-
Metalによるレイトレーシング
Metal Performance Shaders(MPS)によってGPUの強力な並列処理能力を活用することで、モダンなレイトレーシングおよびレイキャスティングの心臓部となる計算処理を大幅に高速化することができます。このセッションでは、MPSによって動的なシーンの計算がどのように高速化されるかを説明し、ソフトシャドウ、アンビエントオクルージョン、グローバルイルミネーションを実装する方法の実践的な例を紹介します。ハイブリッドレンダリングの適用を有効にする方法と、Appを複数のGPU対応に拡張する新しいテクニックについてご確認ください。
リソース
- Accelerating ray tracing and motion blur using Metal
- Metal Performance Shaders
- Metal
- プレゼンテーションスライド(PDF)
関連ビデオ
WWDC19
-
このビデオを検索
(音楽)
(拍手) こんにちは GPUソフトウェアチームのエンジニア ショーンです このセッションでは レイトレーシングについてお話しします
レイトレーシングAppは 光線の通り道を 追うことを基本としています レイトレーシングのできるAppでは― レンダリング オーディオ 物理的シミュレーションなどができます レイトレーシングは オフラインのレンダリングAppで― シーン内で跳ね返る個々の光線を シミュレートする際に用いられます そうすることでAppは リアルな光の反射や屈折― 影やグローバルイルミネーションを レンダリングできるようになります
最近ではゲームなど リアルタイムのAppでも使われ― 新たな要望も出てきました まず そうしたApp内では オブジェクトが動き回るため― カメラとオブジェクトの運動 双方へのサポートが必要です
パフォーマンスも より重視されます 光線の交差自体を なるべく効率的にし― 限られた光線のバジェットを 有効に使う必要があるということです
そのためサンプリング戦略や 乱数の生成などには気をつけるべきです
最後に 光線を投じても すべてのノイズは取り除けないので― 除去のための精巧な戦略も必要です 幸い Metalはレイトレーシングと ノイズ除去をサポートしています レイトレーシングの話をした後 他のトピックにも触れていきます
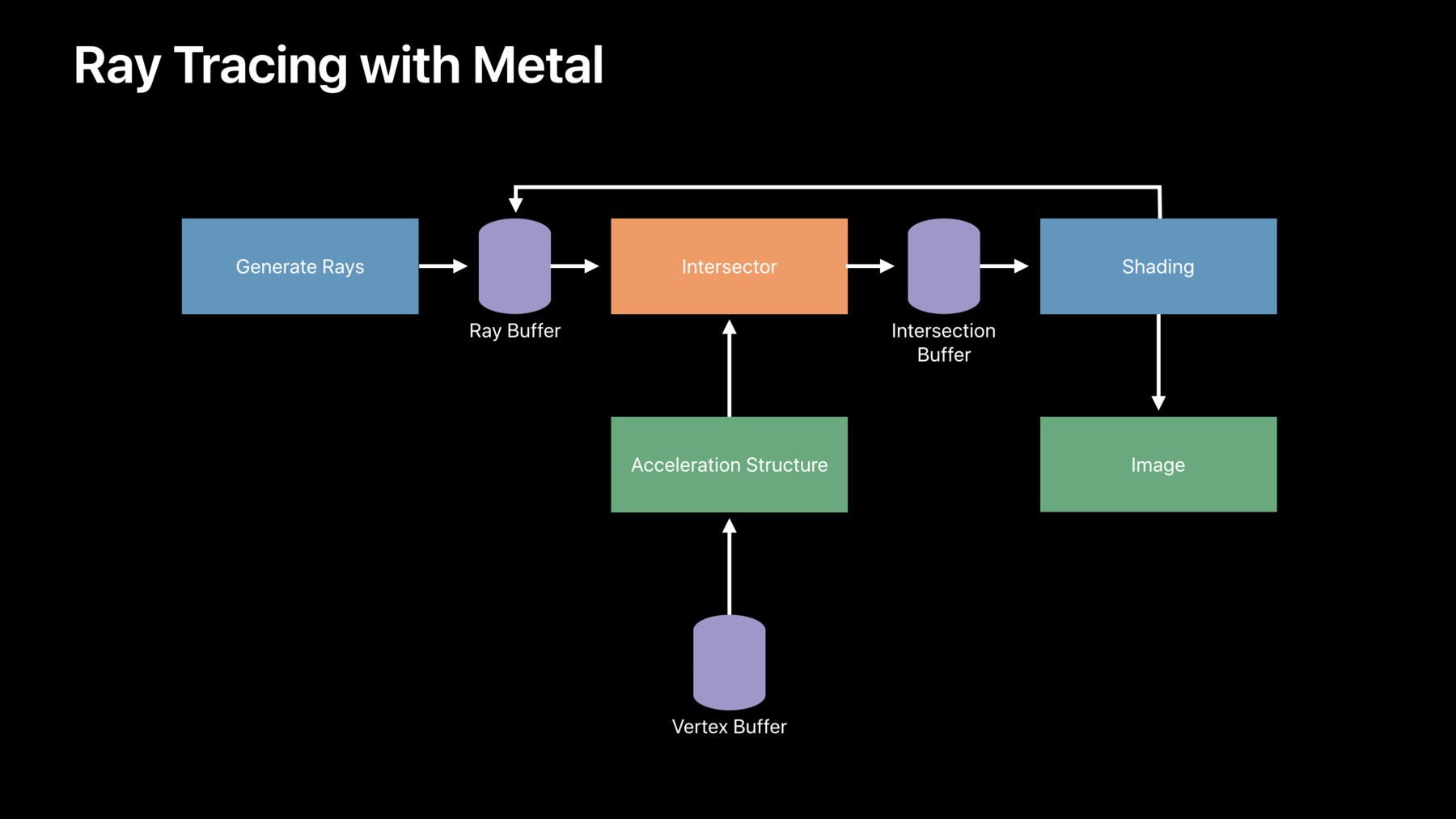
レイトレーシングAppの多くは ほぼ同じアウトラインに沿っています まずは光線の生成です 各光線を決定づけるのは 原点と方向ベクトルです 通常 光線は三角形で構成される シーン内のジオメトリと交差します 交差地点のデータは 単に交差地点までの距離になります しかし大抵は 光が当たった三角形のインデックスや 交点の中心座標など 追加の情報も含まれています
次の段階では 交差した結果を利用します 例えばレンダリングAppでは― イメージ出力のため 陰影を付けるステップになります これは追加の光線を生成する ステップにもなるので― 完成まで 何度でもプロセスを繰り返します
Appでは通常 各フレームのシーンごとに 何百万もの光線を交差させます この交差のステップは どのレイトレーシングAppにもあり― Metalではこれを高速化させています
昨年はMPSRayIntersector APIを 紹介しましたが― これはMetal Performance Shadersの フレームワークの一部です このAPIは MacとiOSの全デバイスで GPUでの光線交差を高速化させています 詳細は昨年 お話ししましたので そちらも ぜひご確認ください このAPIは Metalのバッファを通して 複数のまとまった光線を引き込みます 光線ごとに最も近い交差点を見つけ その結果を別のバッファに返します
これらの作業はMetalのCommandBufferに エンコードされます 場所はApp内の 交差判定をさせたい地点です
多くの場合 高速化は データ構造をビルドして実現しました このデータ構造では 空間内の三角形を再帰的に分割し― 特定の光線と交差しそうにない三角形を 素早く排除できます
Metalでは このデータ構造をビルドしてくれます 加速構造をビルドしたい時間を 指定するだけで― 交差判定をするため Intersectorに構造を通してくれます
これらにかかるコストは Appの起動時に固定でかかります 昨年版のAPIではこのデータ構造は CPU上にビルドされていました 今年は加速構造を GPU上にビルドするようにし― 起動時のコストを劇的に減らしました さらに GPUは必要に応じ 自動的に使用されるので― Appを加速させるために 特定の設定をする必要はありません もう一度 典型的な レイトレーシングAppの話に戻り― MetalのレイトレーシングAppに 変換する方法を確認しましょう
まずは光線の生成から始めます これは通常 カーネルで処理されますが fragmentShaderでも可能です Metalのバッファに書き込める メカニズムならできる Intersectorに 光線のバッファを通すと― 交差地点を見つけ 結果をIntersection Bufferに返します Intersectorを使用するには 加速構造を供給する必要があります 一度 ビルドすれば 何度も使い直せることが多いです 最後にカーネルを起動し― 交差のデータを使用して テクスチャに陰影を付けるのです このカーネルは― 反復するAppのため Ray Bufferに 光線を追加することもできます Appでの使用例を見てみましょう
レイトレーシングがAR Quick Lookで どう使われるかを説明します AR Quick Lookは3Dオブジェクトを 拡張現実内に映し出してくれます 今朝のセッションでも説明したので そちらもご覧ください ここではアンビエントオクルージョンの 効果について見ていきます 詳しいことは後で話しますが シーン内の各地点に到達する光量を 計算する方法のことです その結果 ロボットの下の陰影が 生まれます ロボットの脚と床の間の 薄い影も同様です
機能をオフにし 影を消すと― ロボットが 床から浮いているように見えます ARアプリケーションでは こうした印象を避けることが肝心です
