-
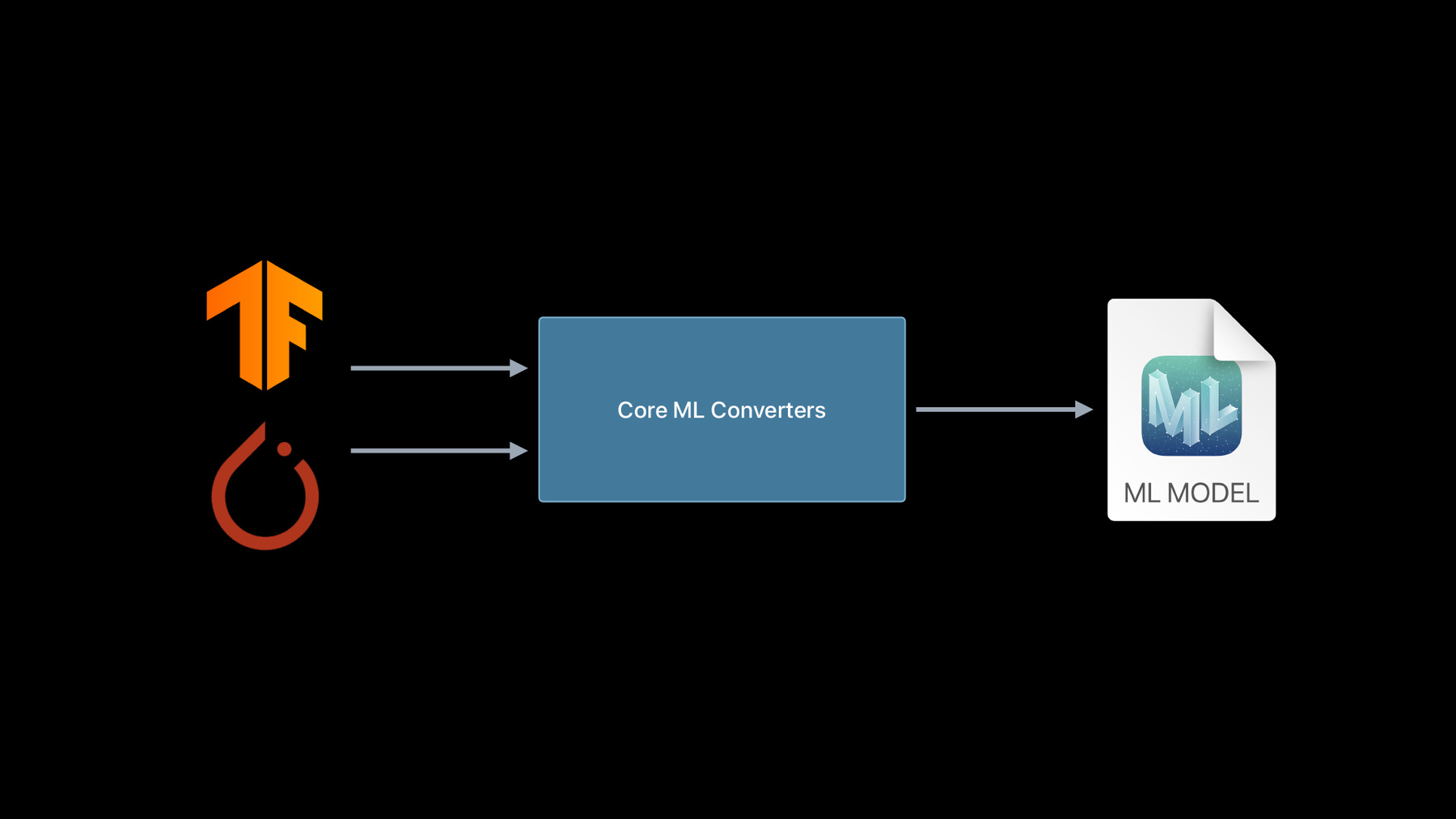
Core ML Convertersを使用したデバイス上のモデルの取得
Core MLでは、驚くような機械学習モデルをAppに持ち込み、完全にデバイス上で実行することができます。また、Core ML Convertersを使用すると、TensorFlowまたはPyTorchのトレーニングを受けたモデルのほとんどを組み込み、GPU、CPU、およびNeural Engineを最大限に活用できます。既存のモデルを他のMLプラットフォームから変換するために必要なもの、およびモデルの機能を拡張するカスタム操作の作成方法について説明します。
モデルをCore MLに変換したら、“Use model deployment and security with Core ML”で、それらのモデルの配置戦略についてさらに学習しましょう。リソース
関連ビデオ
WWDC23
WWDC22
WWDC21
WWDC20
-
このビデオを検索
こんにちは WWDCにようこそ
“Core ML Convertersを使用した デバイス上のモデルの取得” Core MLチームのアシームです ここではCore MLコンバータの 素晴らしい新機能をご紹介します モデルのCore MLへの変換における ユーザー体験の向上に力を入れ 変換ツールを大幅にアップデートしました まず機械学習をAppに統合する上で Core MLが優れたソリューションである理由を 説明しましょう 2017年のCore MLの公開以来― 機械学習モデルを Appに簡単にデプロイできるようにし 幅広く魅力的な体験を生み出すことを 私たちのミッションとしてきました Core MLを使えば同じモデルを すべてのAppleデバイスにデプロイできます 何世代ものOSとデバイスでの互換性と パフォーマンスも保証されています デバイス上のあらゆる ハードウェアアクセラレーションを Core MLモデルではシームレスに活用 CPUやGPU Appleニューラルエンジンも ニューラルネットワークの高速化に特化して 設計されています さらに各新規リリースには Appleの最高のエコシステムを採用 例えば今年は Core MLモデルのデプロイを導入します モデルのアップデートを簡単にするものです 今後はCore MLモデルを 暗号化できるようになります “Model Deployment and Security with Core ML”のセッションで詳細をご覧ください この素晴らしい機能を実現するのが Core MLモデルであり その作成方法がこのセッションのテーマです 深層学習からツリーベースまで 多様な機械学習モデルをCore MLで表現できます 最高のソースはCreate ML Appですが Core ML Tools Pythonパッケージを用いた 使い慣れたフレームワークでも 簡単にMLモデルを作成できます MLエコシステムが成長するにつれ Core MLコンバータがサポートする フレームワークは拡大し続けています 今年はニューラルネットワークライブラリの サポートについても朗報があります これまでフレームワークのニューラル ネットワークモデルの変換に対応してきましたが 今年は深層学習コミュニティで特に人気の 2つのライブラリに注力しています PyTorchとTensorFlowです TensorFlowから見ていきましょう
従来 TensorFlowモデルを Core MLに変換する場合には tfcoremlをインストールし 内部でCore ML Toolsパッケージに依存する APIを使う必要がありました しかし今後はCore ML Toolsだけで実現できます TensorFlowの変換をCore ML Tools内に 完全統合しました TensorFlow 2のサポートも大幅に拡張しています TensorFlow 1は以前から TF Core ML全体でサポートしていましたが 昨年 TF 2の畳み込みモデルの サポートを追加しました 今年は特に動的なモデルの対応を拡大しました LSTMやTransformerなどです
新しいコンバータではTensorFlowモデルを 多様な形式でエクスポートすることが可能です PyTorchからの変換について説明しましょう 従来はPyTorchエクスポートツールで ONNXモデルを作成し ONNX Core MLを用いて MLモデルを使う必要がありました しかし ONNXは独自に進化する オープン標準であるため 最初のエクスポートの段階で 失敗することが多かったのです PyTorchに追加された新機能が欠落していたり トーチエクスポーターが 更新されなかったりしました 今回 この余分な依存関係はなくなりました 新しいPyTorchコンバータを実装したからです 今後はtorch_script_modelから始まる 1段階の処理で済みます
