-
Advancements in the Objective-C runtime
Dive into the microscopic world of low-level bits and bytes that underlie every Objective-C and Swift class. Find out how recent changes to internal data structures, method lists, and tagged pointers provide better performance and lower memory usage. We'll demonstrate how to recognize and fix crashes in code that depend on internal details, and show you how to keep your code unaffected by changes to the runtime.
Resources
Related Videos
WWDC20
-
Search this video…
Hello and welcome to WWDC.
Hi everyone, I’m Ben. I’m in the Languages and Runtimes team, and I’m going to talk to you about changes we’ve made this year in the Objective-C runtime in iOS and mac OS that significantly improve memory use. This talk is a little bit different to most. You shouldn’t need to change any of your code. I’m not going to talk about any new APIs to learn this year or deprecation warnings to squash. With any luck, you won’t need to do anything and your apps will just get faster. Why are we telling you about these improvements? Well, partly because we think they’re cool and interesting, but also because these kind of improvements in the runtime are only possible because our internal data structures are hidden behind APIs. When apps access these data structures directly, things get a little crashy.
In this talk you’ll learn a few things to watch out for that might happen when someone else working on your codebase, not you obviously, access things that they shouldn’t. We’re gonna cover three changes in this session. First, there’s a change in the data structures that the Objective-C runtime uses to track classes.
Then we’ll take a look at changes to Objective-C method lists.
Finally, we’ll look at a change in how tagged pointers are represented.
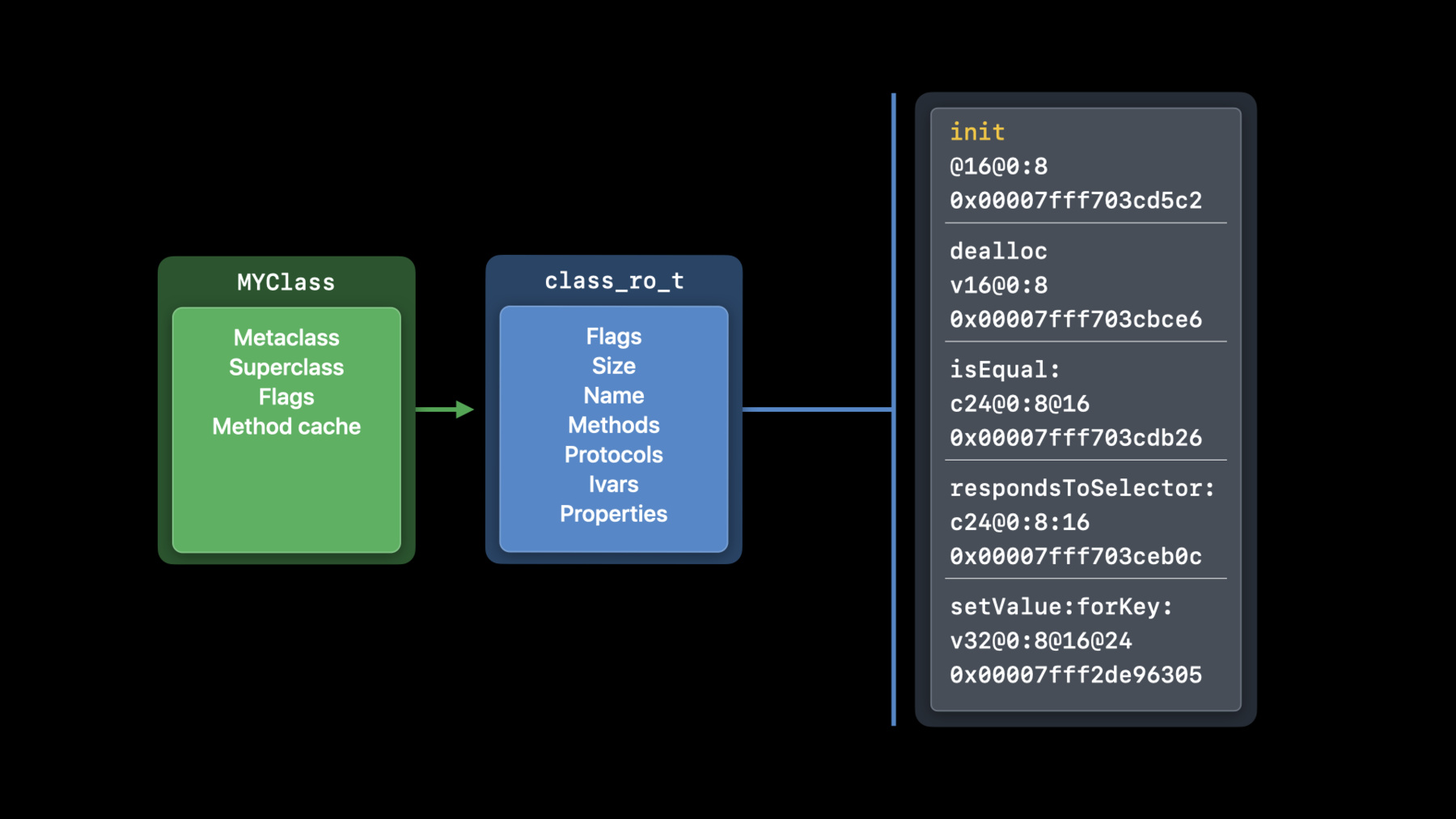
So, let’s start off with changes to the runtime data for classes. On disk, in your application binary, classes look like this.