昨年版のAR Quick Lookの影は 事前に組み込まれており― オブジェクトの動きとは 連動していません
今年はMetalのサポートで― 影を同時に動かすレンダリングが 可能になりました オブジェクトが動くと 影も同時に動いています
これはスキニングされたモデルでも 有効です シーン内を泳ぐ魚に合わせ 影も動いています
ご覧いただいたように アニメーションには3タイプあります ラスタライザを使うだけなら 三角形を新しい位置に変換するだけです しかし レイトレーシングを使うなら 加速構造は維持する必要があります
最初のタイプのアニメーションは 単純なカメラの動きです この動作はiPadを動かすだけでいい カメラが動くので 加速構造のアップデートは不要です こうしたアニメーションは 無償で入手できます 新たなカメラポジションから 光線を放てばいいのですが― 他の2タイプは 加速構造のアップデートが必須です その1つがVertexアニメーション 先程の魚のような スキニングされたモデルや― 風に揺れる植物や布などの デフォーメーションに有効です Metalには こうした場合に最適化される 特別な加速構造が含まれています
そして3タイプ目の Rigid Bodyアニメーションでは― オブジェクトが形状を維持したまま 回転したり拡大・縮小します 加速構造の大部分は 実際にはまだ有効ということです またMetalには 変更前の加速構造を 再利用できる仕組みも含まれています Vertexアニメーションについて まず説明します ジオメトリが変われば 加速構造もアップデートが必要です 最初からビルドし直すより いい方法はあります
Vertexアニメーションのオブジェクトは 形状を保持する場合がほとんどです 例えば キャラクターの手は腕 腕は胴体とつながり続けているものです 大抵 加速構造にエンコードされた 空間の階層は有効で― 新たなジオメトリにさえ 適応すればいいということです 例を見てみましょう 先程も見た加速構造です 三角形は 移動すると 境界となっていた箱からズレます しかし階層構造自体は まだ有効です 一からビルドし直すのではなく― 箱を動かし 移動後の三角形の 最上部と最底辺に合わせます
Refittingという動作です 有効な加速構造があれば 得られる結果ですが― 残っていた階層を再利用すれば 一から作り直す必要はありません
すべてGPU上で動いているため― 速いだけでなく Refittingを安全にエンコードできます カーネルが三角形の頂点の情報を 計算し直した後もです
しかし 古いジオメトリを参照するため ジオメトリの追加や削除はできません
これは加速構造の質を低下させ― レイトレーシングの パフォーマンスにも影響します これは元々 三角形が非現実的な形で 不正確に分割されていたためです 影響は小さいはずですが― ジオメトリの転送など極端なケースでは 問題となる場合もあります しかし通常のデフォーメーションや スキニングではとても有効です セットアップの方法を見ましょう まずは 加速構造をビルドする前に Refittingのサポートを可能にします Refittingは加速構造の質を 低下させてしまうので― 本当に修繕が必要な時にだけ 行うようにしましょう MetalのcommandBufferに encodeRefitを呼び出します Vertexアニメーションでは これさえしておけばいい 次に Rigid Bodyアニメーションに ついてです
これは オブジェクトが回転したり 拡大・縮小したりしても― 形状を維持している アニメーションのことです 画面右のロボットは 変形しているように見えますが― 実際は固定された間接部分が 動いているだけなのです これは単なる一例です 多くの場合 ジオメトリは 関節を動かしているだけになります 動かないジオメトリも多くあるのです
シーン内に いくつものコピーがある場合も 加速構造で これらのオブジェクトを 何度もコピーするのはムダですし― 一部のジオメトリに合わせ 構造全体を再調整するのも非効率的です
その解決策となるのが “二層の加速構造”と呼ぶものです
シーン内の特定のオブジェクト向けに triangle加速構造をビルドします Appが起動すれば1回で行えます 次に二層目の加速構造を用い 安価なコピーを作っていきます 元となった triangle加速構造に対し コピーはインスタンスと呼ばれます
各インスタンスは 配置場所を決める 変換行列に関連付けられます 使用するバッファは2つで― シーン内の各インスタンスに対し それぞれに1つのエントリが含まれます 1つ目は 全インスタンスの変換行列を― 2つ目は triangle加速構造の 配列のインデックスを含みます これは各インスタンスに どの加速構造を使うかを示しています
次に シーン内のインスタンスのため 二層目の加速構造をビルドします そうするとオブジェクトの動きに合わせ インスタンスの加速構造を再構築できる セットアップの方法を見ましょう まずAccelerationStructureGroupを 呼び出します インスタンスの階層内にある加速構造は 同グループに属することで― リソースを内部で共有できます
次に triangle加速構造を保持するため 配列を作ります 最後にシーン内のオブジェクトをつなぎ それぞれに加速構造をビルドします 配列に加えながらです
そこで二層目の 加速構造を作るために― MPSInstanceAccelerationStructureを 用います まずはtriangle加速構造の配列を 結びつけます 先程 話した2つのバッファと同様です そして最後にシーン内の インスタンス数を指定します
そうすることでオブジェクトの移動や 追加・削除が行われた際― インスタンスの加速構造を 単純にビルドし直せるのです triangle加速構造よりは 概して小さくなるため― フレームごとに行う余裕も生まれます しかしRefitting同様に オーバーヘッド状態となります シーン内のオブジェクトが少量 もしくは動いていない場合は― 1つのtriangle加速構造に 収めたほうがいいでしょう メモリ・フットプリントは増加しますが パフォーマンスの一部は後退します Appのため 何を妥協点とするかは 試しておきましょう
