-
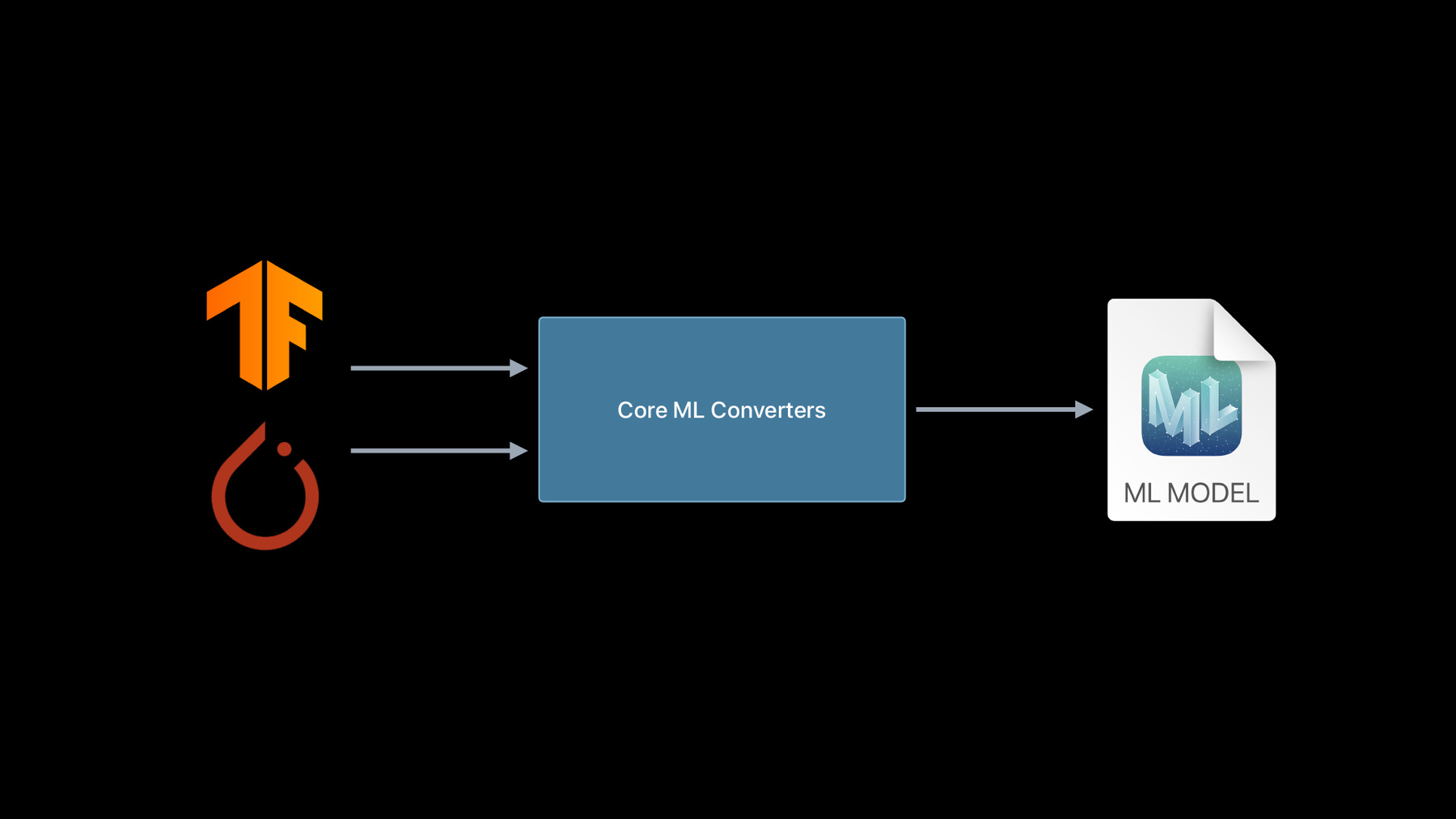
Get models on device using Core ML Converters
With Core ML you can bring incredible machine learning models to your app and run them entirely on-device. And when you use Core ML Converters, you can incorporate almost any trained model from TensorFlow or PyTorch and take full advantage of the GPU, CPU, and Neural Engine. Discover everything you need to begin converting existing models from other ML platforms and explore how to create custom operations that extend the capabilities of your models.
