-
Optimize your use of Core Data and CloudKit
Join us as we explore the three parts of the development cycle that can help you optimize your Core Data and CloudKit implementation. We'll show you how you can analyze your app's architecture and feature set to verify assumptions, explore changes in behavior after ingesting large data sets, and get actionable feedback to make improvements to your workflow.
To get the most out of this session, we recommend familiarity with syncing your data model to CloudKit.Resources
Related Videos
WWDC22
WWDC21
WWDC20
WWDC19
-
Search this video…
Hi, I'm Nick Gillett, an engineer here at Apple on the Core Data team. In this session, I'll show you how to use our developer tools to learn more about your applications that use NSPersistentCloudKitContainer. We'll begin with a detailed look at how to explore applications in a productive and educational way.
Then, we'll use some of my favorite tools to analyze how applications behave. And finally, we'll look at how you can provide detailed, actionable feedback about your experiences with NSPersistentCloudKitContainer.
I like to think of engineering a bit like the water cycle. Typically, I begin working on a feature by exploring the space that feature exists in. Then, based on the things I learn, I use a combination of tools and tests to analyze my work in a reproducible environment.
Finally, I review the results with my peers and coworkers and collect their feedback.
The goal of this cycle is to durably capture the things I learn as I work. Apple platforms include a great selection of tools like Xcode, Instruments, and XCTest that I use to capture what I learn. Those tools also make it possible to collect a wealth of diagnostic information I can use to provide actionable feedback.
This session references a lot of knowledge from years past. I've discussed NSPersistentCloudKitContainer and the Core Data CloudKit Sample application I'll be showing today in detail in the sessions "Build Apps that share data through CloudKit and Core Data" and in the session "Using Core Data with CloudKit." I'll also demonstrate how to use Xcode and Instruments to run tests and the Device organizer to capture data from devices. If you need to, I recommend you review the sessions "Getting Started With Instruments" and "Diagnose performance issues with the Xcode Organizer" to learn more about these two important pieces of the toolchain. All right, let's get started with the first part of the cycle, exploration. For me, the primary goal of exploration is to learn. I want to challenge and verify all of the assumptions I have about how an application will work.
I might ask: What happens if I tap this button? Does NSPersistentCloudKitContainer sync when I save data to a persistent store? Does an application run out of memory when working with a large data set? From Core Data's perspective, all of these questions are influenced by the data an application works with. For example, the Core Data CloudKit sample application uses this data model.
It manages a set of posts which have some text fields for a title and content.
Posts can be related to attachments, generally images, which can be quite large.
The ImageData is therefore stored across a to-one relationship so that it can be loaded on demand. And I'm going to focus my exploration on that data set, specifically what happens to the sample application as I change the shape, structure, and variance of that data.
Since its release, the sample application has included a built-in way to explore it. The Generate 1000 Posts button does exactly what it says on the label.
When tapped, it generates a sample data set of 1,000 posts with a short title. The Posts table view easily handles this level of data. So the next question I would ask is, how can I explore a data set of a different shape or size in this application? The Generate 1000 Posts button runs what I like to call an algorithmic data generator. Algorithmic data generators follow a set of predetermined rules like "insert 1000 objects" or "make sure that every field has a value, or that no fields have values." We, as it turns out, are also data generators. We can hand-craft specific data sets in code, in SQL, or by interacting directly with an application, and these generated data sets can be preserved for later use or analysis.
To explore a larger data set, I can define a new data generator, the LargeDataGenerator, and give it a single method, generateData, to build my new data set. With just two for loops, I can generate a set of 60 posts that each have 11 image attachments associated with them. That's 660 images in total. At an average size of 10-20 megabytes per image, the generated data set consumes almost 10GB of data. With such a simple interface, data generators are easily invoked in tests like this one. This single line of code generates over 10GB of representative data for this test to use.
Additionally, we can build validation methods in the tests that verify the data generator behaves correctly, like asserting that each post does indeed get 11 image attachments.
Of course, this wouldn't be a talk about NSPersistentCloudKitContainer if we didn't sync this data. So let's craft a new test to do just that.
The first thing I'll need is an instance of NSPersistentCloudKitContainer to use. I've created a helper method to make that easy. Next, I use the LargeDataGenerator to populate the container with my desired data set.
And finally, I wait for the container to finish exporting the data. In this specific test, I wait for up to 20 minutes to give the large data set time to upload.
