compression with CompressionExecution signpost. In the metadata, we have such things like algorithm, the kind of operation, information about the source, destination, channel and calling thread.
As we learned before, OSSignpost implicitly records several parameters including thread so you are safe to remove the thread now.
Next, we create destination file and synchronously execute compression operation. After it's finished, we log it and attach destination file size. This is another place where I can improve on my signpost invocations. You can notice that StartCompressionMethod over here is a throwing one. And if it does throw an error, the signpost invocation here will not be called.
To prevent this from happening, I can introduce the defer block over here and move my code to be sure that the intervals are always closed.
Now let's see our signpost in Instruments by using Xcode's Profile action.
Let's start with a blank template, add our signpost instrument to it and record for just a few seconds.
We can now examine the data. I will expand our signpost instrument to see all of the recorded subsystems.
Here's our Solar Compression one. I can extend it further to see my Compression Manager category.
Now I can resize this track to fit all of the contained graphs by using Control-Z.
Let's pinch to zoom to examine the data in more detail. On the top we have all of the Compression Execution signposts. And on the bottom we see all of the intervals for the waiting tasks. And we can notice some patterns over here.
For example, at most two tasks are executing at once, so probably application code is using two compression channels.
Also we can see some spikes over here that indicate that a lot of tasks are waiting to be compressed.
OSSignpost is a great tool for analysis of your own signposts, but usually doesn't provide enough context for analyzing them by your framework's audience.
To improve on this, I built Solar Compression instrument that uses custom instruments. But putting these two signposts into two separate tables and adjusting instrument-standard UI, I managed to improve on our visualization. Let's open trace document containing this instrument now.
On the bottom line we see all of the waiting tasks which are represented similarly to the OSSignpost instrument.
On the top we see all of the execution intervals now separated by a channel so we can indeed see that there are two channels available.
On the bottom over here I see all of the compression tasks with information on the interval, source path, file sizes, compression ratio, et cetera.
There's one task that brings my attention. It's pretty long and it's colored in red, which means that the compression for this ratio for this task was slow. To easily see what kind of task it is, I can switch to active tasks detail which is set up to only show intervals that are intersecting my inspection head. I can move my inspection head and analyze a task. It seems that we are trying to compress zip archive and the file size decreased by a bit over 1%. That doesn't seem much and maybe you shouldn't be compressing it at all.
Next, let's see task summary detail which aggregates all of the compression tasks. It provides three aggregation levels: compression kind, source extension and algorithm.
On the right we see different statistical information such as average compression ratio, duration or total saved space.
This detail is very useful for comparing between different algorithms or looking at how compression ratio changes along with the file type.
For example, we can see that our JPEG file size decreased by on average by 34% which seems pretty good for already heavily-compressed file. Now let's take a look at how it all looks in the Instrument Inspector.
We have OSSignpost table over here which is a point schema. It looks at all of our begin and end events.
We also have two tables for our signposts. Here is our execution table. It contains all of the data about tasks that we logged, but now it's formatted according to the engineering types that we assigned. On the right over here we can see that this table is directly consumed by the UI.
I'm pretty happy about my instruments so far. One thing I would like to improve on is how the waiting tasks are represented. Instead of seeing specific intervals, I would like to have some way of summarizing them to clearly point out the areas of higher load. I think that Daniel might have some ideas on how to achieve it. Daniel? Thanks, Kasper. As Kasper showed, the OSSignpost instrument in the library and the Inspector are great ways to visualize your raw data and to check that instrument sees the data you expect. And even without diving into writing a custom Eclipse modeler, Kasper was able to present an instrument that presented his data in a more meaningful way using his framework's compression concepts. There were just four trace points and two OSSignpost interval schemas. That said, it wasn't quite the profiling experience he wanted to create. Now custom modelers are a great way for tailoring that experience. They all you to fuse data for multiple log handles and even use data from built-in tables. They enable you to embed more complex logic, to maintain state, and the reason about the order of events. Writing your own custom modeler can also be useful for some of the more custom graphing and detailed use schemas. The point schema, interval schema and modeler tags are a great way to get started, but it's a deep subject we don't have time to cover in this session. For more on custom modeling though, the 2019 Modeling and Custom Instruments talk goes into a lot more depth and it comes with sample code. So let's move on to talking about the UI part of a profiling experience, visualization.