Once you've converted a model to Core ML, learn more about deployment strategy for those models by watching “Use model deployment and security with Core ML.”Resources
Related Videos
WWDC23
WWDC22
WWDC21
WWDC20
-
Search this video…
Hello and welcome to WWDC.
Hi, my name is Aseem, and I'm from the Core ML team. In this session, I want to share with you a few exciting new developments in Core ML converters.
We have been working hard on improving the experience of converting models to Core ML and have significantly updated our conversion tools.
Let's first start by looking, though, at why Core ML is such a great solution for integrating machine learning into your apps. Since Core ML was launched in 2017, our mission has always been about making it as easy as possible to deploy machine learning models into your application to create a wide range of compelling experiences.
With Core ML, the same model can be conveniently deployed to all types of Apple devices, and the best compatibility and performance across OS and device generations is guaranteed. Core ML models seamlessly leverage all the hardware acceleration available on the device, be it the CPU, the GPU or the Apple Neural Engine, which is specifically designed for accelerating neural networks.
In addition, with each new release, you get the best of Apple's ecosystem. For instance, this year we are introducing Core ML model deployment to make it really easy to update your models. Furthermore, Core ML models can now be encrypted.
For more details, please check out our session on "Model Deployment and Security with Core ML." So really, the starting point to unlock all this awesomeness is the Core ML model. And how it can be created is the topic of this session.
A variety of machine learning models, ranging from deep learning to tree based, can be expressed in Core ML. Of course, one of the best sources is the Create ML app, but you can also easily create an ML model starting from your favorite framework using the Core ML Tools Python package.
Over time, as the ML ecosystem grows, the Core ML converters continue to extend support to more frameworks.
This year, we have some exciting announcements regarding our support for neural network libraries.
So far we have supported the conversion of neural network models from one of these frameworks. This year, we have focused on the two most commonly used libraries by the deep learning community, which are PyTorch and TensorFlow.
Lets look at TensorFlow first.
So far, if you wanted to convert a TensorFlow model to Core ML, you would have to additionally install tfcoreml and use its API, which internally depended on the Core ML Tools package. Well, this has changed, and now all you need is Core ML Tools. We have now fully integrated TensorFlow conversion within Core ML Tools. We are also very excited to announce a much expanded support for TensorFlow 2. TensorFlow 1 has been supported for a while now through tfcoreml, and we had added support for TF 2 convolutional models last year.
This year, we significantly expanded to include dynamic models such as LSTMs, transformers, et cetera.
The new converter supports all the different formats in which a TensorFlow model can be exported.
Let's look at conversion from PyTorch now.
So far, the way to do this is to use the PyTorch export tool to produce an ONNX model and then use ONNX Core ML to get to ML model. However, many times the first export step may fail since ONNX is an open standard that evolves independently, so it may lack a newly added feature to PyTorch, or the torch exporter hasn't been updated, or maybe it has a bug. Well, now this extra dependency has been removed since we have implemented a new PyTorch converter.
It's now a one-step process starting from a torch_script_model.
You may have noticed that the API to invoke the PyTorch converter is exactly the same as was used with TensorFlow. That's because we have redesigned the API to keep a single call to invoke all converters. It works, irrespective of which source framework the model needs to be converted from.
With these changes, Core ML Tools is now the one-stop shop for converting models from TensorFlow and PyTorch.
And it's not just the API that has changed. We haven't simply added two new converter paths. Instead, we have undertaken a major effort to redesign the converter architecture to significantly improve the experience and code quality. So, we have moved from having separate converter pipelines, that were built when different converters were added at different points of time, to a single converter stack with maximum code reuse. And to achieve this consolidation, we have introduced a new in-memory representation called Model Intermediate Language, or MIL for short.
MIL has been designed to streamline the conversion process and make it easy to add support for new frameworks. It unifies the stack by providing a common interface to capture information from different frameworks.
It has a set of operations, optimization passes and a model builder API.
As an end user, you generally don't interact with MIL, but it can be really useful in certain scenarios.