お気づきでしょうか PyTorchコンバータを呼び出すAPIは TensorFlowで使っていたものと同じです 常に1度の呼び出しで すべてのコンバータを 起動するようにAPIを再設計したからです 変換前のモデルのフレームワークに関係なく 機能します
この変更により Core ML Toolsを使えば ワンストップでTensorFlowと PyTorchのモデル変換が可能となったのです 変わったのはAPIだけではありません 新規コンバータパス2点を追加しただけでなく 多大な時間と労力をかけて コンバータアーキテクチャを再設計し ユーザー体験とコードの質を 大きく向上させました 従来は異なるコンバータが 異なる時点で構築された時に 別々のコンバータパイプラインが できていましたが コードを最大限に再利用する 単一のコンバータスタックに変わりました この統合を実現するため 新しいメモリ内表現を導入しました “Model Intermediate Language” 略してMILです MILは変換処理のストリームラインを実行し 新規フレームワークのサポートを 追加しやすくするために設計されています 共通のインターフェイスを提供することで スタックを統合し さまざまなフレームワークから情報を取得します
一連の演算や最適化パス モデルビルダAPIといった情報です エンドユーザは通常MILと相互作用しませんが 状況によっては大変有効です MILについては後で もう少しふれます まずは新しいコンバータの使用例をご覧ください
最初にシンプルな画像分類器を使って 新しい統合APIへの理解を深めましょう Jupyter Notebookに切り替えます さあ 開きました Code ML Toolsをインポートしてあります 最初にTensorFlow 2から変換します こちらもインポート済みです TensorFlow 2 model zooからモデルを取得します
MobileNetモデルを使います 代表的な画像分類畳み込みモデルの1つです 読み込みましょう
そして変換しましょう
必要なのはct.convertを入力し…
TensorFlowモデルオブジェクトを与え Enterキーを打つことだけ
コンバータがモデルの型や入力シェイプ 出力などを自動検出し MILを通して変換し続けます 終わりました 簡単でしょう もう一度やってみましょう 次はPyTorchのモデルを使いましょう
torchとtorchvisionをインポートします 今回はtorchvisionからモデルを取得します MobileNetV2モデルです
Core MLへ変換するには TorchScriptモデルが必要ですが スクリプトかトレースで取得できます ここではトレースを使います
PyTorchの関数を使ってトレースします やってみましょう
まずeval関数を使い推論モードでモデルを取得 続いてjit.traceメソッドを呼び出します 実行させるにはサンプル入力が必要です Enterキーを打ちトレースモデルを取得しました これでCore ML Toolsを使って 変換できるようになりました
再びct.converを入力します 今回はトレースモデルを与えます それからもう1つ 通常 入力シェイプの情報は TorchScriptモデルには存在しませんが 変換にはその情報が必要です 後で入力の型とシェイプを与える 入力引数を使用すれば 情報をコンバータに入れることが可能です TensorTypeクラスを使って行います シェイプを与えます
これだけです Enterキーを打ちます
いつものMILへの変換の工程です 最適化パスが実行され MLモデルへの変換が完了しました MLモデルオブジェクトを表示させて モデルインターフェイスを確認しましょう
“input.1”という入力がありますが ここにTensorTypeを与えたので multiArray型の名前がついています さらに“1648”という出力がありますが 少しおかしいですね なぜかTorchモデルの 出力テンソルの名前がついています コンバータが自動的に そこから取ってきたようです 簡単な処理で分かりやすい名前に変えられます やってみましょう
Core ML Toolsの 名称変更機能ユーティリティを使って 入力と出力の名前を自由に変更します 今回の場合は プレースホルダにします Enterキーを打ち 再びMLモデルオブジェクトを表示させます いいですね 入力と出力の名前が 与えた名前に更新されました