Visualization is all about the chance for you as the author to tell your story to the developers who will use your code. And the most important principle to remember is that data is not the same thing as a story. Just as Kasper showed by looking at the built-in OSSignpost graphs, raw intervals are only good at conveying meaning to their author.
Users of your tool aren't going to intuitively know whether a gap in the timeline is good or bad or what processing phase was supposed to come next but didn't.
As the developer of an instruments package, you get to go beyond just building visualization showing what happened. You get to teach and diagnose. You get to help your users find problems even when you're not there.
And visualization isn't just about the graph either. Sometimes the best way to communicate a problem is with a right set of statistical data or with a well-crafted textual narrative of exactly what went wrong.
The reason that graphing is so important though is that most of the time it's the user's starting point. It's the first page to your story's book.
Visualization should help others learn, understand and debug, and the selfish motivation is that good tools also speed up triage. That's the goal of visualization, making problems apparent. Graphs are the first summary that you'll see and they should draw your eyes to areas of importance. And once you've started digging in, that's where detail views and metrics should be centered around those core concepts in your code. Now since Instruments deals with two types of time-ordered data, points and intervals, I want to talk through ways of displaying both.
To summarize .events, it helps to evaluate their importance. If they're all relatively equal, then a histogram is a really great way to show the density of events on a timeline. The taller bars immediately convey at a quick glance where to start and where to zoom in. And for custom instruments, the graphing behavior is easy to customize. The histogram element allows you to specify the width of each time bucket and there's a best for resolution element that lets you use a histogram when the user zooms out and then swap for a plot of the individual events when the user zooms in.
Now, when .events vary in importance, it's sometimes helpful to dedicate a lane to the critical events.
Multiple graphs and detail views can reference data from the same table, so specifying the top plot just means describing to Instruments how to slice and choose which values to display from the table. Now both of these can be accomplished purely in XML and without a custom modeler.
Tabular summaries of either point or interval data are your opportunity to define what metrics are important. Within aggregation detail view, there are functions like Min, Max, Average and Standard Deviation for combining values. And new users will look to these summaries that you provide for guidance on what's important and what to optimize. So even display attributes like what the title of the columns are or what order they appear in really matter. Now when users dig further into the details, the narrative engineering type is a great way to explain what's going on. It allows you to use natural language and other type formatters to explain runtime behavior in a way that's approachable. These views are a great way to tell users what was expected to happen and didn't, or when something interesting happened that they might want to investigate further.
So plotting interval data can be a bit trickier.
Unlike points, intervals won't usually fit within a single vertical space because of overlap. If you can plan for a fixed or bounded number of overlapping intervals, there are two ways to split a lane into multiple visual areas vertically. Qualified plots are useful for splitting lanes into multiple spaces with a single title, while instance plots are useful for each getting their own title. Now the OSSignpost tool uses both of these techniques together, but it only works well when there is a limited number of overlapping intervals to display.
When there are a lot, hierarchies, new in Instruments 11, may be the way to go.
Separating trace data into nested tracks makes it easier to filter, to find and even pin just what you're looking for, especially when the number of graphing contexts is large. But whether or not you provide a hierarchy of tracks, it's important to plan for summarizing your interval data either at each level of your hierarchy or as the primary graph of your instrument. For simple interval data, it might be tempting to apply the same solution as for points, using a histogram element.
However, this only works well if you have short intervals as the histogram element aggregates by start time. With longer intervals, this can cause a left-sided skew and it produces very large values.