We will revisit MIL a bit later in this talk. Let's first see a few examples of using the new converters.
Let's start with a simple image classifier example to get familiar with the new unified API. Let me switch to the Jupyter notebook for that. Here I am in a Jupyter notebook, and I've already imported Core ML Tools. Let's convert from TensorFlow 2 first, which I've imported as well.
I'll grab a model from the TensorFlow 2 model zoo.
I'm using a MobileNet model, which is a popular convolutional model for image classification. Let's load it.
And let's convert it.
To do that I simply type ct.convert...
and provide to it the TensorFlow model object and hit enter.
The converter automatically detects the type of the model, its input shapes, outputs, et cetera, and continues to convert it through MIL.
Okay, it's done. That was easy! Why don't we try it again? This time let's use a model from PyTorch.
For that, let me go ahead and import torch and torchvision. And I'll grab a model this time from torchvision, the mobilenet v2 model.
Now, we need a TorchScript model to convert to Core ML, which can be obtained by either scripting or tracing. I'm gonna use tracing here.
Tracing can be done by using functions provided by PyTorch. Let's see how.
We first get the model in inference mode by using eval. And then invoke the jit.trace method, which needs an example input to work. Let's hit enter. So, we have the traced model, and now we can use Core ML Tools to convert it.
So, I'll again type ct.convert. And this time, I provided the traced model. Now, one more thing. Generally, the information about input shape is not present in the TorchScript model, but that's required for conversion. So let's give it to the converter. And this can be done using the inputs argument to which I will provide the type and shape of the input.
And I can do that by using the TensorType class, which takes a shaping.
That's it. Let's hit enter.
We see the familiar steps of conversion to MIL, a few optimization passes and finally conversion to ML model. And that's done. Let's check out the model interface by printing the ML model object.
Let's see. So, we see that there is an input called input.1, and it's of type multiArray since we provided a TensorType here. And there is an output called 1648. Hmm. That is a bit odd. What really happened there is that that's the name of the output tensor in the torch model, and the converter just automatically picked it up from there.
Well, it's easy to rename it to something more meaningful. Let's see how.
So I use the rename feature utility from Core ML Tools to rename my inputs and outputs to whatever I want. In this case, I use a placeholder name. So let's hit enter and then again print the ML model object. Nice. So we see that the name of inputs and outputs has been updated to the names that I provided.
Let me do one last conversion now, this time from TensorFlow 1. For that, let me move to a different notebook, where I already set up my TensorFlow 1 environment. I also pre-downloaded the mobilenet TensorFlow 1 model, which is in this protobuf pb format. Along with this model came the labels.txt file, which contains the names of the classes that this model was trained on. So let's convert this model.
We'll invoke our familiar convert API, and now we can provide the protobuf pb file to it.
Now, this will work. But let's make a nice Core ML model this time by doing a couple of extra things. So, earlier we had used the TensorType, but since this model really works on an image, you know, it would be nice to let the converter know about it. And I can do that by using the ct.ImageType class, to which I'll provide a couple of pre-processing parameters. Bias...
for each channel in an RGB image and scale.
This will normalize the image as expected by the mobilenet model.
Another thing that I'll change is that since this model performs classification, you know, probably it's a good idea to generate a classifier Core ML model. And this can be done by using the ClassifierConfig class, which takes the labels.txt file as is. Isn't this great? Let's hit enter.
And we are done. Let's go ahead and save this model to disk. Before that though, I'll add some useful metadata regarding license and author. And then I'll go ahead and save the model by typing mlmodel.save.
I'll name my model as mobilenet.mlmodel.
And now I can see that it's on disk. Let's check out this model in Finder. So we see the model is here. Let me click to open it. It automatically opens in Xcode. This year, we have updated our Xcode UI. For classifiers now, the class labels are visible right here. As we can see, this model has about 1,000 classes. There is also a new tab called Preview which is really convenient. And I really like it. We can simply drag and drop a few images in here, and it will automatically run our model on these images and display the predictions. As we can see here, our model seems to be doing quite well on these images. So that wraps up the conversion API demo. Let's recap. We invoked the conversion function with different model types, and it just worked. Now let's try converting a slightly more complex model. For that, I'd like to invite my colleague Gitesh, who will convert a model that's used in translating audio to text.