もう一つだけTensorFlow 1から 変換を行います TensorFlow 1環境を設定済みの 別のNotebookを開きましょう MobileNet TensorFlow 1モデルも ダウンロードしておきました これはprotobuf形式になっています このモデルにはlabels.txtファイルが 付属しています ここには モデルをトレーニングした クラス名が含まれています では このモデルを変換しましょう
いつもの変換APIを呼び出し protobuf pbファイルを与えます これで うまくいくはずです でも今回は もう少し手を加えて よいCore MLモデルを作りましょう
先ほど TensorTypeを使いましたが このモデルは画像処理が得意なので コンバータにそれを伝えられたらいいですね ct.ImageTypeクラスを使い そこに 前処理パラメータを与えれば実現できます RGB画像の各チャネルに biasと―
scaleを入れます
これで MobileNetモデルが予期したとおりに 画像が正規化されます
もう一つ変更したい点があります このモデルは分類を行いますから Core MLモデル分類器を生成してみましょう ClassifierConfigを使えばそれも可能です labels.txtファイルを変更せずに与えるので 便利ですよね Enterキーを打ちます
完了しました モデルをディスクに保存しましょう でもその前に ライセンスと作成者に関する 有用なメタデータを追加します mlmodel.saveを入力してモデルを保存します
モデルの名前はmobilenet.mlmodelにします
ディスクに入りました Finderでモデルを確認します モデルがあるのでクリックして開きましょう 自動的にXcodeで開きます 今年 XcodeのUIをアップデートしました 分類器については クラスラベルがここに表示されています ご覧のとおり このモデルには 1000のクラスがあります Previewという新しいタブが実に便利で とても気に入っています ここに画像をいくつかドラッグ&ドロップします すると モデルが自動的に画像を処理し 予測を表示します モデルは非常に上手に 画像を処理しているようです では変換APIのデモを終えます さまざまなモデル型の変換関数を呼び出し その機能を確認しましたが 今度は もう少し複雑なモデルを 変換してみましょう ここで 同僚のGiteshが 音声をテキストに変換するモデルを 変換してくれます ありがとう Core MLチームのエンジニア Giteshです このデモでは 新しいCore ML Tools変換APIで 柔軟なシェイプと関連機能を 自動的に処理する方法を説明します デモには 自動音声認識タスクを使用します このタスクでは 入力は音声ファイルで 出力はその文字起こしです 自動音声認識を実装するには 多くの方法があります 今回の例で使うシステムには 3つの段階があります 前処理と後処理の段階 そして その間にあるのが 重労働を処理する ニューラルネットワークモデルです
前処理には RAW形式の音声ファイルから MFCCとも呼ばれるメル周波数を 抽出する作業が含まれます このMFCCをニューラルネットワークモデルに 入力すると 確率分布の文字レベルでの時系列を返します 次に CTCデコーダで後処理をされ 成果物の書き起こしを生成します 前処理と後処理の段階には 簡単に実装できる標準的な技術を用います そして このモデルを 中心で変換することに集中します トレーニング済みのTensorFlowモデル DeepSpeechを使います 高いレベルでは このモデルは 長・短期記憶として使われています そしていくつかの高密度レイヤは 互いに重なり合っています このようなアーキテクチャは seq2seqモデルでは非常に一般的です 早速 Jupyter Notebookを開き このモデルをCore MLに変換し 音声サンプルを使って試してみましょう まず パッケージをいくつかインポートします このMozillaのGitHubリポジトリの中に DeepSpeechモデル用の トレーニング済みウェイトがありました 既にそのウェイトとスクリプトをダウンロードし TensorFlow 1モデルを そのリポジトリからエクスポートしました スクリプトを実行しましょう
protobuf形式のTensorFlowグラフを凍結しました このグラフの出力を見てみましょう そのために 既に検査ユーティリティを記述済みです
このモデルは4つの出力があります 最初の“mfccs”は 処理前段階の出力を表しています つまり エクスポートしたTensorFlowグラフには DeepSpeechモデルだけではなく 前処理のサブグラフも 含まれているということです 残りの3つの出力名を 統合コンバータ関数に与えて この前処理コンポーネントを取り除きましょう この情報を使って Core MLコンバータを呼び出してみます
変換が成功しました では この変換したモデルを 音声サンプルで実行します 最初に 音声ファイルを読み込んで再生します