Vertexアニメーションやスキニングを Refittingでサポートする方法 Rigid Bodyアニメーションの サポート方法も見てきました 次はノイズ除去の話をしましょう
これまでのイメージに ノイズがなかったのは― ノイズを除去するフィルターを 使っていたからです オフにすると本来の様子が分かります 実際のAppで使用するには ノイズが多すぎますね 1ピクセル当たりに使うサンプルが ごく少量だからです 時間をかけ サンプルを増やせば 解決するものの― カメラやオブジェクトが動いていると 話は複雑です 幸い Metalには 高精度のフィルターが含まれています 見てみましょう
レンダラーが出力した ノイズの多いイメージを― Denoiserを通すことで きれいにするのが理想です Denoiserには シーンに関する情報が もう少し必要です まずは目に見えるジオメトリの 奥行きと法線の指定から始めます レンダラーの多くは こうしたテクスチャを持っています
その後 Denoiserが画像処理を実行し よりきれいなイメージを出力します しかし1ピクセル当たりのサンプルは 少量なので― まだ多少のノイズは残っています ここで複数のフレームに渡って サンプルを組み合わせてみましょう 最初のきれいなイメージは 次のフレームで再利用します 次のフレームと比較できるよう 奥行きと法線も置いておきます 最後に 動きベクトルのテクスチャを 用意します 各ピクセルが フレーム間で どれだけ移動したかを表すものです
Denoiserは次のフレームで これらのテクスチャをかき混ぜ― よりよいイメージを作成します カメラやオブジェクトが動いても イメージは どんどんよくなります Denoiserは奥行きと法線を用い― 無効になったピクセルの履歴を 検出しようとします
これらはMPSSVGFクラスを用い 実装されます ノイズを除去する SVGFの 一般的なアルゴリズムは― ハイクオリティとリアルタイムでの パフォーマンスを両立させます MPSSVGFDenoiserクラスがノイズ除去を 調整している一方で― ローレベルなコントロールも MPSSVGFクラスを用いて提供されます このクラスはDenoiserが使用する 個々のカーネルを供給し― App内のノイズ除去を微調整する 多くのパラメータを開示します こうしたメソッドを呼び出すことで カスタマイズしたDenoiserも作れます
Denoiserはノイズ除去の過程で テクスチャの破壊と生成を行うため― MPSSVGFTextureAllocatorの プロトコルは― メモリアロケーションの キャッシュとして機能します デフォルトを実装するか― このプロトコルを実装して Appと メモリを共有させることもできます 我々はMacとiOSの全デバイスのために これらのクラスを最適化しましたが― Denoiserは2つのイメージを 同時に処理することもできます 例えば 直接照明と間接照明を 別テクスチャに分割したいとします アンビエントオクルージョンなど 単独チャンネルのテクスチャへの近道は RBGイメージのノイズを すべて除去するより速いです そのセットアップ方法です
まずはMPSSVGF objectを作成し そのプロパティを設定します 必要なのはノイズ除去に使用したい Metalのデバイスだけです
次に TextureAllocatorを作成 ここでは デフォルトの実装のみを使います 最後に 除去処理を管理する 高レベルのDenoiserオブジェクトを作成 これでノイズを除去できます 入力テクスチャをDenoiserに つなげてみましょう MetalのcommandBufferに ノイズ除去のプロセスをエンコードし 最終的にDenoiserから きれいなイメージを引き出せます それだけでAppの 有効なノイズ除去ができます
Metalにおける 基本的な ビルディングブロックの話をし― MPS Ray Intersector APIを用いた 光と三角形の交差の基本も概説しました Refittingと二層の加速構造を 動きのシーンでどう使うか― MPSSVGFクラスを用いた ノイズの除去方法についても話しました 心配しないでください 使用方法を実演したサンプルを オンラインでご確認いただけます
パフォーマンスに気をつけるという話に 触れましたが― ここでウェインを呼びましょう 現実的なパフォーマンスバジェットで デバイスをどう動かすのかを聞きます (拍手) こんにちは ここで私がお話しするのは― Metalの レイトレーシングの機能を用い― Appにいくつかのレンダリング技術を 実装させる方法です 特に焦点を当てるのが ハードシャドウとソフトシャドウ アンビエントオクルージョンや グローバルイルミネーションです
まずはハードシャドウについて これをレイトレーシングで モデル化するため― 表面上にポイントを付け 光線を太陽に向けて放ちます 光線が何かに当たると ポイントは影に覆われますが― 何もなければ太陽光にさらされます
これを既存のAppにどう組み込むか 仮に このようなものに 着手するとしましょう G-Bufferをラスタライズし 照明のために計算パスを実行 陰影のあるイメージを出力します
レイトレーシングを利用するには G-Bufferを使い― 計算シェーダーを実行して いくつかの光線を生成します
加速構造と共に交差させるため その光線をMetalに通すと― Intersection Bufferに 結果が出力されます シェーディングカーネルで このバッファを使用すると― 表面のポイントを陰で覆うかを 決められます
ここでは主に Ray Generationに着目します まずは光線がMetal内に どう書き込まれるかを思い出しましょう
Metalが供給する光線の構造には 数種あり― ここには 光線の原点と方向を定める フィールドが含まれています 各光線を追跡するため この中の1つの構造に記入し― Ray Bufferに書き出します
Ray Buffer内での光線のアレンジは パフォーマンスに影響します 最初に着手することが多いのが このRow linear orderです
問題は Metalがこれらの光線を通し 作動する時に― データ構造の中で異なる交差点に ヒットしがちだということです ハードウェアのキャッシュを 通り過ぎることもできます