Thanks, Aseem. Hi, I am Gitesh, an engineer in the Core ML team. In this demo, I will illustrate the automatic handling of flexible shapes and related capabilities of the new Core ML Tools conversion API. And I will demonstrate these using an Automatic Speech Recognition task. In this task, the input is a speech audio file, and the output is the text transcription of it. There are many approaches to Automatic Speech Recognition. The system that I use in my example consists of three stages.
There are pre- and post-processing stages and a neural network model in the middle to do the heavy lifting.
Pre-processing involves extracting the mel spectrum, also called MFCCs, from the raw audio file. These MFCCs are fed to the neural network model, which returns a character level time series of probability distributions.
Those are then post-processed by a CTC decoder to produce the final transcription.
Pre- and post-processing stages employ standard techniques which can be easily implemented. Therefore, my focus will be on converting this model in the center. I use a pre-trained TensorFlow model called DeepSpeech.
At a high level, this model uses an LSTM and a few dense layers stacked on top of each other. And such an architecture is quite common for seq2seq models. Now, let's jump right into the Jupyter notebook to convert this model to Core ML and try it out on a few audio samples. We start with importing some packages. I found the pre-trained weights for DeepSpeech model on this GitHub repository from Mozilla and have already downloaded those weights and a script to export the TensorFlow 1 model from that repository. Let's run the script.
We now have a frozen TensorFlow graph in the protobuf format. Let's look into the outputs of this graph. And for that, I have already written some inspection utilities.
So, this model has four outputs, and this first one, called "mfccs," represents the output of the pre-processing stage. Which means the exported TensorFlow graph contains not just the DeepSpeech model, but also the pre-processing sub-graph.
Let's strip off this pre-processing component by providing the remaining three output names to the unified converter function. And with this information, let's call the Core ML converter.
Nice! The conversion is successful. Now let's run this converted model on an audio sample. First, we load and play an audio file.
Once upon a time, there was an exploding chicken. He met up with a golden tiger, and together, they walked through the green forest. The end. Next, we pre-process it. For the full pipeline to work in this notebook, I have already constructed these pre- and post-processing functions using code in the DeepSpeech repository.
So, this pre-processing has transformed the audio file into a tensor object of this shape, and the shape can be viewed as one audio file, pre-processed into 636 sequences, each of width 19 and containing 26 coefficients. The number of these sequences change with the length of the audio. For this 12 seconds audio file, we have 636 sequences. Let's now inspect the input shapes that the model expects.
So, we see that the first input of this model has almost the correct shape. The only difference is that it can process 16 sequences at a time. Therefore, I will write a loop to break the input features into chunks and feed each segment to the model one by one. I've written that bit of code already. Let me paste it here. You don't need to follow all this code. Basically, we break the pre-processed feature into slices of size 16 and run prediction on each slice, with some state management, inside a loop. Let's run it.
Nice. The transcription looks pretty accurate. Now, everything looks good, but wouldn't it be great if we could run the prediction on the entire pre-processed feature in just one go? Well, it's possible, and we would need a dynamic TensorFlow model for that. Let's rerun the same script from the DeepSpeech repository to obtain a dynamic graph. This time, we provide an additional flag called "n_steps." This flag corresponds to sequence length and had a default value of 16. But now we set it to -1, which means that the sequence length can take any positive value.
We have a new TensorFlow model. Let's convert it.
Great. Conversion is done. Let's inspect how this model is different from the previous one.
Well, one difference I see is that this Core ML model can work on inputs of arbitrary sequence length. And the difference lies not just in the shapes. Under the hood, this dynamic Core ML model is much more complicated than the previous static one. It has lots of dynamic operations such as get shape, dynamic reshape, et cetera. However, our experience of converting it was exactly the same. The converter handled it with just the same amount of ease as before. Let's now validate the model on the same audio file.
This time, we don't need the loop and can directly feed the entire input features to the model. Let's run it.
Great. Transcription looks perfect again. Let's recap what we saw in this demo. So, we worked with two variants of the DeepSpeech model.
On a static TensorFlow graph, the converter produced a Core ML model with inputs of fixed shape.