First, there’s the class object itself, which contains the information that's most frequently accessed: pointers to the metaclass, superclass, and the method cache.
It also has a pointer to more data where additional information is stored, called the class_ro_t. "Ro" stands for read only. And this includes things like the class's name and information about methods, protocols, and instance variables.
Swift classes and Objective-C classes share this infrastructure, so each Swift class has these data structures as well.
When classes are first loaded from disk into memory, they start off like this too, but they change once they're used. Now, to understand what happens then, it’s useful to know about the difference between clean memory and dirty memory.
Clean memory is memory that isn’t changed once it’s loaded.
The class_ro_t is clean because it’s read only.
Dirty memory is memory that’s changed while the process is running.
The class structure is dirtied once the class gets used because the runtime writes new data into it. For example, it creates a fresh method cache and points to it from the class.
Dirty memory is much more expensive than clean memory. It has to be kept around for as long as the process is running.
Clean memory, on the other hand, can be evicted to make room for other things because you if you need it, the system can always just reload it from disk.
macOS has the option to swap out dirty memory, but dirty memory is especially costly in iOS because it doesn’t use swap.
Dirty memory is the reason why this class data is split into two pieces.
The more data that can be kept clean, the better. By separating out data that never changes, that allows for most of the class data to be kept as clean memory.
This data is enough to get us started, but the runtime needs to track more information about each class. So, when a class first gets used, the runtime allocates additional storage for it.
This runtime allocated storage is the class_rw_t, for read/write data. In this data structure, we store new information only generated at runtime.
For example, all classes get linked into a tree structure using these First Subclass and Next Sibling Class pointers, and this allows the runtime to traverse all the classes currently in use, which is useful for invalidating method caches.
But why do we have methods and properties here when they're in the read only data too? Well, because they can be changed at runtime. When a category is loaded, it can add new methods to the class, and the programmer can add them dynamically using runtime APIs.
Since the class_ro_t is read only, we need to track these things in the class_rw_t.
Now, it turns out that this takes up quite a bit of memory. There are a lot of classes in use in any given device. We measured about 30 megabytes of these class_rw_t structures across the system on an iPhone.
So, how could we shrink these down? Remember we need these things in the read/write part because they can be changed at runtime.
But examining usage on real devices, we found that only around 10% of classes ever actually have their methods changed.
And this demangled name field is only used by Swift classes, and isn't even needed for Swift classes unless something asks for their Objective-C name.
So, we can split off the parts that aren't usually used, and this cuts the size of the class_rw_t in half.
For the classes that do need the additional information, we can allocate one of these extended records and slide it in for the class to use.
Approximately 90% of classes never need this extended data, saving around 14 megabytes system wide. This is memory that’s now available for more productive uses, like storing your app’s data. So, you can actually see the impact of this change yourself on your Mac by running some simple commands in the terminal. Let’s take a look at that now. I'm gonna go into the terminal on my MacBook here, and I'm gonna run a command that's available on any Mac, called heap. And it lets you inspect the heap memory in use by a running process. So, I'm gonna run it against the Mail app on my Mac. Now, if I just ran this, it would output thousands of lines showing every heap allocation made by Mail. So, instead I'm just gonna grep it for the types we've been talking about today.