アプローチとしては Block linear orderのほうが適切です 近くのピクセルから近づいた光線は 加速構造の同じ部分に当たりやすい Metalは こうして光線を蓄積したほうが 効率的にハードウェアを駆動できます
ご覧いただいているブロックは 4×4ですが 実際は8×8のほうが うまくいきました
光線の蓄積を最適化すれば パフォーマンスは向上しますが― 光線をまったく放たないのが より望ましい方法です
なぜなら すべてのピクセルに 影を付ける必要がなくなります 例えば背景やスカイボックス 太陽と反対面のピクセルには不要です
Ray Bufferは各ピクセルに対し 光線の構造を含んでいることが多い 不必要に光線を放たないよう Metalに指示する方法が最適です
お見せしている このアプローチでは― 光線の構造のmaxDistanceフィールドに 負の値を設定しています
ハードシャドウでは 知っておくべき点です ご覧のように レイトレーシングの影は 鮮明かつ正確です
しかし実際の影は それほど鮮明では ないこともあります このように影の縁はソフトで 柔らかさは距離と共に変化します 左側を見ると分かりやすいです 街灯の影は 下のほうが濃く― 地面に沿って離れるにつれ 柔らかくなっています
レイトレーシングをモデル化するため 今度は平行する光線ではなく― 表面から太陽に向け 円錐を拡張していきます
この円錐の中でランダムに いくつかの光線を放ってみましょう
ジオメトリと交差しない光線もあります この比率が 影の柔らかさを調整するのです
これを見てください
お見せしているのは直接照明で― 1ピクセル当たり 1本の光線で レイトレースされたものです ここでは反射や グローバルイルミネーションなど― 効果は無効になっているので 影のみに注目できます
かなりノイズが混じっていますね
光線を増やせば対処できますが― それはリアルタイムのAppでは 避けたいことです そこで使えるのが ショーンが説明していたDenoiserです
使った結果 こうなります ほとんどのノイズは除去され― 1ピクセル中 光線1本で これほど柔らかな影を得られました 実際の動作は後ほどお見せします
次はアンビエントオクルージョンです
表面に到達できる周囲の光量を 概算したものです AR Quick Lookのデモで見たように― 地面に接するオブジェクトがある時に 使える技術です
レイトレーシングをすると どうなるか
画面中央に表面のポイントがあります 右側の青いブロックは 遮蔽レンズの役割を果たします 表面のポイントの周囲に半球を定義し いくつか 光線を放ちます
光線が当たったオブジェクトが 環境光の表面への到達を妨げています
何度か述べたように リアルタイムのAppでは― 1ピクセル当たりの光線は 1~2本に制限したい これらの光線は なるべく効率的に使いたいものです
それを行う方法の1つが 重点サンプリングです 普通は最終的なイメージに沿って 光線を放ちます
アンビエントオクルージョンでは 法線に近い光線が最も重要です 光線は半球内で均等に放つのではなく コサインサンプリングを使用し―
水平線の周りに少量の光線 表面の法線に多めの光線を分配します 光線を通したいと思った場所です
この角度のフォールオフに加え― アンビエントオクルージョンには 距離も関係します 表面に近いオブジェクトほど 光を遮る傾向があります 通常のフォールオフの関数は 長さの2乗に比例するものですが―
興味深いのは その関数を 光線の分布に焼き付けられることです これを行うには異なる長さの光線を 投じる必要があります
長さを2乗にする そのフォールアウトの関数が原因で― 光線の大半はかなり短くなります Metalでは光線が短いほうが 加速構造内を追跡しやすくなります
さまざまな形状 さまざまな分配方法で 光線を投じる話をしました ソフトシャドウに使用していた 円錐や― アンビエントオクルージョンで使用した 半球などもそうです
実際には 2Dのパラメータ空間に ポイントを生成することから始め― 任意に光線を分配し その空間に対応付けます
パラメータ空間内のポイントの位置は イメージに大きな影響を与えます ポイントをランダムに選ぶと サンプルポイントがまとまりがちです
しかし同じ方向に投じられた光線は ムダになってしまう
サンプルポイントがない領域も 出てきます アンダーサンプリングもしているため 画質に影響します
サンプルポイントをうまく生成するには 超一様分布列を使用するのです 表示されているのはHalton列
サンプルポイントは 空間内に均等に生成されており― アンダーサンプリングによって 隙間をなくしています
今のは 単一のピクセルに 効率のいい光線を生成する方法でした 今度は画面上のすべてのピクセルに対し 効率のいい光線を生成しましょう
先程 話した超一様分布列から サンプルポイントを取り― 各ピクセルに ランダムなデルタを適用します
各ピクセルは まだ超一様分布列を通っていますが― サンプルポイントの正確な位置は 隣接するピクセルからのオフセットです
これらのデルタを生成するには いくつかの方法があります 1つは乱数だらけのRGテクスチャを サンプリングすることです
レイトレーシングする際 乱数は最適な選択肢ではありません アンビエントオクルージョンの 最適な代替手段はBlue Noiseです
それがこちらです テクスチャはランダムであるがために さらに均等に分布しています 1ピクセルにつき光線が 2~3本でも いい画質が得られます
アンビエントオクルージョンの各結果の 影響を見てみましょう
まずはこれ 全ピクセルに半球のサンプリングと ランダムなデルタを使用したものです
こちらはコサインサンプリングと Blue Noiseを使ったもの イメージを取り換えます どちらも1ピクセル当たり 2本の光線で生成されています 光線をどう使うかを 自ら選ぶことによって― ノイズは劇的に減りました 表面の細部まで 捉えることができています
光線を投じ続ければ― 最終的に2つのアプローチは まったく同じイメージに収束されます しかし重点サンプリングを使用すれば 早くたどり着くことができる
シャドウと アンビエントオクルージョンでは― 光線が何かに当たるかどうかを 気にするだけでした