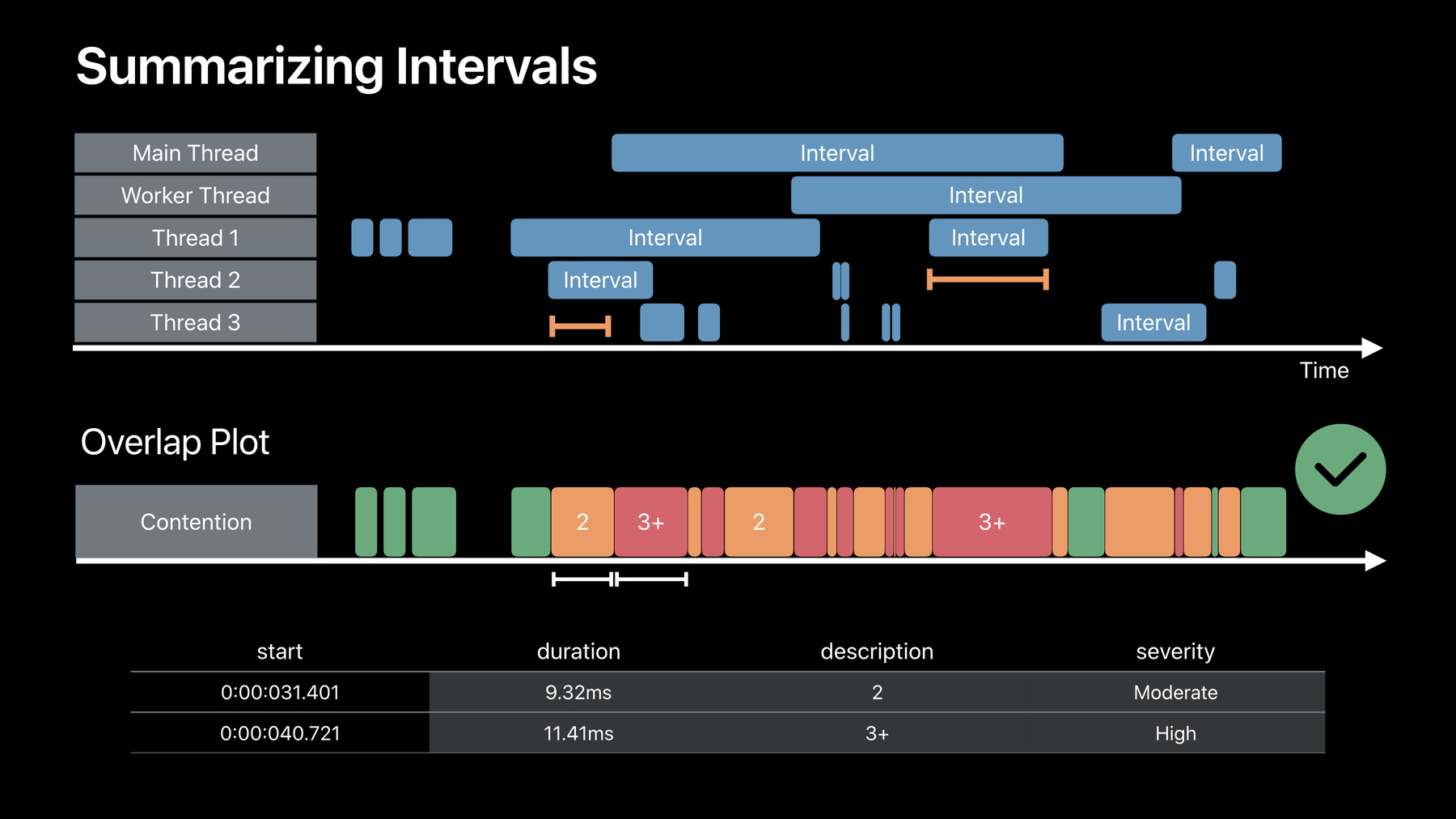
More importantly, when you graph things that have duration, don't graph time on the Y axis as it's already the X axis. Metrics like percent utilization are better for displaying this kind of data. Now in more real-world usage, intervals overlap a lot more, and so I want to show three examples of summary graphs and how the represented concept in your framework and usage patterns that you want can impact your table schemas and held determine the presentation style.
So for some scenarios, persistent overlap indicates high resource utilization. And for this kind of data, a quantized load average is a good way to visualize it, even coloring some extreme values.
Now Eclipse modelers and Instruments are great at maintaining state and fusing data, so combining that OSSignpost event stream with the input from an internal timer tag, a modeler can calculate and emit a quantized utilization average when a timer signal arrives. Now the output table of a modeler might look like this, expressing just four columns of data to draw the plot that you see, including a utilization column for determining the plot's value and a severity column for determining color. Now for other scenarios, lots of quickly running intervals might be more important because they represent inefficient use of your framework.
Looking at the same data as the last example, a better graph might be based on the modeler counting the number of unique intervals seen within a specific time period. Now the modeler's output table would look very similar to the last, but the user's eye is immediately drawn to a very different area of the timeline which helps with zooming in and investigating the cause of these short intervals. And both of the first two examples summarize the data into 10-millisecond groups. But what if the exact periods of the overlap are important, differentiating between one, two or more concurrent intervals? Well, instead of quantizing based on time, a more helpful graph might categorize these by degree of overlap and show the exact durations.