“昔むかし 爆発する鶏が” “黄金の虎と落ち合って 一緒に 緑の森の中を歩いていきましたとさ” 次に 前処理を行います このNotebookで 完全なパイプライン処理を実行するため 先にDeepSpeechのリポジトリを使って 前処理 後処理の関数を構築しました
この前処理は 音声ファイルを このシェイプのテンソルオブジェクトに 変形させます すると シェイプが 1つの音声ファイルとして表示されます 前処理により それぞれ幅19で26の係数を含む 636のシーケンスになっています シーケンスの数は音声の長さによって変わります この12秒間の音声ファイルには 636のシーケンスがあります では モデルが予測する 出力シェイプを検査しましょう
このモデルの最初の入力は ほぼ正しいシェイプです 1つだけ異なるのは 1回に16シーケンスを処理できることです そこで ループを記述して 出力機能をチャンクに分け― セグメントごとに1つずつモデルに入力します 書いておいたコードをここにペーストしましょう このコードをそっくりまねる必要はありません 基本的には ループ内のいくつかの状態管理で 前処理機能をサイズ16のスライスに分割し スライスごとに予測を実行します では実行してみましょう
非常に正確な書き起こしに見えますね よい出来です ただ 前処理した機能全体に対して 1発で予測を実行できたら 便利ですよね 実は それは可能です 動的TensorFlowモデルが必要です DeepSpeechリポジトリの同じスクリプトに戻り 動的グラフを取得しましょう 今回は さらに “n_steps”というフラグを与えます このフラグはシーケンス長に対応していて 初期値は16です ただ ここで-1を設定します そうすれば シーケンス長は正の値を取れます 新しくTensorFlowモデルを用意しました 変換しましょう
変換が完了しました 先ほどのモデルとどう違うのか検査をしましょう
このCore MLモデルは 任意のシーケンス長の入力で 機能するところが異なっているようです 違いはシェイプだけではありません 表面下では この動的Core MLモデルは 先の静的モデルよりもはるかに複雑です シェイプの取得 動的なリシェイプなど 膨大な動的処理を行っています それでも 変換の作業は一切変わりません これまでと同じ程度の操作で コンバータが対処してくれました では 同じ音声ファイルで モデルを検証しましょう
今回は ループは必要ありません 入力機能全体を直接モデルに与えます 実行してみます
今回の書き起こしも完璧です これまでDeepSpeechモデルの 2つのバリアントを使いました 静的なTensorFlowグラフ上で コンバータは 固定シェイプの入力を持つ Core MLモデルを生成しました そして 動的バリアントを使って あらゆるシーケンス長の入力を受け入れる Core MLモデルを取得しました コンバータは両方の事例を透過的に処理し 変換の呼び出しに変更を加えることもありません デモの中でお見せできなかったことがあります 動的TensorFlowモデルで 静的なCore MLモデルを取得できるのです 手順を説明します まず Typeディスクリプションオブジェクトを
入力の名前と
シェイプで定義します
それから このオブジェクトを 変換APIに入力します
以上です 内部では タイプと値の推論によって シェイプ情報が伝わり 不要な動的操作がすべて削除されています したがって 静的モデルの方が実行可能性が高く 動的モデルの方が柔軟性があります
どちらを使うべきかはAppの要件次第です ここでは Core MLへの 変換の成功事例を見てきました しかし サポート外の処理エラーが 発生する場合もあります 最近 実際にこんな問題にぶつかりました お見せしましょう Transformerと呼ばれる自然言語モデルの このライブラリを調べていました そして T5という最新モデルを見つけました 変換しましょう まず ライブラリから トレーニング済みのモデルを読み込みます オブジェクトの戻りは tf.kerasモデルのインスタンスなので
直接 Core MLコンバータに渡せます