The eagle eyed among you may have noticed that this test appears to be doing a lot of waiting for different types of events. Here, when I create the container, I wait for the container to finish setting up.
And here, I use a helper method I wrote to create XCTestExpectations for an export event from the container.
Let's look at that in detail.
This method takes a desired event type and an instance of NSPersistentCloudKitContainer as an argument. It creates one expectation for each persistent store in the container using XCTestCase's expectationForNotification method to observe NSPersistentCloudKitContainer's eventChanged notification. In the notification handler block, I verify that the incoming event is of the correct type for the specific store this expectation is for, and that it's finished by checking endDate is not equal to nil.
By using this technique, we can strongly associate points of control in our tests with events from NSPersistentCloudKitContainer. Back in my test, I add a new container to import the data that was just exported. This technique uses a trick. It creates a new instance of NSPersistentCloudKitContainer with empty store files. This allows the test to take advantage of NSPersistentCloudKitContainer's first-time import to explore what happens when all of this data is downloaded by a device. Now, tests are great, but sometimes I want to feel how a data set behaves in an application. To do that, I can bind data generators to a user interface, as we have done in the sample application.
When I tap the Generate Large Data button, I can watch the data generator populate the data set. On a second device, I can watch the table view populate as NSPersistentCloudKitContainer makes progress downloading the generated data. Tapping on an individual post allows me to see the attachments download and populate incrementally, just as they would for a user of this application. This specific user interface is driven by an alert controller.
The LargeDataGenerator's simple interface makes it easy to add a new alert action with just these two lines of code. It's clear, concise, and easily understood.
In this section, we've explored the behavior of an application using the concept of a data generator.
Data generators can be driven in our applications any way we choose, whether that be by tests or custom UI, as I've demonstrated, or by something like a command line argument, or anything else that happens to work for your specific use case. Now that we know how to populate an application with data, we're ready to analyze how that changes application behavior. In this section, we'll learn about some tools and techniques to analyze how an application behaves with a large data set.
Specifically, we'll use Instruments to analyze the time and memory complexity of the data set created by the LargeDataGenerator.
Then, we'll look at the wealth of information available to us in the system logs. There we can find a record of activity from NSPersistentCloudKitContainer, CloudKit, the system scheduler, and from push notifications. Let's get stared with Instruments. One reason I love tests is that Xcode makes it easy to analyze the behavior of a test. In my test case, I can right-click on the test disclosure in the gutter and select Profile. Xcode will build the tests and then automatically launch instruments.
I can double-click the Time Profiler instrument to examine where my test spends time doing work.
When I click the record button, Instruments will launch the application and execute the selected test. This test appears to be taking quite a while to run. Let's skip ahead and see why.
Instruments has already selected the main thread, and on the right side, I can see the heaviest stack trace of the test run.
Let's make that a little easier to read.
There we go. Now, if I scroll to the bottom, I can see the LargeDataGenerator is spending a lot of time generating thumbnails. How would we decide if this is a bug or a feature? In the LargeDataGenerator, I have this line of code that generates a new thumbnail for each attachment. However, I know from the application's data model that thumbnails are special. They're computed on demand from the related imageData. That means this line is unnecessary, and my data generator is wasting a lot of time on them. So I can just remove it. Let's see how that changes the performance of the test.
After rebuilding the app with the updated data generator, I can rerun the test in Instruments. And honestly I don't see much of change, but after a few more seconds, the test completes. That's a lot faster than the previous run. Let's see where the test spent most of its time.
In the right drawer, I now see that the heaviest stack trace is saving images to the persistent store, and that's exactly what I would expect for a test that manages this much data.
That one change reduced the runtime of the generateData test from this to this. It executes in one tenth the time. Analyzing tests in this way doesn't always uncover bugs, Sometimes we just learn more about where an application is spending time when working with a specific data set. But either way, though, it's valuable learning.
So that's how the Time Profiler instrument can help explore where an application spends time with a data set. Now, because of the size of this data set, I'm also curious how much memory the test uses. So let's give it a run using the Allocations instrument. I'll use Xcode to launch Instruments to profile my test.
Instead of selecting the Time Profiler instrument, I'll double-click Allocations...
And then click Record.
Even though this test is executing quickly, it’s using a lot of memory, over 10GB, in fact. This tells me that nearly the entire data set is being kept in memory during the test run. Let's find out why.
I can select a range of allocations to look at. In the bottom pane, I can see that there are a number of large allocations.