And with the dynamic variant, we obtained a Core ML model which could accept inputs of any sequence length. Converter handled both cases transparently...
and without making any change to the conversion call. One thing I did not get the chance to show in the demo-- we can start with a dynamic TensorFlow graph and get a static Core ML model. Let's see how we can do it.
First, we define a Type description object...
with name of the input...
and its shape.
Then we feed this object to the conversion API.
That's all. Under the hood, the type and value inference propagates this shape information to remove all the unnecessary dynamic operations. Therefore, static models are likely to be more performant while the dynamic ones are definitely more flexible.
Which one to use depends on the requirements of your application. At this point, we have seen few examples of successful conversion to Core ML. However, in some cases, we might encounter an unsupported op error. In fact, I recently hit this issue. Let me show that to you. So, I was exploring this library for natural language models called "transformers." And a recent model called T5 had caught my attention. Let's convert it. First, we load the pre-trained model from the library. Since the returned object is an instance of tf.keras model...
we can pass it directly into the Core ML converter. Let's do that.
And here we see this unsupported op error for the operation "Einsum." I will now hand it back to Aseem, who will go through a few approaches to handle this issue, and then we will come back to convert this model. We recognize that hitting this error is a challenge in an ever-evolving machine learning space as new ops are regularly added to TensorFlow or PyTorch, or you may be using a custom-built op yourself.
What to do in this case? Well, one option is to use a Core ML custom layer, which allows you to accompany the ML model with your own swift implementation of the op. This is great, but in many cases, it may be possible to take another easier approach. You can use what we call the "composite op," which does not require writing additional Swift code since it can keep everything bundled in the ML model file.
A composite op is built from existing MIL ops. Let's dig a little bit into what MIL is and how we can construct a composite op using it. We developed the model intermediate language to unify the converter stack. If we expand to look at the internals, this stack consists of three sections-- the frontends, the intermediate MIL portion and the backend. For each source framework, there is a separate frontend, which captures a framework specific representation. After that, an MIL program is built, at which point the representation becomes source agnostic. A lot of common optimization passes such as operator fusions, dead code elimination, constant propagation, et cetera, happen here, after which the graph is serialized to the protobuf ML Model format. Another way to look at the same picture is that each source framework has its own dialect which is converted to MIL, as a consolidation point, to ML model. This is one way of going to the MIL format which is what the converter does. But there is another way to directly write out an MIL program using the builder API. MIL is a stand-alone language that can be used to directly express a neural network model. And it is quite similar in its API to the ones many of you are already quite familiar with, whether you are a TensorFlow 2 or a PyTorch user. Let's check out this builder API. Here is how we can start writing an MIL program in Python. We import the builder and define the input by specifying its shape, which is 1, 100, 100, 3 in this case. We can print a description of the program by simply calling print. In the description below, we see that the type of the input was inferred to be Float32, which is the default type. Now let's add the first op. So, we added a ReLu op with this simple syntax. Let's add another op, a transpose op this time. A great thing about the MIL builder is that it instantly performs type and shape inference. We can see here that the shape of the output of the transpose has been updated correctly in the description below. Let's add a reduction operation on the last two axes. And we see, as expected, the shape of the tensor is 1, 3 now. Let's add one last op. Finally, the program returns the output of the log op. So, we see that the API to define a network in MIL is quite straightforward. Let's now see how it can be used to implement a composite op and bypass the unsupported op error. Let me hand it back over to Gitesh to illustrate this. So, we were converting the T5 model and had come across an unsupported op error for Einsum. I read the TensorFlow documentation on it and found that it refers to Einstein summation notation.
Lots of operations like reduce_sum, transpose, trace, et cetera, can be expressed in this notation using a string. For this particular conversion, let's focus on the notation that this model uses.
Looking at the error trace, we see that this model uses Einsum with this notation, which translates to following mathematical expression. This might look complicated, but, effectively, it is just a batched matrix multiplication with a transpose on the second input. And that's great since MIL supports this operation directly. Let's now write a composite op. First, we import MIL Builder and a decorator.
Then we define a function with the same name as TensorFlow operation, which is Einsum in this case. Next, we decorate this function to register it with the converter.