グローバルイルミネーションのように レイトレーシングの他の効果を得るには シーン内で跳ね返ることを想定し 光線をモデル化します 詳しくはマットがお話しします (拍手)
ありがとう ウェイン
まずはグローバルイルミネーションの 概要から始め― メモリと光線を管理する 最適な方法について話します 最後はレイトレーシングAppを デバッグするための戦略に触れます
グローバルイルミネーションとは?
概念は簡単です 光はシーンに入ると直接 表面に当たり そこを照らしますが― 通常 ラスタライズにおいては これでレンダリングは完了します しかし現実のオブジェクトは光を吸収し 跳ね返る光線はシーン内で動き続けます その跳ね返りによって 興味深い視覚効果も現れます
一度の跳ね返りで見られるのは 右側のボールと壁のような鏡面反射です
鏡面が近いと反射光で オブジェクトや 影が明るくなることも分かります
光は2度 跳ね返ると 鏡面の間で屈折しています 透明なオブジェクトを通り 屈折した光線も いくつかありますが 後ろの面では箱のガラス効果も 確認できます
シーンの周りを跳ね返るすべての光を モデル化しようとすると― カメラには一部しか戻されないので 効率はかなり悪くなります では カメラを逆行させ 光源に向かわせてみましょう カメラからイメージ内のピクセルに向け 光線を投じます
光線の交点は どのオブジェクトを 目視できるかを教えてくれますが― 色を決めるためには 光の到達具合を 判断する必要があります ウェインはソフトシャドウの計算方法を 説明しましたが― ここでも同じプロセスを 実行することになります 交点から光に向けてシャドウレイを投じ 光の到達具合を概算しますが― 最終的なイメージに 光がどう貢献するかを決定づけます
次は 交点から2次的な光線を ランダムな方向に投じます 我々はそれらの光線が何に当たるかを 考えるためにMetalを使い― 最終的なイメージに光を追加します このプロセスを繰り返せば 空間内で跳ね返る光を再現できます このプロセスの進め方については 昨年のセッションをご参照ください
このパイプラインは ハイブリッドなものとは異なります 光線をセットアップし Metalを用いて シーンとの交点を見つけます
交差判定の結果を処理するための シェーダーも書き込みます
次に その交点からシーン内の光に向け シャドウレイを生成 どの光線がどの光に当たっているかを シェーダーに書き込みます 最後に光線が当たった表面を 次の光線の開始位置として使用します このプロセスを繰り返し 光線の跳ね返りをモデル化します
これがグローバルイルミネーションの 仕組みです では このプログラミングモデルと メモリの関係についてお話ししましょう
光線の跳ね返りは 当たるオブジェクトに応じて変わります 赤い物の場合 その表面は 赤の光源色以外のすべてを吸収し― 続いて当たる光線は 赤い光だけを運ぶことになります パイプラインが反復できるよう その情報を追跡する必要があります 光線とシーンのプロパティの追跡には 大量のリソースを割り当てるのです 右側に 追跡したいプロパティの例を いくつか挙げました
新しいバッファを再配置させるには 大量のメモリを使用します 4KイメージのRay Bufferは 単独で250MBです 我々の実演でも1つのレイにつき 80バイト近くを使用しています すぐGPUメモリが いっぱいになってしまいます
光線を小さなグループや タイルにまとめるのも手です 同時に起動する光線の数を制限すれば リソースのメモリ使用量を減らせます
これらのバッファ内のデータは パイプラインの反復中に通されるため 次の段階でそのデータを保存し 読み込むことが大きな制限要因に 4Kイメージでは800万超の光線を 使用しています 1パス当たり 約5ギガバイトの データを読み書きしています
帯域幅の問題の解決策は複数ありますが うまくいった例があります まずはdata bufferに ランダムなインデックスを付けないこと スレッドのメモリは 隣接するバッファ内にあるため― スレッドIDでインデックスを付ければ はるかに効率的です キャッシュコヒーレンシーは 劇的に改善されます 精度を求められない変数については 小さなデータタイプの使用を考えること float型データは 可能であれば 使用を半分に減らしてみてください
それから構造体を分割し 未使用データのロードなどを避けること 例えば 中には材料の特性を含む 構造体もありますが― 透明度の変数を削除すれば パフォーマンスは大幅に向上します 光線は必ずしも 透明な表面には当たらない データの読み書きのせいで 光線が つけを払うべきではない 詳細はGPUのデバッグのセクションで 説明します
原点と方向のデータを格納するため 独自のバッファを割り当てるのは― MetalのRay Bufferを再利用するより 効率的かもしれません Metalの Ray Bufferに 余分なデータが含まれていても― 光線にアクセスし得るシェーダーを 蓄積する必要はないようにしたい
GPUを最大限に活用するには― シェーダー占有率に 注意する必要があります 占有率は大きなトピックなので 詳述はしません しかし占有率に問題があるなら レジスタの圧力を減らすことです シェーダー内に同時に存在する 変数の数も意識しましょう ループカウンターや 関数の呼び出しには注意し― 完全な構造体に こだわらないことです
光線の交点を処理する場合― オブジェクトの表面特性も 評価する必要があります グラフィックAppは通常 テクスチャに 多くのmaterial propertyを格納します オブジェクトが参照するテクスチャに シェーダーがアクセスしようとしても どのオブジェクトに光線が当たるか 事前には分かりません シーン内のあらゆるテクスチャに アクセスする必要が出てくれば― すぐに手に負えなくなる よく使われる Sponza Atriumだと シーン内に76のテクスチャがあります 利用可能なスロット数の2倍以上です 束ねておく場所は すぐに なくなります
これに対処する方法の1つが MetalのArgument Bufferの使用です シェーダーに単一の引数として まとめて割り当てられるリソースですが こちらについては2年前のWWDCの内容を ご参照ください