I can dig into those by clicking this disclosure, and then click on one of the large data blobs that's been allocated for the test. This specific blob was allocated but not freed for almost two seconds. That's an eternity in test time. Why was it alive so long? I can explore that by expanding the stack trace on the right.
From experience, the allocation and deallocation stack trace tell me that this object was faulted by CoreData and then released when the managed object context finished its work. That's usually an indication that the object was retained by a fetch, an autoreleasepool, or an object in the test.
The problematic section of code is here in my verifier. I load an image from an attachment and verify it. However, this keeps the attachment and the associated image data registered with the managed object context.
There are a number of ways we could try to resolve this. For example, in a table view, we could use a batched fetch to free the images as the table scrolls over the posts. However, this test is executing far too quickly for that to be effective. I need to change my approach. Instead of verifying by fetching posts, I can fetch attachments instead. If I also fetch only the objectIDs, the managed object context won't capture any of the loaded objects until I ask it to.
I can use NSManagedObjectContext's objectWithID method to fetch the attachments as I go for validation. Finally, for every 10 attachments I validate, I reset the context, freeing all of the cached state and the associated memory.
If I rerun the test with this change, I can see that it results in a much more predictable and tunable level of memory consumption.
In fact, the verifier uses even less memory than the LargeDataGenerator does when it inserts these objects.
Let's drill down into a specific allocation to learn how the fix works.
First, I'll select a range of allocations to work with. Then, I'll select a specific size to examine, I need to enable destroyed objects to find the ones that were freed during this time, and then I can select a specific allocation to examine.
On the right side, Instruments shows me an allocation stack trace, but I want to know where it was freed, so I'll select the deallocation event. I happen to know that this stack trace means that NSManagedObjectContext is asynchronously deallocating the object that retained this blob, freeing the consumed memory.
This technique allows me to establish a high water mark for the test, enabling it to run on systems with less memory.
By combining tests with Instruments, I've been able to discover that this specific test had some less-than-desirable behavior. I made targeted changes to address that behavior directly and then verify the results. Additionally, the system logs also contain a wealth of information about an application and the system services it depends on, like CloudKit, scheduling, and push notifications.
I'm going to sync a single post between my MacBook Pro and my iPhone. When I insert a new post on my Mac, give a short title, and let it upload to iCloud, the system logs capture a number of events.
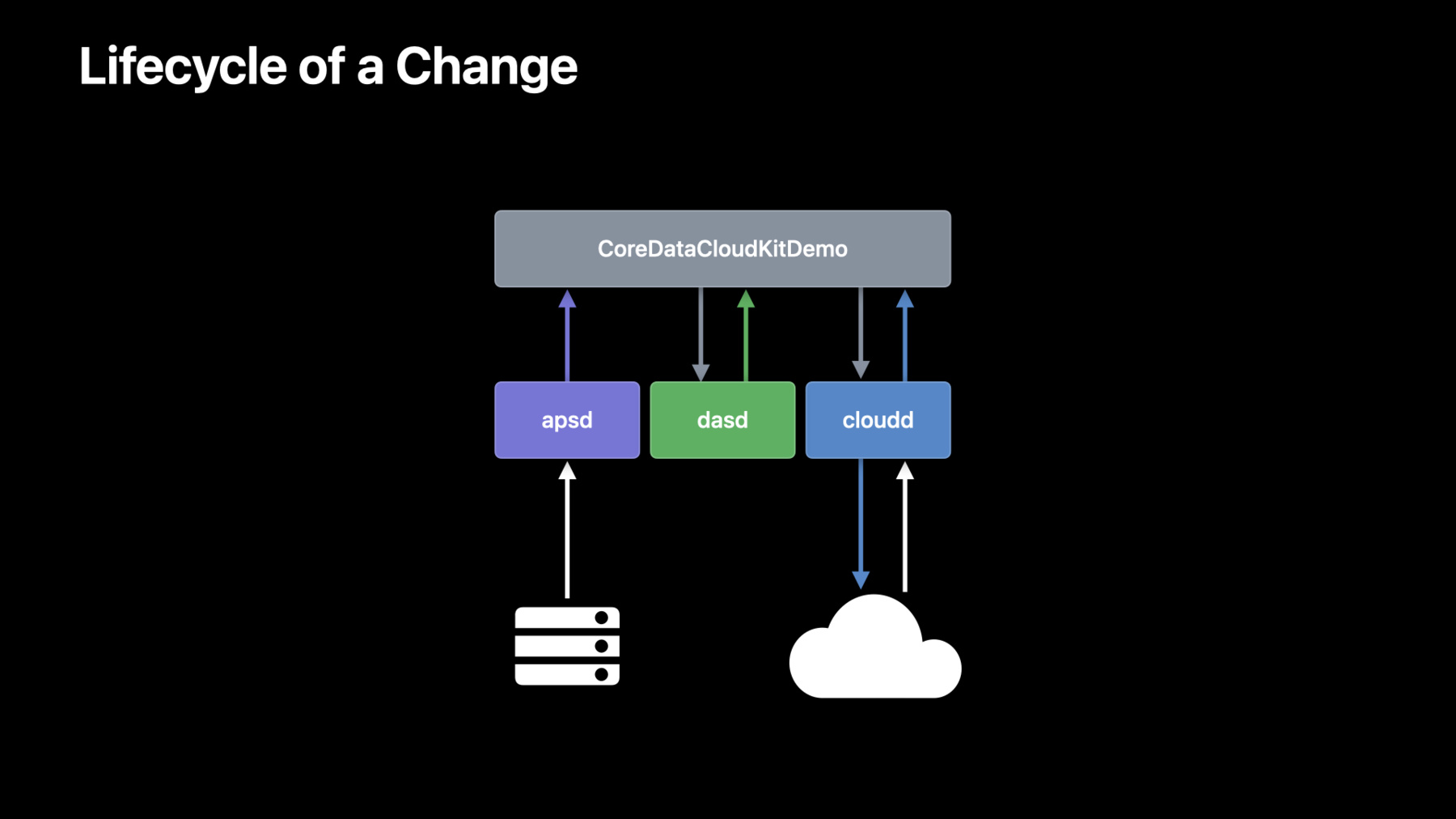