The class_rw_t types. And I'm also gonna search for the header.
And from the results that come back, we can see that we're using about 9000 of these class_rw_t types in the Mail app, but only about a tenth of them, a little over 900, actually needed this extended information. So, we can easily calculate the savings we've made by this change.
This is the type that's halved in size. So, if we subtract from this number the amount of memory we've had to allocate to the extended types, we can see that we've saved about a quarter of a meg of data just for the Mail app. If we extend that system wide, that's a real savings in terms of dirty memory.
Now, a lot of code that fetches data out of the class now has to deal with classes that both do and don't have this extended data. Of course, the runtime handles all of that for you, and from the outside, everything just keeps working like it always did, just using less memory.
This works because the code that reads these structures is all within the runtime, and it's updated at the same time.
Sticking to these APIs is really important because any code that tried to access these data structures directly is going to stop working in this year's OS release since things have moved around, and that code won't know about the new layout. We saw some real code that broke due to these changes, and, in addition to your own code, watch out for external dependencies you might be bringing into your app that might be digging into these data structures without you realizing.
All of the information in these structures is available through official APIs. There are functions like class_getName and class_getSuperclass. When you use these APIs to access this information, you know they'll keep working no matter what we change behind the scenes. All of these APIs can be found in the Objective-C runtime documentation on developer.apple.com.
Next, let's dive a little deeper into these class data structures and take a look at another change, relative method lists.
Every class has a list of methods attached to it. When you write a new method on a class, it gets added to the list. The runtime uses these lists to resolve message sends.
Each method contains three pieces of information.
First is the method's name or selector. Selectors are strings, but they're unique so they can be compared using pointer equality.
Next is the method's type encoding. This is a string that represents the parameter and return types, and it isn't used for sending messages, but it's needed for things like runtime introspection and message forwarding.
Finally, there's a pointer to the method's implementation. The actual code for the method. When you write a method, it gets compiled into a C function with your implementation in it, and then the entry in the method list points to that function. Let's look at a single method. I've chosen the init method. It contains entries for the method name, types, and implementation.
Each piece of data in the method list is a pointer. On our 64-bit systems, that means that each method table entry occupies 24 bytes.
Now this is clean memory, but clean memory isn't free. It still has to be loaded from disk and occupies memory when it's in use.
Now here's a zoomed out view of the memory within a process. Note that it's not to scale. There's this big address space that requires 64 bits to address. Within that address space, various pieces are carved out for the stack, the heap, and the executables and libraries or binary images loaded into the process, shown here in blue.
Let's zoom in and look at one of these binary images.
Here, we show the three method table entries pointing into locations in their binary. This shows us another cost. A binary image can be loaded anywhere in memory depending on where the dynamic linker decides to place it.
That means that the linker needs to resolve the pointers into the image and fix them up to point to their actual location in memory at load time, and that also has a cost. Now note that a class method entry from a binary only ever points to method implementations within that binary. There's no way to make a method that has its metadata in one binary and the code implementing it in another.
That means that method list entries don't actually need to be able to refer to the entire 64-bit address space.
They only ever need to be able to refer to functions within their own binary, and those will always be nearby.
So, instead of an absolute 64-bit address, they can use a 32-bit relative offset within the binary. And that's a change that we've made this year. This has several advantages.
Firstly, the offsets are always the same no matter where the image is loaded into memory, so they don't have to be fixed up after they're loaded from disk.
And because they don't need to be fixed up, they can be held in true read only memory, which is more secure.
And, of course, 32-bit offsets mean that we've halved the amount of memory needed on 64-bit platforms. We've measured about 80MB of these methods system wide on a typical iPhone. Since they're half the size, we save 40 megabytes. That's more memory your app can use to delight your users.
But what about swizzling? The method lists in a binary can't now refer to the full address space, but if you swizzle a method, that can be implemented anywhere. And besides, we just said that we want to keep these method lists read only.
To handle this, we also have a global table mapping methods to their swizzled implementations.
Swizzling is rare. The vast majority of methods never actually get swizzled, so this table doesn't end up getting very big.