すると “Einsum”の操作で サポートされていない処理エラーが起きます では Aseemに この問題解決の方法を探ってもらいます それから このモデルの変換に戻ります 進化し続ける機械学習空間において エラーに対応していくのは大変なことです なぜなら TensorFlowやPyTorchには 常に新しい処理が追加されていますし 自分で作成したものを使う場合もあるからです この場合はどうしたらよいでしょうか 1つは Core MLカスタムレイヤを使って MLモデルに独自の迅速な処理を実装することです これはよい方法ですが もっと簡単な策がある場合も多いです いわゆるcomposite opを使うのもいいでしょう これはSwiftコードを 書き加える必要がありません MLモデルファイルにすべて バンドルになっているからです composite opは 既存のMIL演算から作られています MILとは何か そしてそれを使い― どうやってcomposite opを構築するのかを 詳しく見ていきます コンバータスタックを統合する 中間言語モデルを開発しました 展開して内部を見ると このスタックは3つのセクションでできています フロントエンド 中間MILポーション そしてバックエンドです 各ソースフレームワークには 個別のフロントエンドがあり フレームワーク固有の表現をキャプチャします その後 MILプログラムが構築されます この時点で表現ソースに依存しない状態です 多くの一般的な最適化パスがここで実行されます 演算子の結合 デッドコード削除 定数伝播などです その後グラフはprotobuf MLモデル形式に シリアル化されます 別の説明として 各ソースフレームワークに 独自のDialectがあり これは統合ポイントとしてMILに変換され MLモデルになります これは コンバータが行う MIL形式移行の1つの方法です しかし ビルダAPIを使って 直接MILプログラムを記述する方法もあります MILはスタンドアロンの言語で ニューラルネットワークモデルを 直接表現する際に使えます また このAPIは TensorFlow 2 PyTorchのいずれのユーザであれ 多くの人が精通しているAPIとよく似ています このビルダAPIを見てみましょう PythonでMILプログラムを書く方法を説明します ビルダをインポートし シェイプを指定して 入力を定義します この場合は 1, 100, 100, 3です Printを呼び出せば プログラムの記述を表示できます 下の記述では 入力の型はFloat32と推定されました これは初期設定の型です では 1つ目の演算を追加します シンプルな構文でReLuの処理を追加しました 今回は転置行列の演算をもう一つ追加しましょう MILビルダの優れた点は タイプとシェイプの推論を 即座に実行することです 転置行列の出力のシェイプが 下の記述で正しく更新されました 最後の2つの軸に リダクション演算を追加してみましょう 期待どおり テンソルのシェイプが1, 3になっています もう一つだけ演算を追加しましょう ついに プログラムがlog演算の出力を返しました MILでネットワークを定義するAPIは 非常にシンプルなのが分かります では それを使ってcomposite opを実装し サポート外のエラーを回避する方法を確認します これについてはGiteshが説明します T5モデルを変換し Einsumのサポート外の 処理エラーに遭遇しました TensorFlowドキュメントを読むと Einsteinの 総和の表記方法について触れられています reduce_sum transpose traceなど 多くの演算子が この文字列を使った表記法で表現できます 今回の変換では このモデルが使用する 表記法に注目します エラーのトレースを見ると このモデルでは この表記で Einsumを使用していることが分かります それは 次の数式に変換できます 複雑に見えますね しかし 事実上 これは2番目の入力による転置を伴う― バッチ処理された行列乗算に過ぎません MILがこの処理を直接サポートしているので とても便利です ではcomposite opを記述します まず MILビルダと装飾子をインポートします
そして TensorFlowのエナンと同じ名前で 関数を定義します この場合は Einsumです 次に この関数を装飾して コンバータに登録します これにより 変換中に Einsumの処理が検出される度に 必ず正しい関数が起動します
最後に 入力を取得し MatMul演算をMILビルダで定義します Core MLコンバータをもう一度呼び出しましょう
変換が完了しました 成功したか確かめるには MLモデルを出力してください
完璧です まとめです T5モデルを変換していると サポート外のEinsumの処理エラーが起きました 一般的には Einsumは複雑な処理であり さまざまなテンソル演算で表されますが どのような場合も懸念は要りませんでした ただ このモデルに必要な 特定のパラメータ化に対応しました composite opを使えば それも簡単に実装できました 要約すると Core ML Toolsには 多くの新機能が盛り込まれました 強力な型推論や ユーザフレンドリーなAPIなどによって Core MLコンバータはさらに使いやすく 拡張性も高まりました 以上の機能について詳しくは 新しいドキュメントをご覧ください このセッションを含む事例も掲載しています 最後に 新たなPyTorchコンバータと TensorFlow 2のサポート拡張について お伝えしました 新しい統合APIを通じて利用でき MILを介して実現しました