When it syncs to my iPhone, sometimes even capturing intermediate state, the system logs capture a corresponding set of events. On the MacBook Pro, NSPersistentCloudKitContainer does work inside of the application process, in this case, CoreDataCloudKitDemo. When data is written to a persistent store, it asks a system service called DASD if now is a good time to export that data to CloudKit. If it is, DASD will tell NSPersistentCloudKitContainer to run an activity. NSPersistentCloudKitContainer will then schedule work with a process called cloudd to export the changed objects to CloudKit. We can observe logs from each of these processes using the Console app.
For application logs, we simply look for the application process, CoreDataCloudKitDemo. Here, I've selected one that shows an export completing. For scheduling logs, we want to look at logs from the process dasd and from the application's specific store. Here, I've selected the start of an export activity for the application's private store. Let's examine this log in a bit more detail.
Activities created by NSPersistentCloudKitContainer with dasd follow a specific format. The activity identifier is composed of a specific prefix that NSPersistentCloudKitContainer uses along with the store identifier for the store the activity belongs to. The dasd logs include information about how the service decides if an activity can run. Policies that affect the application's ability to do work will be listed in the log along with a final decision.
Finally, the process cloudd logs information from CloudKit, and I like to filter these logs by the container identifier I'm working with. Here I've selected the corresponding modify records operation for the export I mentioned earlier.
When changes are imported on a receiving device, there is one additional process to observe. The process apsd is responsible for receiving push notifications and forwarding them to the application.
That causes NSPersistentCloudKitContainer to initiate a series of activities similar to the export process. It asks dasd for time to perform an import and then works with cloudd to fetch all of the updated objects from CloudKit and import them into the local store.
Apsd logs when it receives a push notification for an application, and this log captures a number of important details.
The log message includes the container identifier here as well as the subscription name and zone identifier that triggered the push notification. These are managed by NSPersistentCloudKitContainer and will always start with the prefix com.apple.coredata.cloudkit.
Now the console app is great. But when I'm developing on my Mac, I like to use the log stream command in Terminal to display these logs alongside my app.
I open one terminal window or tab for each of the following predicates, first the application. Next, the logs from cloudd so I can see what's happening with the CloudKit server. Next, apsd for push notification logs. And finally, dasd so I can see what's happening with activities that NSPersistentCloudKitContainer schedules on my behalf. These predicates can also be used to guide your queries in the console app.
There's so much information available to us on the devices we use. The challenge, really, is knowing what tools to use to find and analyze it. With just Instruments, we can learn about a host of topics like runtime and memory performance and so much more. The system logs capture events that describe the work an application does and what the system is doing for it behind the scenes.