プリミティブごとに1つの テクスチャがあるとすると― Argument Bufferは テクスチャへの 参照を含む構造体になります テクスチャ参照などを含む Materialという構造体を設定しました
次にArgument Bufferに カーネルを結合させます material構造体の配列として 現れるでしょう
光線が当たったプリミティブの検出には Intersection Bufferを読み―
Argument Bufferに インデックスを付けます これでプリミティブ固有のテクスチャに アクセスできます
メモリの話は以上です 次は光線の寿命の管理についてです
シーン内で跳ね返る光線には イメージに寄与しないものがあります 第一に シーンから消えてしまう場合 実世界とは違い シーンの空間には限りがあり― 一度 出た光線が 戻ってくる方法はありません その際は環境マッピングで 背景色を得るのですが― 光線は事実上 無効になっています
第二に 光線が跳ね返ると― 表面の相互作用によって 運ばれた光が減衰します 光量を失えば 最終的なイメージに 効力がなくなるかもしれません 最後に 表面が透明な場合― その場に閉じ込められる カメラで捉えられない光線が出てきます
光線は どれくらいで動けなくなるか シーンによっては すぐかもしれません このシーンには開かれた世界があり 光線はすぐに出ていってしまいます 右側の簡略図は完全にアクティブな Ray Bufferを示しています パイプラインの最初の反復のために あるかのようです 今はカメラがシーンに向かって 光線を投じる段階です
中には環境マップに当たり アクティブでなくなる光線もあります アクティブでない光線は黄色にし Ray Bufferから削除しました 最初のパスの後もアクティブな光線は 57%しかありません
光線を走らせ続けると― 最初に地面に当たった光線の一部は 跳ね上がり 環境マップに当たります アクティブな光線は 43%まで下がっています
透明なオブジェクトを通り抜け シーン外に出るものもあります 残りは3分の1
当然 繰り返しが続くだけで 光線はアクティブでなくなります
Ray Buffer内で 動かなくなる光線も多く― 処理に費やす時間もムダになる どの光線が非アクティブになるのか 事前には分からないため― Metal Ray Intersectorとシェーダーは すべてに対応する用意をしています スレッドグループメモリを割り当て コンパイラにデータをプリフェッチさせ 制御フローステートメントを 追加する必要があるかもしれません 占有率は変わりませんが― スレッドグループは まばらに利用されます そうしてプロセッサが 浪費されているのです
これを解決するにはRay Bufferを コンパクトにすることです パスごとに Ray Bufferに アクティブな光線を追加していく オーバーヘッドが増えますが― キャッシュラインとスレッドグループは 完全に利用されることになります そのためムダな処理や 必要な情報量が減ります シャドウレイでも同様のことができます 光線の中にはライトから離れた面や 背景に当たっているものがあるので― シャドウレイを キャッシュしたくはありません
Ray Buffer内の光線の位置が 組み替えられる点や― インデックスが一定のピクセル位置に マッピングされていないのは欠点です 各光線とピクセル座標の追跡を始める バッファの割り当てが必要になります 追加のバッファを使用しても― 処理すべき光線が少ない場合 使用するメモリは少なくて済みます
光線を圧縮する際は― 別々のシェーダーが同じ場所に 新たな光線を追加することを防ぎたい そのためパス間では光線に関する 独自のインデックスを作成します それを行うために使うのが atomic counterです AtomicIntegerのoutgoingRayCountには 新しいRay Buffer内の光線が含まれます
“atomic fetch add explicit”を 使い― 現行の光線の値を取得して 1つずつ増やし―
Ray Bufferへのインデックスにすれば 衝突の発生もなくなります これにより アクティブな光線数を outgoingRayCount内に残せます
起動するスレッド数を制限できないなら 光線の圧縮はあまり役に立ちません 作成したoutgoingRayCount Bufferには アクティブな光線の総数が含まれます MTLDispatchThreadGroups IndirectArguments objectにも使えます これはディスパッチで使用される 起動のディメンションを特定します 次に indirectBuffer objectと共に IndirectDispatchを使用すれば― アクティブなままの光線を処理するため 起動しているスレッド数を制限できます
光線を交差させる機能に対応した バージョンもあります
重要なのはバッファを通し 光線数を渡せるという点です それによって光線圧縮の結果を 起動するスレッド数として入力できます
圧縮後 このシーンのパフォーマンスは 約15%向上しました しかしシーンの複雑さや 光線の数によって結果は変わります
それが光線の寿命をカバーし 淘汰をします
それではXcodeを使って Appをデバッグする方法についてです
GPU上でのデバッグは 非常に困難なプロセスですが― レイトレーシングでは特にそうです どのような変更でも 光線ごとに呼び出される可能性がある バッファやテクスチャを捨てるため コードも大量に記載します エラーが出た場所がどこか 各アルゴリズム内を探るためにです XcodeのFrame capture toolsは この種の問題のデバッグに向いています とても強力で時間を節約できます 実世界で遭遇した問題のデバッグ方法を お見せします レイトレースのスーパーサンプリングを 実行した際に起きたことです 私たちは1フレームを複数回 サンプリングする機能を実装しました しかし突然 レイトレーサーが 失敗したイメージを作り出します
まずはAppの実行中に フレームキャプチャをしました ここではAPIの呼び出しと シェーダーのGPUの状態を記録します