皆さん ぜひ試してみてください いただいたフィードバックによって Core ML Toolsを改善していきます ありがとうございました
-
-
2:58 - TensorFlow conversion using tfcoreml
# pip install tfcoreml # pip install coremltools import tfcoreml mlmodel = tfcoreml.convert(tf_model, mlmodel_path="/tmp/model.mlmodel") -
3:16 - New TensorFlow model conversion
# pip install coremltools import coremltools as ct mlmodel = ct.convert(tf_model) -
3:57 - ONNX conversion to Core ML
# pip install onnx-coreml # pip install coremltools import onnx_coreml onnx_model = torch.export(torch_model) mlmodel = onnx_coreml.convert(onnx_model) -
4:28 - New PyTorch model conversion
# pip install coremltools import coremltools as ct mlmodel = ct.convert(torch_script_model) -
4:52 - Unified conversion API
import coremltools as ct model = ct.convert( source_model # TF1, TF2, or PyTorch model ) -
6:42 - Demo 1: TF2 conversion
import coremltools as ct import tensorflow as tf tf_model = tf.keras.applications.MobileNet() mlmodel = ct.convert(tf_model) -
7:41 - Demo 1: Pytorch conversion
import coremltools as ct import torch import torchvision torch_model = torchvision.models.mobilenet_v2() torch_model.eval() example_input = torch.rand(1, 3, 256, 256) traced_model = torch.jit.trace(torch_model, example_input) mlmodel = ct.convert(traced_model, inputs=[ct.TensorType(shape=example_input.shape)]) print(mlmodel) spec = mlmodel.get_spec() ct.utils.rename_feature(spec, "input.1", "myInputName") ct.utils.rename_feature(spec, "1648", "myOutputName") mlmodel = ct.models.MLModel(spec) print(mlmodel) -
10:37 - Demo 1 : TF1 conversion
import coremltools as ct import tensorflow as tf mlmodel = ct.convert("mobilenet_frozen_graph.pb", inputs=[ct.ImageType(bias=[-1,-1,-1], scale=1/127.0)], classifier_config=ct.ClassifierConfig("labels.txt")) mlmodel.short_description = 'An image classifier' mlmodel.license = 'Apache 2.0' mlmodel.author = "Original Paper: A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, "\ "T. Weyand, M. Andreetto, H. Adam" mlmodel.save("mobilenet.mlmodel") -