The last phase of my development cycle is collecting and providing actionable feedback. In this section, I'll demonstrate how to collect diagnostic information from devices. Our goal is to use this information to generate feedback that's actionable and aligned with a specific goal. These techniques can help you collect feedback from any device, whether it's one you own or a customer device. There are three steps to gathering diagnostic information from a device. First, we'll need to install the CloudKit logging profile, which enables logs that can be used to identify issues and triage them effectively. Next, we'll collect a sysdiagnose from the affected device. And finally, if we have physical access to the device, we can also collect the persistent store files from Xcode. To install the the logging profile, we simply visit the Profile and Logs page on the developer portal. I can search for the CloudKit profile and tap the profile link to download it. On some devices, a notification will appear to install the profile. However, here on iOS, we'll need to install it manually via the Settings app.
In Settings, I can navigate to tap on the Profile Downloaded cell. Then I can tap on the downloaded profile to install it. Follow the steps to complete the installation. After the profile is installed, the device can be rebooted, and it will take effect.
Once the device has rebooted, we can reproduce the behavior we want to capture and then take a sysdiagnose.
Taking a sysdiagnose is done using a keychord, a special series of buttons. These are described in the instructions page for the profile. I happen to know that for an iPhone, we hold the volume buttons and the side button for a couple of seconds and then release it. After a short while, a sysdiagnose will be available in Settings. The instructions for finding it are included in the instructions file for a profile.
In Settings I navigate to Privacy & Security, Analytics and Improvements, then choose Analytics Data, and scroll through the logs until I find the sysdiagnose.
If I tap on the sysdiagnose and then tap the Share button, I can choose a number of ways to share it.
For example, I like to AirDrop them to my Mac for analysis.
Finally, if possible, I can collect the store files from Xcode using the Device Organizer.
I can collect the files from this iPhone by clicking on the Sample Application in the installed apps list, clicking on the disclosure button, choosing Download Container, and saving that to my Downloads directory.
With all of that done, both the system logs and the store files are now available for analysis. We already talked about the log stream command, but with a sysdiagnose, I can use the log show command to print out logs from the sysdiagnose. Here, I've copied the predicate for the apsd logs we talked about earlier.
The final argument to the log show command is the logarchive to use. If nothing is specified, it will display the system logs from the machine its running on. Here, I have specified system_logs.logarchive so that it reads the logs I took from the sysdiagnose. For example, I can specify a precise time range to focus on the time when an event I'm interested in occurred.
I can also combine many of the predicates we discussed earlier to form a unified log of all the activity relevant to an application, beginning with the application logs here, the cloudd logs here, apsd logs here, and finally dasd logs here.
This powerful command can be included in feedback reports or shared with teammates to allow everyone to focus on a specific set of logs for analysis.
In this session, we talked about how you can explore application behavior with data generators, analyze applications with instruments and the system logs, and provide or collect actionable feedback from applications that use NSPersistentCloudKitContainer.
I'm Nick Gillett, and it's been my pleasure to bring you this presentation. Thanks for watching, stay active, close your rings, and have a great WWDC.
-
-
4:35 - Define a large data generator
class LargeDataGenerator { func generateData(context: NSManagedObjectContext) throws { try context.performAndWait { for postCount in 1...60 { //add a post for attachmentCount in 1...11 { //add an attachment with an image let imageFileData = NSData(contentsOf: url!)! } } } } } -
5:07 - Testing a large data generator
class TestLargeDataGenerator: CoreDataCloudKitDemoUnitTestCase { func testGenerateData() throws { let context = self.coreDataStack.persistentContainer.newBackgroundContext() try self.generator.generateData(context: context) try context.performAndWait { let posts = try context.fetch(Post.fetchRequest()) for post in posts { self.verify(post: post, has: 11, matching: imageDatas) } } } } -
5:33 - Sync generated data in test
