-
Sync a Core Data store with the CloudKit public database
Discover how Core Data can help you adopt the CloudKit public database in your app with as little as one line of code. Learn how to easily manage the flow of data through your app and in and out of CloudKit. We'll show you how to combine the complementary power of Core Data and the CloudKit public database to allow people to access — and contribute to — data, such as high scores or application templates.
To familiarize yourself with the CloudKit Database, check out our “CKDatabase” documentation, and to learn more about CloudKit integration, read “Mirroring a Core Data Store with CloudKit.”Resources
Related Videos
WWDC19
-
Search this video…
Hello and welcome to WWDC.
Hi my name's Nick Gillett. I'm an engineer here at Apple on the Core Data team, and today we're gonna talk about what it's like to build applications with NSPersistentCloudKitContainer that sync Core Data stores with the public CloudKit database. To do this, we'll be introducing some new API, and we'll talk a lot about things that you need to think about when building applications for the public database. Finally, we'll take a detailed look at how importing works with NSPersistentCloudKitContainer in the public database. Now before we get started, I'd like to do a quick review of where we are so far. In 2019, in our session "Using Core Data With CloudKit", we introduced NSPersistentCloudKitContainer as a way of easily syncing your Core Data stores with the private CloudKit database. As well, we introduced a new sample application that demonstrates how this works, and we wrote a ton of documentation about how NSPersistentCloudKitContainer works and how you can integrate it with your applications. So, if at any point during this session you feel like you're lacking some context or some of the concepts we're discussing feel foreign, I highly recommend that you review our documentation and our previous session. I also want to review some terms. You see, Core Data and CloudKit are very similar frameworks, and they express themselves through a similar set of ideas and APIs. We think of each framework in terms of objects, models and stores. In Core Data, we know these as instances of NSManagedObject, and these are the objects that you work with directly in your application. Likewise in CloudKit, we know them as CKRecord.
We model these objects or describe them using an instance of NSManagedObjectModel, and in CloudKit, this is called the schema. Finally, objects are persistent, to use the Core Data vernacular, and in an instance of NSPersistentStore, or in CloudKit, in a CKRecordZone which is part of a CKRecord database. Now that we've got that out of the way I want to show you what it's like to actually build an application, or in this case, customize one that works with the public CloudKit database. To do that, I'm just gonna open our sample application, and I'm looking for a specific file called the Core Data Stack. You see the Core Data stack is where this application keeps all of the code it needs to set up its instance of NSPersistentCloudKitContainer. You can see here at the top that it's already using NSPersistentCloudKitContainer, which means it's ready to sync with the private database. Now to make it work with the public database we just want to add one new line of code. I'm simply going to change the existing store description to set its cloudKitContainerOptions and use the new databaseScope property to set it to public.
You can see I've just pasted in a lot of code, so let's take a detailed look at what's actually going on here. In this code we create a new instance of NSPersistentStoreDescription and customize it with the normal cloudKitContainerOptions - things like history tracking and remote change notifications.
Then we create a new instance of NSPersistentCloudKitContainerOptions. This is what tells NSPersistentCloudkitContainer that we want to use this store description with CloudKit. We set its databaseScope property to public, and that tells it that we want to use it with the public database.