This would ensure that the right function would be invoked whenever Einsum operation is encountered during the conversion.
And finally, we grab the inputs and define a MatMul operation using MIL Builder. That's all. Let's call the Core ML converter again.
Conversion is completed. To verify if it is successful, let's print the ML model.
Perfect! To recap, while converting T5 model, we had hit an unsupported op error for Einsum. In general, Einsum is a complicated operation and can represent a variety of tensor operations, but we did not have to worry about all the possible cases. We just handled the particular parameterization needed for this model, and that was easily implemented using composite ops. To summarize, we have packed Core ML Tools with many new features such as powerful type inference, user-friendly APIs, et cetera, which make Core ML converters easier to use and more extensible. To read more about these features, visit our new documentation that contains several examples including the demos for this session. To wrap up, we have announced the new PyTorch converter and enhanced support for TensorFlow 2. These are available through the new unified API and made possible via MIL.
We would like to invite all of you to try them out and help us make Core ML Tools even better with your feedback. Thank you. [chimes]
-
-
2:58 - TensorFlow conversion using tfcoreml
# pip install tfcoreml # pip install coremltools import tfcoreml mlmodel = tfcoreml.convert(tf_model, mlmodel_path="/tmp/model.mlmodel") -
3:16 - New TensorFlow model conversion
# pip install coremltools import coremltools as ct mlmodel = ct.convert(tf_model) -
3:57 - ONNX conversion to Core ML
# pip install onnx-coreml # pip install coremltools import onnx_coreml onnx_model = torch.export(torch_model) mlmodel = onnx_coreml.convert(onnx_model) -
4:28 - New PyTorch model conversion
# pip install coremltools import coremltools as ct mlmodel = ct.convert(torch_script_model) -
4:52 - Unified conversion API
import coremltools as ct model = ct.convert( source_model # TF1, TF2, or PyTorch model ) -
6:42 - Demo 1: TF2 conversion
import coremltools as ct import tensorflow as tf tf_model = tf.keras.applications.MobileNet() mlmodel = ct.convert(tf_model) -
7:41 - Demo 1: Pytorch conversion
import coremltools as ct import torch import torchvision torch_model = torchvision.models.mobilenet_v2() torch_model.eval() example_input = torch.rand(1, 3, 256, 256) traced_model = torch.jit.trace(torch_model, example_input) mlmodel = ct.convert(traced_model, inputs=[ct.TensorType(shape=example_input.shape)]) print(mlmodel) spec = mlmodel.get_spec() ct.utils.rename_feature(spec, "input.1", "myInputName") ct.utils.rename_feature(spec, "1648", "myOutputName") mlmodel = ct.models.MLModel(spec) print(mlmodel) -
10:37 - Demo 1 : TF1 conversion
import coremltools as ct import tensorflow as tf mlmodel = ct.convert("mobilenet_frozen_graph.pb", inputs=[ct.ImageType(bias=[-1,-1,-1], scale=1/127.0)], classifier_config=ct.ClassifierConfig("labels.txt")) mlmodel.short_description = 'An image classifier' mlmodel.license = 'Apache 2.0' mlmodel.author = "Original Paper: A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, "\ "T. Weyand, M. Andreetto, H. Adam" mlmodel.save("mobilenet.mlmodel") -
13:33 - Demo 1 Recap: Using coremltools convert
import coremltools as ct mlmodel = ct.convert("./tf1_inception_model.pb") mlmodel = ct.convert("./tf2_inception_model.h5") mlmodel = ct.convert(torch_model, inputs=[ct.TensorType(shape=example_input.shape)]) -
15:45 - Converting a Deep Speech model