任意のシェーダーを選択すれば 結びついたリソースも調べられます そのためシェーダーの失敗も 正確かつ迅速に絞り込むことができます frame bufferに書き込むシェーダーを すべて選択し 直接調べるだけです 最初のイメージはかなり明るいですね 2番目は色あせていて 3番目は 白くなりかかってる
しかし ここでは最も明るいイメージを 出力する シェーダーを選択し― frame bufferを計算するために使用した 2つのinput bufferを見ていきます 最初のバッファは光線が蓄積した 光量の総計しか含んでいません
2番目のバッファには 新しい変数が含まれています これは特定のピクセルを サンプリングした回数です どちらも有効なデータを 持っているように見えるので― シェーダーのデバッガにアクセスし データに何をしているのかを調べます
色計算は ピクセルに対して投じられた すべての光線の輝度を扱います 1ピクセル当たりの光線が1つの場合 これは うまく機能しましたが― 何度もサンプリングしている事実は 補うことができていません シェーダーのデバッガでコードを変更し 総輝度を入力サンプル数で割ります シェーダーのデバッガで再評価すると すぐに出力イメージが修正されました これほど簡単なんです
変更がパフォーマンスに影響する問題も 頻出の課題でした XcodeのFrame capture toolsも 問題に対して同様に対処します 光線の跳ね返りを飛び越え 表面の特性を追跡する構造体の例です シーン内では 表面のすべてが 透明ではない 最後にある 透過率と屈折率の値は 一部の光線には使用されません しかし ここでは全データを 単一の構造体にまとめました 透明な表面に当たらない光線は― フィールドの読み書きをする代わりに ツケを払わされています
ここでは屈折率の変数のインデックスを 独自の構造体にリファクタリングします 構造体を分離することで 透明な表面に当たる光線だけが― 屈折データに触れます
しかし もっとうまくやれるはず 今度はスペース節約のため 全変数をハーフデータ型に変更しました メモリ使用量を40バイトから 20バイトに削減します 透明なオブジェクトに当たらない光線は 12バイトしか必要としません
パフォーマンスには どう影響するでしょう? 変更前後のframe capture toolsを用い GPUトレースを取得します パフォーマンス分析の基本は この段階で行われます キャプチャ前後の シェーダーのタイミングを比較し― パフォーマンスが変化したシェーダーを 分離できるように ラベル付けしたシェーダーが 5.5ミリ秒から4ミリ秒になっています 高価なシェーダーのうち ほぼ30%の節約です
パフォーマンスが向上する理由を 正確に定量化したい場合― Xcodeはframe capture実行時に挿入する 全パフォーマンスのカウンタ結果を表示 メモリ使用量にどう影響したか 気になるので― テクスチャユニットの統計を見ます 平均的なテクスチャユニットの時間は 70%から54%まで失速 L2 Throughputは ほぼ3分の2 削減しました
さらにXcodeは自らの分析をし 潜在的な問題を報告してくれます 元のバージョンはメモリの問題を いくつか抱えていましたが― 新バージョンのパフォーマンスは はるかにいいのです
もう1つ 計算パイプラインの状態にも 興味深いテレメトリがあります MaxTotalThreadsPerThreadgroupを 見てください これはシェーダーの占有を 示しています 1024より少なければ 占有問題を自分で修正できます
それがXcodeでのデバッグです Mac上でのレイトレーシングと グローバルイルミネーション開発は― とても簡単です ではウェインに実演してもらいましょう (拍手) ありがとう
このシーンは別のセッションで 見たかもしれませんね レンダリング用に4つの外付けGPUと MacBook Proを使います スクリーン上のレイトレーシングは すべてリアルタイムなので― 僕はカメラをつかみ シーンの中を動き回ることができます
始めましょう レイトレーシングによる すばらしい影が見えます 接点は濃く 地面から離れるにつれ 影は柔らかくなります
1ピクセル当たり 1光線しか使われていません ショーンが説明していたDenoiserで フィルターもかけています
すべて動的に計算されるので ライトを捉え 動かすことができます その影響はすぐに確認できますね
ここでも大きな効果が見られます 路面電車の窓を見ると こちらの影が反射するんです 僕がライトを動かすと 影も動くのが分かると思います
こちらへ移動すると すばらしい反射効果が見られます
左の路面電車ですが 背後にある電車まで反射しています 背後の電車のフロントガラスにも 反射が見られます 反射しているものが さらに反射している ピクセルごとに2~3の光線の 跳ね返りを計算する必要があります
ズームアウトしましょう 移動できるのは カメラとライトだけではありません 先程 Metalの 二層の加速構造の話が出ました それらを使って 路面電車が 動き回れるようになっています
ぜひ見ていただきたいのが 屋根の上からの照明効果です
右側の壁に焦点を合わせると 直射日光が照っていることが分かります
しかし太陽を回転させると 壁が影に覆われるのが分かります すばらしい間接照明の効果です
ここでは日光が左側の屋根に当たり― 跳ね返って 右側の壁を照らしているのです カラーブリーディングの効果も すばらしい
太陽を動かし続けると 影がドラマチックに出てきて― 屋根の表面を横切っていきます
カメラを少し回転させると 左の屋根への反射も見られます
レイトレーシング効果が いろいろと出ていて いいですね 間接照明 影 反射 MetalとマルチGPUを使った リアルタイムなレイトレーシングです それではマルチGPUの側面について お話しします
(拍手)
今 紹介した マルチGPUの実装方法は― 画面を小さなタイルのセットに 分割し― タイルを 異なるGPUにマッピングしました
ここではタイルの配置を示すため 複数の色を使用しています あるGPUはタイルを赤で表示します 別のものは黄色という具合です 全GPUが完成したら 結果を合成し 最終的なイメージを形成します
少し下がって見てみると 2つの物が飛び出してきます まず最初に左のイメージです タイルをGPUに割り当てると 少し変に見えますが… 理由は何でしょう?