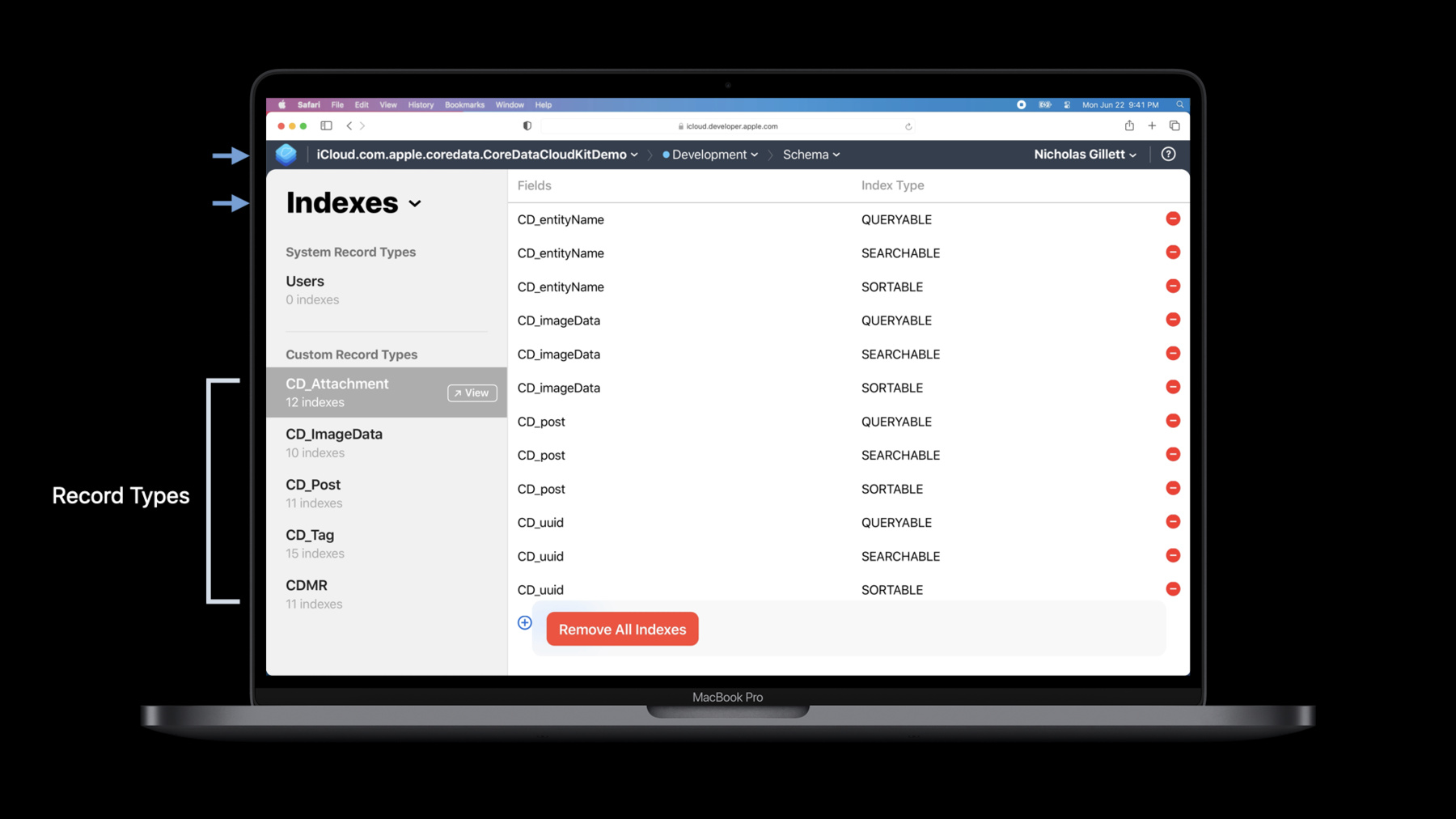
Next, we assign the cloudKitContainerOptions to the store description and append the store description to the array of stores that we want NSPersistentCloudKitContainer to load. Finally, we load our stores as you normally would. Now I would like to say that that's all you have to do at all but we have to configure our CloudKit container to work correctly with NSPersistentCloudKitContainer. You see it fetches data differently in the public database. And so I want to use the CloudKit Dashboard now to change the configuration of our schema. To do that, I'm just gonna open Safari, and you can see that I already have the page I need open in Safari. So let's orient ourselves to where we are. At the top, you can see that I've selected the iCloud container for our sample application, and we're in the development environment looking specifically at the schema. We're looking at the indexes section of the schema because we need to add some indexes to all five of the record types that you see listed on the screen here on the left-hand side. We need to add two new indexes to each record type, and to do that, I'm just going to use this Add Index button down here. I'll click it once and add one for the recordName and then another one for the modifiedAt date, and finally I'll save my changes. And these are the indexes that NSPersistentCloudKitContainer needs to run its queries against the public database to fetch records of this type. Now of course for your application you would have to repeat these steps for all of your record types so we would do this four more times for our sample application. So that's all we have to do to build an application that works with the public CloudKit database. We simply adopt NSPersistentCloudKitContainerOptions' new databaseScope property and add a couple of indexes to all of our record types. Now if you don't see all of your indexes in the CloudKit dashboard, you may need to go through a process that we call schema initialization. And schema initialization is detailed in our documentation and in the session from 2019. Once you finish that, you will have a complete local mirror of all of the data in CloudKit on the device your application is running on. Now you might be wondering why we create a complete local mirror. And the reason is - you asked us to. You see, since our talk in 2019, we've received a slew of feature requests for support with the public database, and they had some common themes. The first being that all of the requests wanted to create a data set that everyone could use - that is, all users of your application could access. Now sometimes this was data that you, the developer, would create, such as an application template or an initial data set so the user has a rich experience with your application from day one. In other cases, it was data created by users. Now I'm going to be candid here. The most common request that we got for this was for a high scores table in a video game, and this is actually a great example of what we want NSPersistentCloudKitContainer to support. You need all the data locally so that you can quickly fetch it, sort it, order it, and it's something that your users will want to contribute to. We also know that you want to mix data from the private database as needed in these applications. And this makes a lot of sense. Your user may want to upload their high score but they may not want to upload their saved game state or their character configuration to the public database. And instead, to sync that, you would use the private database.