Even better, the table is compact. Memory is dirtied a page at a time. With the old style of method lists, swizzling a method would dirty the entire page it was on, resulting in many kilobytes of dirty memory for a single swizzle.
With the table, we just pay the cost for an extra table entry. As always, these changes are invisible to you, and everything keeps working just like it always has. These relative method lists are supported on the new OS versions coming out later this year.
When you build with the corresponding minimum deployment target, the tools will automatically generate relative method lists in your binaries.
If you need to target older OS versions still, not to worry. Xcode will generate the old style method list format as well, which is still fully supported. You still get the benefit from the OS itself being built with the new relative method lists, and the system has no problem with both formats in use in the same app at the same time.
If you can target this year's OS releases though, you'll get smaller binaries and less memory usage.
This is a generally good tip in Objective-C or Swift.
Minimum deployment targets aren't just about which SDK APIs are available to you. When Xcode knows that it doesn't need to support older OS versions, it can often emit better optimized code or data.
We understand that many of you need to support older OS versions, but this is a reason why it's a good idea to increase your deployment target whenever you can.
Now, one thing to watch out for is building with a deployment target that's newer than the one you intend it to target Xcode usually prevents this, but it can slip through, especially if you're building your own libraries or frameworks elsewhere and then bringing them in.
When running on an older OS, that older runtime will see these relative methods, but it doesn't know anything about them, so it will try to interpret them like the old style pointer-based methods.
That means it will try to read a pair of 32-bit fields as a 64-bit pointer.
The result is two integers being glued together as a pointer, which is a nonsense value that is certain to crash if it's actually used.
You can recognize when this happens by a crash in the runtime reading method information, where the bad pointer looks like two 32-bit values smooshed together as in this example.
And if you're running code that digs through these structures to read out the values, that code will have the same problem as these older runtimes, and the app would crash when users upgraded their devices.
So again, don't do that. Use the APIs. Those APIs keep working regardless of how things change underneath. For example, there are functions that, given a method pointer, return the values for its fields.
Let's explore one more change coming this year. A change to the tagged pointer format on arm64.
First, we need to know what tagged pointers are. We're gonna get really low-level here, but don't worry. Like everything else we've talked about, you don't need to know this. It's just interesting, and maybe helps you understand your memory usage a little better.
Let's start by looking at the structure of a normal object pointer. Typically when we see these, they're printed as these big hexadecimal numbers. We saw some of these earlier.
Let's break it out into the binary representation.
We have 64 bits, however, we don't really use all of these bits.
only these bits here in the middle are ever set in a real object pointer.
The low bits are always zero because of alignment requirements. objects must always be located at an address that's a multiple of the pointer size.
The high bits are always zero because the address space is limited. we don't actually go all the way up to two to the 64.
These high and low bits are always zero.
So, let's pick one of these bits that's always zero and make it a one.
That can immediately tell us that this is not a real object pointer, and then we can assign some other meaning to all of the other bits. We call this a tagged pointer.
For example, we might stuff a numeric value into the other bits. As long as we were to teach NSNumber how to read those bits, and teach the runtime to handle the tagged pointers appropriately, the rest of the system can treat these things like object pointers and never know the difference.
And this saves us the overhead of allocating a tiny number object for every case like this, which can be a significant win.
Just a quick aside, these values are actually obfuscated by combining them with a randomized value that's initialized at process startup.
This is a security measure that makes it difficult to forge a tagged pointer.
We'll ignore this for the rest of the discussion, since it's just an extra layer on top. Just be aware that if you actually try and look at these values in memory, they'll be scrambled. So, this is the full format of a tagged pointer on Intel The low bit is set to one to indicate that this is a tagged pointer. As we discussed, this bit must always be zero for a real pointer, so this allows us to tell them apart.
The next three bits are the tag number. This indicates the type of the tagged pointer. For example, a three means it's an NSNumber, a six, that it's an NSDate.
Since we have three tag bits, there are eight possible tag types.
The rest of the bits are the payload. This is data that the particular type can use however it likes.
For a tagged NSNumber, this is the actual number.
Now, there's a special case for tag seven. This indicates an extended tag. An extended tag uses the next eight bits to encode the type, allowing for 256 more tag types at the cost of a smaller payload.
This allows us to use tagged pointers for more types, as long as they can fit their data into a smaller space.