第二に 小さなタイルの意味ですが― 各GPUがピクセルのブロックを 順にレンダリングしようとしています 失敗しそうな気がしますね 光線のコヒーレンシーや キャッシュのヒット率などが怪しい 順番に見ていきましょう
4つのGPUがあると想像してください マルチGPUを簡単に行うには 画面を4分割することです
シーンの一部は他の部分より レンダリングがはるかに簡単になります 例えば 左側の道路と建物が― 右側の路面電車より レンダリングしやすいとしましょう 赤と黄色のGPUが緑と紫よりも 先に終了するのは当然です
これは画面を小さなタイルに分割すれば 修正できます
それをさらに分割していきます 最小になるまで続けます
これにより GPU間で 作業が均等に分散されます 一部のレンダリングが難しくても 問題はないということです その部分から すべてのGPUが タイルに割り当てられるためです
しかし規則的なタイルのパターンは おそらく現実的ではありません タイルがシーンのジオメトリと そろう場合があるからです
そこで ランダム化について もう少し詳しく説明します
このアプローチで面白いのが― GPUへのタイルのマッピングは 変わらないということです 同じGPUがフレームごとに 同じタイルを処理するということです Appの初期化の際 マッピングを計算するだけで済みます ウインドウのサイズを 変更する時でも構いません マルチGPUの負荷分散について 深く考える必要はないのです App内で計算すべきものも ありません
小さなタイルが 仕事を均等に分配するなら― いっそのこと ピクセルにすればいいと思うでしょう
GPUに一貫したブロック状のピクセルを 与える必要が出てきます 代償として 負荷を均等に分配し― 各GPUが効率よく動く必要があります
その代償について理解するため 簡単な実験を行いました Vega II Duo GPUを備えた 新しいMac Proです つまりGPUは計4つですね 同じシーンで タイルをレンダリングし パフォーマンスへの影響も確認しました
これは個人的な意見ですが― パフォーマンスの窓は 非常に広いと実感できました タイルを極端に小さくしたり 大きくすると効率は下がりました 中間であれば どこにいても 最大級のパフォーマンスができます
タイルのサイズが確定しました 次にこれらを さまざまなGPUに割り当てます
そのために各タイルに乱数を生成します それらの乱数を 基準値のセットと比較します どの乱数が入っても それが そのタイルに使用するGPUになります
例えば 0.4という乱数は― GPU 1に割り当てられます 0.55なら GPU 2という具合です
全タイルに乱数を振ったら― 各GPUがレンダリングするのに必要な タイルのリストが出力となります
各GPUに割り当てられた範囲は均等です
そのためGPUにタイルを割り当てる時 全タイルは均等に選択されるはずです
しかし それは理想的とは言えません レイトレーシング以外の目的で GPUの容量を取っておきたいとする ノイズ除去などのためです
別のパフォーマンスで GPUを使うこともあります その場合 強力なタイルを 送信しなければいけません
範囲を調整するだけでも 簡単に計算できます 先程と同じタイルを 再度 割り当てたら― GPU 2が作業の大部分を 占めるようになったことが分かります
実際の実装については― “Metal for Pro Apps”のセッションで 非常に役立つ情報を得られるので― ここでは触れません
しかしパフォーマンスに影響する部分は 強調しておきます
まず ディスプレイを駆動するGPUで タイルを合成したいと思うでしょう それが どのGPUかを 見つけることは重要です データを効率的に取得するには 作業をさかのぼります
GPUが同じピアグループに 属しているなら― 新しいピアグループのAPIを使い それらの間で直接コピーができます それならCPUを見てください
GPU間のデータのコピーは 数ミリ秒かかりますが― 転送が完了するのを 遮りたくはありません
2つのGPUを用い 対処法をお見せします そして そこからタイルを使い 2つのGPUにレンダリングを広げます
最上部のGPU 0には 2つのキューがあります 1つは連続したレイトレーシングに 失敗しました 2番目のキューは完成したタイルを GPU 1に同期をせずにコピーします
下のGPU 1が ディスプレイを 動かしていると想定しましょう ここで事情が変わってきます
このGPUはframe 0の レイトレーシングの一部でもあります タイルが他のGPUからコピーされるまで フレームを表示することはできません
そのため 待たずに 次のフレームから作業を始めます
その後 別のタイルが 他のGPUから届き― ようやくに先に進み すべてをまとめて合成できるようになる もう一度 お見せしましょう
最後に状態は安定し フレームNをレンダリングします “フレームN マイナス 1”を 合成します
レイテンシを隠しています GPU間の 負荷バランスを取るためのタイルは― すばらしいパフォーマンスを 達成させてくれます マルチGPUシステム上の レイトレーシングのためです
セッションは以上です まずは レイトレーシングがMetalで どう機能するかを簡単に説明し― MPSRayIntersectorの いくつかの機能に注目しました それらはダイナミックなシーンに 役立っていました 二層の加速構造や― GPU Accelerated Rebuildsと Refittingの話もしました
MetalのDenoiserも紹介しました レイトレーシングの ユースケースも紹介しましたね シャドウ アンビエントオクルージョン グローバルイルミネーションなどです
Xcodeを用いたレイトレーシングの デバッグ方法もお見せしました 最後はレイトレーシングのAppで 複数のGPUを利用する方法を話しました では developer.apple.comも ご覧ください 今日 お話しした話題の サンプルもあります
レイトレーシングを初めて使うなら 昨年の話もご確認ください この後の 僕らのラボのセッションにも ぜひ ご参加ください
今日は ありがとう またラボでお会いしましょう (拍手)
-