A modeler tracking just the OSSignpost events could output an additional table with a custom interval schema.
And this time, the schema would be filled in with a variable duration and a description column for use as a label.
So all three of these are just examples but hopefully they help to show that when it comes to the presentation of your data, the concepts matter when you're designing a graphing schema. Now for many cases an automatically generated modeler will give you the power and flexibility you need to create the right experience. But there will definitely be times when you want to have more than one input or output. And for those cases in some of the example tables I've showed, custom modelers can provide that additional control and flexibility to express their concepts visually or textually, enrich narratives and graphs and details. So now I'm excited to hand it back to Kasper to see what visualizations he's come up with. Thank you, Daniel. I played around with custom modelers and managed to improve on our existing instrumentation. Let's take a look. I will start with the Solar Conversion template that I crafted.
It now includes a file system activity instrument to provide some additional information about I/O operations overhead when using compression library.
Let's record.
Now I'm recording in the windowed mode to reduce the overhead of the recording.
Instrument is transferring all the data from the host and running the modelers.
Let's examine the data now. I can immediately see that there's some correlation between file system activity and my execution signpost over here. Let's focus on the longer zip compression task that we analyzed before.
It was good to have it colored on the red to get the user's attention. But even better it would be to provide some additional information by using narratives.
I wrote modeler to detect low compression ratio situations and present some possible solutions. Let's take a look at the suggestions detail to take a look at the output of this modeler.
This modeler -- and we get one suggestion. It's saying that file size for archive zip deceased by a bit over 1%. And compression may not be necessary for this file.
It's also hinting that if speed is not an issue, I should try using LZMA algorithm which may provide higher compression ratio. That seems useful. I can now try to change the algorithm, record again and reevaluate the results.
Let's take a look at how the waiting tasks are summarized. I'm calculating average load of the waiting tasks. This way users can clearly point out the areas of higher load.
Let's take a look at this area which is colored in red.
It seems that a lot of tasks are waiting on average, but as they get executed on the channels here, the number is going down.
Users can analyze areas like that and if necessary increase the number of compression channels to achieve higher level of concurrency.
Actually, this conclusion would be a good candidate for another suggestion in our detail. Now let's take a look at how it all plays out in Instrument Inspector.
Let's search for our Solar Compression execution table and take a look at the binding solution.
OSSignpost point schema data is transferred by OSSignpost auto-generated modeler into our Solar Compression execution table. It's right here as we saw before consumed by the UI. We also have this new entity over here which is our suggestions modeler. It's transferring intervals from the compression execution table into the suggestions in the point schema which is later driving the narrative detail. Now I'm happy about how this Instruments conveys the concepts of my library and I feel that we are ready to ship it to our users. Let's go back to the slides.
Creating great profiling experience is about giving your users a path to explore.
They should start with a useful template which is set up to provide necessary instruments for looking at the issue. Remember that if your code is sensitive to information that is exposed by other instrumentation such as sampling, system tracing or priority activity, you should include this in your template.
When analyzing the recording, top-level graphs should quickly draw user attention to where the problems might be in the execution timeline. And details should lead them to the main cause of the issue, often providing meaningful hints. To help you develop even better profiling experience, this year we've introduced two new features in Instruments, the first of which is the concept of hierarchical tracks. One example is OSSignpost instrument visible here which exposes underlying subsystem and category name space through the hierarchy.
Hierarchies are part of custom instruments and any hierarchy that you saw today can be created by your own instrument.
We also have a new way of customizing your profiling workflow through creating custom track scopes.
These allow you to take a look at data gathered in your trace document from different perspectives by applying track filters or choosing different track branches for each scope.
If I'm only interested in seeing system calls and signposts for compression library, or analyzing virtual memory impact of the application, I can create scopes that filter out other tracks and keep coming back to them.
Like here I can save them in my template to share with my team or instrument audience.
Tools in the form of instrumentation are a way to take experience of interacting with your framework from good to great and from unknown to trusted.
They are your opportunity to tell stories about concepts existing in your framework.
They should educate people and help catch easy mistakes.
Whenever clients get performance debugging issues, they should turn to tools to see the answer. And this interaction will increase their confidence and trust in your library. To learn more about Custom Instruments, please visit Instruments Developer Help. We also recommend looking at these other sessions. Thank you and have a great rest of the conference. [ Applause ]
-