import numpy as np import IPython.display as ipd import coremltools as ct ### Pretrained models and chekpoints are available on the repository: https://github.com/mozilla/DeepSpeech !python DeepSpeech.py --export_dir /tmp --checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=alphabet.txt --scorer_path=kenlm.scorer >/dev/null 2>&1 ls /tmp/*.pb tf_model = "/tmp/output_graph.pb" from demo_utils import inspect_tf_outputs inspect_tf_outputs(tf_model) outputs = ["logits", "new_state_c", "new_state_h"] mlmodel = ct.convert(tf_model, outputs=outputs) audiofile = "./audio_sample_16bit_mono_16khz.wav" ipd.Audio(audiofile) from demo_utils import preprocessing, postprocessing mfccs = preprocessing(audiofile) mfccs.shape from demo_utils import inspect_inputs inspect_inputs(mlmodel, tf_model) start = 0 step = 16 max_time_steps = mfccs.shape[1] logits_sequence = [] input_dict = {} input_dict["input_lengths"] = np.array([step]).astype(np.float32) input_dict["previous_state_c"] = np.zeros([1, 2048]).astype(np.float32) # Initializing cell state input_dict["previous_state_h"] = np.zeros([1, 2048]).astype(np.float32) # Initializing hidden state print("Transcription: \n") while (start + step) < max_time_steps: input_dict["input_node"] = mfccs[:, start:(start + step), :, :] # Evaluation preds = mlmodel.predict(input_dict) start += step logits_sequence.append(preds["logits"]) # Updating states input_dict["previous_state_c"] = preds["new_state_c"] input_dict["previous_state_h"] = preds["new_state_h"] # Decoding probs = np.concatenate(logits_sequence) transcription = postprocessing(probs) print(transcription[0][1], end="\r", flush=True) !python DeepSpeech.py --n_steps -1 --export_dir /tmp --checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=alphabet.txt --scorer_path=kenlm.scorer >/dev/null 2>&1 mlmodel = ct.convert(tf_model, outputs=outputs) inspect_inputs(mlmodel,tf_model) input_dict = {} input_dict["input_node"] = mfccs input_dict["input_lengths"] = np.array([mfccs.shape[1]]).astype(np.float32) input_dict["previous_state_c"] = np.zeros([1, 2048]).astype(np.float32) # Initializing cell state input_dict["previous_state_h"] = np.zeros([1, 2048]).astype(np.float32) # Initializing hidden state probs = mlmodel.predict(input_dict)["logits"] transcription = postprocessing(probs) print(transcription[0][1]) -
21:52 - Deep Speech Demo Recap: Convert with input type
import coremltools as ct input = ct.TensorType(name="input_node", shape=(1, 16, 19, 26)) model = ct.convert(tf_model, outputs=outputs, inputs=[input]) -
26:26 - MIL Builder API sample
from coremltools.converters.mil import Builder as mb @mb.program(input_specs=[mb.TensorSpec(shape=(1, 100, 100, 3))]) def prog(x): x = mb.relu(x=x) x = mb.transpose(x=x, perm=[0, 3, 1, 2]) x = mb.reduce_mean(x=x, axes=[2, 3], keep_dims=False) x = mb.log(x=x) return x -
28:20 - Converting with composite ops
import coremltools as ct from transformers import TFT5Model model = TFT5Model.from_pretrained('t5-small') mlmodel = ct.convert(model) # Einsum Notation $$ \Large "bnqd,bnkd \rightarrow bnqk" $$ $$ \large C(b, n, q, k) = \sum_d A(b, n, q, d) \times B(b, n, k, d) $$ $$ \Large C = AB^{T}$$ from coremltools.converters.mil import Builder as mb from coremltools.converters.mil import register_tf_op @register_tf_op def Einsum(context, node): assert node.attr['equation'] == 'bnqd,bnkd->bnqk' a = context[node.inputs[0]] b = context[node.inputs[1]] x = mb.matmul(x=a, y=b, transpose_x=False, transpose_y=True, name=node.name) context.add(node.name, x) mlmodel = ct.convert(model) print(mlmodel) -
29:50 - Recap: Custom operation
@register_tf_op def Einsum(context, node): assert node.attr['equation'] == 'bnqd,bnkd->bnqk' a = context[node.inputs[0]] b = context[node.inputs[1]] x = mb.matmul(x=a, y=b, transpose_x=False, transpose_y=True, name=node.name) context.add(node.name, x) -
29:50 - Deep Speech demo utilities