This gets used for things like tagged UI colors or NSIndexSets.
Now, if this seems really handy to you, you might be disappointed to hear that only the runtime maintainer, that is Apple, can add tagged pointer types. But if you're a Swift programmer, you'll be happy to know that you can create your own kinds of tagged pointers. If you've ever used an enum with an associated value that's a class, that's like a tagged pointer. The Swift runtime stores the enum discriminator in the spare bits of the associated value payload.
What's more, Swift's use of value types actually makes tagged pointers less important, because values no longer need to be exactly pointer sized.
For example, a Swift UUID type can be two words and held inline instead of allocating a separate object because it doesn't fit inside a pointer. Now that's tagged pointers on Intel. Let's have a look at ARM.
On arm64, we've flipped things around. Instead of the bottom bit, the top bit is set to one to indicate a tagged pointer.
Then the tag number comes in the next three bits, and then the payload uses the remaining bits. Why do we use the top bit to indicate a tagged pointer on ARM, instead of the bottom bit like we do on Intel? Well, it's actually a tiny optimization for objc_msgSend.
We want the most common path in msgSend to be as fast as possible, and the most common path is for a normal pointer. We have two less common cases: tagged pointers and nil.
It turns out that when we use the top bit, we can check for both of those with a single comparison, and this saves a conditional branch for the common case in msgSend compared to checking for nil and tagged pointers separately.
Just like in Intel, we have a special case for tag seven, where the next eight bits are used as an extended tag, and then the remaining bits are used for the payload.
Or that was actually the old format used in iOS 13. In this year's release, we're moving things around a bit. The tag bit stays at the top, because that msgSend optimization is still really useful.
The tag number now moves to the bottom three bits. The extended tag, if in use, occupies the high eight bits following the tag bit.
Why did we do this? Well, let's consider a normal pointer again.
Our existing tools, like the dynamic linker, ignore the top eight bits of a pointer due to an ARM feature called Top Byte Ignore, and we'll put the extended tag in the Top Byte Ignore bits.
For an aligned pointer, the bottom three bits are always zero, but we can fiddle with that just by adding a small number to the pointer. We'll add seven to set the low bits to one. Remember, seven is the indication that this is an extended tag.
And that means we can actually fit this pointer above into an extended tag pointer payload.
The result is a tagged pointer with a normal pointer in its payload. Why is that useful? Well, it opens up the ability for a tagged pointer to refer to constant data in your binary such as strings or other data structures that would otherwise have to occupy dirty memory.
Now, of course, these changes mean that code, which accesses these bits directly, will no longer work when iOS 14 is released later this year.
A bitwise check like this would've worked in the past, but it'll give you the wrong answer on future OSs, and your app will start mysteriously corrupting user data.
So, don't use code that relies on anything we've just talked about. Instead, you can probably guess what I'm gonna say, which is use the APIs.
Type checks like isKindOfClass worked on the old tagged pointer format, and they'll continue to work on the new tagged pointer format. All NSString or NSNumber methods just keep on working. All of the information in these tagged pointers can be retrieved through the standard APIs.
It's worth noting this also applies to CF types as well.
We don't want to hide anything and we definitely don't want to break anybody's apps. When these details aren't exposed, it's just because we need to maintain the flexibility to make changes like this, and your apps will keep working just fine, as long as they don't rely on these internal details.
So, let's wrap up. In this talk, we've seen a few of the behind-the-scenes improvements that have shrunk the overhead of our runtime, leaving more memory available to you and your users.
You get these improvements without having to do anything except, maybe, consider raising your deployment target.
To help us make these improvements each year, just follow a simple rule. Don't read internal bits directly. Use the APIs. Thanks for watching, and enjoy your faster devices.
-
-
5:37 - Use the heap command to calculate memory savings
heap Mail | egrep 'class_rw|COUNT' -
7:35 - Use the APIs
class_getName class_getSuperclass class_copyMethodList -
14:38 - Use the APIs
method_getName method_getTypeEncoding method_getImplementation -
21:52 - Use the APIs
if ([obj isKindOfClass:[NSString class]]) { // a string } NSUInteger length = [obj length]; if (CFGetTypeID(obj) == CFStringGetTypeID()) { // a string } CFIndex length = CFStringGetLength(obj);
-