And that's actually a great segue to our next section which is special considerations or things that you need to think about as you're building applications that work with the public database. To dig into this a little bit, we're going to compare and contrast the behavior of NSPersistentCloudKitContainer when working with a private database and the public database.
The first thing that we'll look at is the notion of accounts and ownership and how that changes between the two. You see, in the private database, accounts are required and all of the data is owned by a single user so the behavior is fairly straightforward but the public database doesn't work that way. Accounts are optional. You can read data from the public database without an iCloud account, and that data could be owned by any user of your application.
We'll also talk about import and how that changes between the public and private database. You see the private database supports push notifications, and the public database does not, so we have to query for records that we want to import using a process called polling. Now I wanted to call out export here because we won't be talking about it. It works identically between the private and public databases. And we talked about it in detail in our session in 2019. When we think about accounts and ownership, what we're really talking about is the set of actions that your application can take when you're signed in or signed out of an iCloud account. Now as I said, in the private database this is super straightforward. If you're signed out, you can't do anything. If you're signed in, you can do everything. The world is your oyster, and all the data is yours to work with. In the public database though, this gets a lot more complicated. You can read data if you're signed out or signed in but you can only create data - new records - if you're signed into an iCloud account. What about modifications? Well it's tricky. And this poses a problem for applications that have UI's like our sample application. And maybe you have some editing controls such as this Edit button in the top left or this '+' button in the top right that allows us to create new records. Likewise our sample application has a Detail view controller that allows us to edit individual objects and that also has an editing control in it. Our application may need to know whether or not it can use one or any of these controls based on where that object is stored or the database that that object lives in. And it turns out that you can use NSPersistentCloudKitContainer's existing APIs to figure this out. You simply ask CloudKit for the current account. Then you ask NSPersistentCloudKitContainer for the record that backs an object you're working with. And if you compare the creator UserID then you'll know whether or not that object is mutable.
But this is a ridiculous amount of code just to turn this question mark into a yes or no, and it's an insane amount of code to execute for every user interface element in your application. So we can do better. And we have. This is NSPersistentCloudKitContainer's new canUpdateRecord forManagedObjectWithID method, which tells us exactly what we need to know about whether or not this object is mutable with respect to the current configuration of the device, the persistent store the object is kept in and whether or not that store is backed by CloudKit. It even handles all the edge cases you might expect, like that object being stored in a store that's not backed by CloudKit at all or the account changing on the device while you're using your application. And we cache this state so that it's efficient enough to use in your user interface. Now, if you have a more core screen view of the world such as this table view in our application, you can use NSPersistentCloudKitContainer's canModifyObjects in store to tell whether or not any of the objects in a given persistent store would be mutable with respect to the configuration on the device and whether or not that store is backed by CloudKit. Now I'd like to switch gears a bit and talk in detail about how import works in the public database within NSPersistentCloudKitContainer. To do that, I want to review some content from our session in 2019. You may remember this graphic, where we talked about how when we get a push notification from CloudKit, we schedule an import operation that brings all the changed records down to the local store and makes them available to your application.
And this works really well even if you have a large set of changed records or a very complicated object graph. NSPersistentCloudKitContainer can efficiently import complicated graphs and large change sets whether you're using the public database or the private database. To understand how they're different, we want to take a look at exactly what happens between the cloud and the local persistent store. When I say that we create an import operation, what I really mean is that we create an instance of CKFetchRecordsZoneChangesOperation, and this creates a single request against the CloudKit server, which brings down all of the changed records from the private database. But CKFetchRecordsZoneChangesOperation relies on some technologies that are specific to the private database, and so in the public database, we have to use CKQueryOperation instead. Now if you've ever used CKQueryOperation, you know that queries affect a specific record type, which means that we have to make one request for the posts and another request for their tags.. and another request for the attachments... and another request for the images... and another request for the many to many relationships.. and so on. It continues until we fetch all of the record types in our application.