import numpy as np import pandas as pd import tensorflow as tf from tensorflow.python.ops import gen_audio_ops as contrib_audio from deepspeech_training.util.text import Alphabet from ds_ctcdecoder import ctc_beam_search_decoder, Scorer ## Preprocessing + Postprocessing functions are constructed using code in DeepSpeech repository: https://github.com/mozilla/DeepSpeech audio_window_samples = 512 audio_step_samples = 320 n_input = 26 audio_sample_rate = 16000 context = 9 lm_alpha = 0.931289039105002 lm_beta = 1.1834137581510284 scorer_path = "./kenlm.scorer" beam_width = 1024 cutoff_prob = 1.0 cutoff_top_n = 300 alphabet = Alphabet("./alphabet.txt") scorer = Scorer(lm_alpha, lm_beta, scorer_path, alphabet) def audiofile_to_features(wav_filename): samples = tf.io.read_file(wav_filename) decoded = contrib_audio.decode_wav(samples, desired_channels=1) spectrogram = contrib_audio.audio_spectrogram(decoded.audio, window_size=audio_window_samples, stride=audio_step_samples, magnitude_squared=True) mfccs = contrib_audio.mfcc(spectrogram = spectrogram, sample_rate = decoded.sample_rate, dct_coefficient_count=n_input, upper_frequency_limit=audio_sample_rate/2) mfccs = tf.reshape(mfccs, [-1, n_input]) return mfccs, tf.shape(input=mfccs)[0] def create_overlapping_windows(batch_x): batch_size = tf.shape(input=batch_x)[0] window_width = 2 * context + 1 num_channels = n_input eye_filter = tf.constant(np.eye(window_width * num_channels) .reshape(window_width, num_channels, window_width * num_channels), tf.float32) # Create overlapping windows batch_x = tf.nn.conv1d(input=batch_x, filters=eye_filter, stride=1, padding='SAME') batch_x = tf.reshape(batch_x, [batch_size, -1, window_width, num_channels]) return batch_x sess = tf.Session(graph=tf.Graph()) with sess.graph.as_default() as g: path = tf.placeholder(tf.string) _features, _ = audiofile_to_features(path) _features = tf.expand_dims(_features, 0) _features = create_overlapping_windows(_features) def preprocessing(input_file_path): return _features.eval(session=sess, feed_dict={path: input_file_path}) def postprocessing(logits): logits = np.squeeze(logits) decoded = ctc_beam_search_decoder(logits, alphabet, beam_width, scorer=scorer, cutoff_prob=cutoff_prob, cutoff_top_n=cutoff_top_n) return decoded def inspect_tf_outputs(path): with open(path, 'rb') as f: serialized = f.read() gdef = tf.GraphDef() gdef.ParseFromString(serialized) with tf.Graph().as_default() as g: tf.import_graph_def(gdef, name="") output_nodes = [] for op in g.get_operations(): if op.type == "Const": continue if all([len(g.get_tensor_by_name(tensor.name).consumers()) == 0 for tensor in op.outputs]): output_nodes.append(op.name) return output_nodes def inspect_inputs(mlmodel, tfmodel): names = [] ranks = [] shapes = [] spec = mlmodel.get_spec() with open(tfmodel, 'rb') as f: serialized = f.read() gdef = tf.GraphDef() gdef.ParseFromString(serialized) with tf.Graph().as_default() as g: tf.import_graph_def(gdef, name="") for tensor in spec.description.input: name = tensor.name shape = tensor.type.multiArrayType.shape if tensor.type.multiArrayType.shapeRange: for dim, size in enumerate(tensor.type.multiArrayType.shapeRange.sizeRanges): if size.upperBound == -1: shape[dim] = -1 elif size.lowerBound < size.upperBound: shape[dim] = -1 elif size.lowerBound == size.upperBound: assert shape[dim] == size.lowerBound else: raise TypeError("Invalid shape range") coreml_shape = tuple(None if i == -1 else i for i in shape) tf_shape = tuple(g.get_tensor_by_name(name + ":0").shape.as_list()) shapes.append({"Core ML shape": coreml_shape, "TF shape": tf_shape}) names.append(name) ranks.append(len(coreml_shape)) columns = [shapes[i] for i in np.argsort(ranks)[::-1]] indices = [names[i] for i in np.argsort(ranks)[::-1]] return pd.DataFrame(columns, index= indices)
-