func testExportThenImport() throws { let exportContainer = newContainer(role: "export", postLoadEventType: .setup) try self.generator.generateData(context: exportContainer.newBackgroundContext()) self.expectation(for: .export, from: exportContainer) self.waitForExpectations(timeout: 1200) } -
6:35 - Expectation helper method
func expectation(for eventType: NSPersistentCloudKitContainer.EventType, from container: NSPersistentCloudKitContainer) -> [XCTestExpectation] { var expectations = [XCTestExpectation]() for store in container.persistentStoreCoordinator.persistentStores { let expectation = self.expectation( forNotification: NSPersistentCloudKitContainer.eventChangedNotification, object: container ) { notification in let userInfoKey = NSPersistentCloudKitContainer.eventNotificationUserInfoKey let event = notification.userInfo![userInfoKey] return (event.type == eventType) && (event.storeIdentifier == store.identifier) && (event.endDate != nil) } expectations.append(expectation) } return expectations } -
7:18 - Import data model in test
func testExportThenImport() throws { let exportContainer = newContainer(role: "export", postLoadEventType: .setup) try self.generator.generateData(context: exportContainer.newBackgroundContext()) self.expectation(for: .export, from: exportContainer) self.waitForExpectations(timeout: 1200) let importContainer = newContainer(role: "import", postLoadEventType: .import) self.waitForExpectations(timeout: 1200) } -
8:23 - Data generator alert action
UIAlertAction(title: "Generator: Large Data", style: .default) {_ in let generator = LargeDataGenerator() try generator.generateData(context: context) self.dismiss(animated: true) } -
10:50 - Eagerly generating thumbnail in data generator
func generateData(context: NSManagedObjectContext) throws { try context.performAndWait { for postCount in 1...60 { for attachmentCount in 1...11 { let attachment = Attachment(context: context) let imageData = ImageData(context: context) imageData.attachment = attachment imageData.data = autoreleasepool { let imageFileData = NSData(contentsOf: url!)! attachment.thumbnail = Attachment.thumbnail(from: imageFileData, thumbnailPixelSize: 80) return imageFileData } } } } } -
11:13 - Lazily generating thumbnail in data generator
func generateData(context: NSManagedObjectContext) throws { try context.performAndWait { for postCount in 1...60 { for attachmentCount in 1...11 { let attachment = Attachment(context: context) let imageData = ImageData(context: context) imageData.attachment = attachment imageData.data = autoreleasepool { return NSData(contentsOf: url!)! } } } } } -
14:14 - Problematic verifyPosts implementation
func verifyPosts(in context: NSManagedObjectContext) throws { try context.performAndWait { let fetchRequest = Post.fetchRequest() let posts = try context.fetch(fetchRequest) for post in posts { // verify post let attachments = post.attachments as! Set<Attachment> for attachment in attachments { XCTAssertNotNil(attachment.imageData) //verify image } } } } -
14:49 - Efficient verifyPosts implementation
func verifyPosts(in context: NSManagedObjectContext) throws { try context.performAndWait { let fetchRequest = Attachment.fetchRequest() fetchRequest.resultType = .managedObjectIDResultType let attachments = try context.fetch(fetchRequest) as! [NSManagedObjectID] for index in 0...attachments.count - 1 { let attachment = context.object(with: attachments[index]) as! Attachment //verify attachment let post = attachment.post! //verify post if 0 == (index % 10) { context.reset() } } } } -
20:41 - Display logs using `log stream`
# Application log stream --predicate 'process = "CoreDataCloudKitDemo" AND (sender = "CoreData" OR sender = "CloudKit")' # CloudKit log stream --predicate 'process = "cloudd" AND message contains[cd] "iCloud.com.example.CloudKitCoreDataDemo"' # Push log stream --predicate 'process = "apsd" AND message contains[cd] "CoreDataCloudKitDemo"' # Scheduling log stream --predicate 'process = "dasd" AND message contains[cd] "com.apple.coredata.cloudkit.activity" AND message contains[cd] "CEF8F02F-81DC-48E6-B293-6FCD357EF80F"' -
24:36 - Display logs with `log show`
log show --info --debug --predicate 'process = "apsd" AND message contains[cd] "iCloud.com.example.CloudKitCoreDataDemo"' system_logs.logarchive log show --info --debug --start "2022-06-04 09:40:00" --end "2022-06-04 09:42:00" --predicate 'process = "apsd" AND message contains[cd] "iCloud.com.example.CloudKitCoreDataDemo"' system_logs.logarchive -
25:17 - Provide a predicate to `log show`
log show --info --debug --start "2022-06-04 09:40:00" --end "2022-06-04 09:42:00" --predicate '(process = "CoreDataCloudKitDemo" AND (sender = "CoreData" or sender = "CloudKit")) OR (process = "cloudd" AND message contains[cd] "iCloud.com.example.CloudKitCoreDataDemo") OR (process = "apsd" AND message contains[cd] "CoreDataCloudKitDemo") OR (process = "dasd" AND message contains[cd] "com.apple.coredata.cloudkit.activity" AND message contains[cd] "CEF8F02F-81DC-48E6-B293-6FCD357EF80F")' system_logs.logarchive
-