And this means that public database - that stores backed by the public database are doing a lot more work. And that's how we import data into the public database. NSPersistentCloudKitContainer has to use CKQueryOperation instead of CKFetchRecordsZoneChangesOperation, and we have to poll for changes instead of using push notifications to know exactly when to make our requests. Now this means that we need to be careful about how we load up the CloudKit server because of the way we want your applications to scale with the public database.
So we're only going to poll for changes on application launch or after about every 30 minutes of application use. And this is to ensure that we align the load of these requests with the actual usage of your applications.
Of course, this does mean that the quality of freshness that you can expect from the public database will be noticeably different from the private database.
Now I also want to mention that this means that simpler managed object models, that is managed object models that have fewer entities in them, will make fewer requests to the public database. Now that's not to say that you shouldn't have complicated object graphs in your application or that the public database doesn't support them. In fact you absolutely should. You should build the managed object models you need for the public database but it does mean that you should restrict that model to only the entities that are used in the public database so the NSPersistentCloudKitContainer isn't making unnecessary requests. Now we do this using a configuration in the manage object model and we talk about those in detail in our documentation about how you set up a managed object model for use within NSPersistentCloudKitContainer. You want to restrict the entities that are using the public database to a specific configuration for that store. Now why does any of this matter? Well, because the queries affect how deletes propagate throughout the public database. Consider the following set of objects. If we import those objects onto two devices, both devices will come to an identical picture of what's in the cloud, as we would expect. Right? In the private database, if we delete an object from one device and then export that delete to the cloud, that will leave behind a shell, called a tombstone, which contains the record type and the record ID of the object that was deleted.
Now this allows us to fetch that tombstone via CKFetchRecordZoneChangesOperation when we import changes from the private database and delete that record on the other device so both devices again come to the same picture of what's in the cloud. However, as I said, NSPersistentCloudKitContainer can't use CKFetchRecordsZoneChangesOperation with the public database. It has to use CKQueryOperation. So when we delete our record from one device and export that delete to the public database, the record is deleted immediately. With the query operation, we asked the public database what's changed. And it says nothing. There is no tombstone left behind for us to fetch. This means that we can't propagate the delete to the other device, and they will have different pictures of what's in the cloud. And this poses a potential problem for applications, especially if they have user interfaces like this one where we have swipe-to-delete for example in our table view. In swiping to delete this object, that delete won't propagate in the public database to all the devices that have downloaded this object. And it turns out that you can totally detect that this will occur using an API on CKRecordZone called Capabilities.
If a zone doesn't support the fetchChanges capability, we can't use CKFetchRecordsZoneChangesOperation to important data from it. We have to use queries instead. But that takes so much code to integrate into your application that I didn't even bother to put it on slides. Instead, we can detect this in one line of code using NSPersistentCloudKitContainer's new canDeleteRecord(forManagedObjectWithID) method. If it returns false, that means that this record is stored in the public database and NSPersistentCloudKitContainer can't import the delete in the same way that it would from the private database. So the delete won't propagate to all the devices that have downloaded this object. Now that doesn't mean that deletes don't work at all. It's that you need to decide whether or not your application is trying to delete an object or if it's trying to remove one from the UI because NSPersistentCloudKitContainer has to use a CKQueryOperation to fetch it. Now that doesn't mean that you can't delete. In fact, you definitely should delete data when you need to but there's a difference between deleting data for the sake of removing it from the public database and removing it from the user interface in your application. In this code we use canDeleteRecord(forManagedObjectWithID) to tell whether or not we should be updating a record to remove it from our user interface instead of deleting it. To do that we set the isTrashed property on this tag to 'true' when we can't delete something from the public database, and in our application we use a fetch request with a predicate that filters out all the trashed records to remove them from the user interface. In this way we're using an update or a modification in place of a delete to achieve the desired effect in our user interface. Now we can carry this paradigm even further. Say, for example, by milling out all the fields on the record that we no longer need once it's trashed. This preserves... this reclaims space in the public database as well as on disk on your users' devices, and you could go even further by eventually purging these trashed records from the public database once you're confident that all of the users who downloaded these records have processed this update. And so what you really need to decide in your application is - do you want to delete something from the public database so that no one ever downloads it again? Or do you want to pull something out of the UI? In this session, we learned a lot about NSPersistentCloudKitContainer, including its new databaseScope API that allows you to configure whether you want to use a store with a public or private database. And we took a detailed look at what the public database means to your application. Finally, we learned about some other NSPersistentCloudKitContainer APIs and how they can help make some of these considerations easier for you to deal with.
So that's all about NSPersistentCloudKitContainer and the public database.
It's been my pleasure to bring you this session, and from all of us here at Apple, have an amazing WWDC.
-