13:33 - Demo 1 Recap: Using coremltools convert
import coremltools as ct mlmodel = ct.convert("./tf1_inception_model.pb") mlmodel = ct.convert("./tf2_inception_model.h5") mlmodel = ct.convert(torch_model, inputs=[ct.TensorType(shape=example_input.shape)]) -
15:45 - Converting a Deep Speech model
import numpy as np import IPython.display as ipd import coremltools as ct ### Pretrained models and chekpoints are available on the repository: https://github.com/mozilla/DeepSpeech !python DeepSpeech.py --export_dir /tmp --checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=alphabet.txt --scorer_path=kenlm.scorer >/dev/null 2>&1 ls /tmp/*.pb tf_model = "/tmp/output_graph.pb" from demo_utils import inspect_tf_outputs inspect_tf_outputs(tf_model) outputs = ["logits", "new_state_c", "new_state_h"] mlmodel = ct.convert(tf_model, outputs=outputs) audiofile = "./audio_sample_16bit_mono_16khz.wav" ipd.Audio(audiofile) from demo_utils import preprocessing, postprocessing mfccs = preprocessing(audiofile) mfccs.shape from demo_utils import inspect_inputs inspect_inputs(mlmodel, tf_model) start = 0 step = 16 max_time_steps = mfccs.shape[1] logits_sequence = [] input_dict = {} input_dict["input_lengths"] = np.array([step]).astype(np.float32) input_dict["previous_state_c"] = np.zeros([1, 2048]).astype(np.float32) # Initializing cell state input_dict["previous_state_h"] = np.zeros([1, 2048]).astype(np.float32) # Initializing hidden state print("Transcription: \n") while (start + step) < max_time_steps: input_dict["input_node"] = mfccs[:, start:(start + step), :, :] # Evaluation preds = mlmodel.predict(input_dict) start += step logits_sequence.append(preds["logits"]) # Updating states input_dict["previous_state_c"] = preds["new_state_c"] input_dict["previous_state_h"] = preds["new_state_h"] # Decoding probs = np.concatenate(logits_sequence) transcription = postprocessing(probs) print(transcription[0][1], end="\r", flush=True) !python DeepSpeech.py --n_steps -1 --export_dir /tmp --checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=alphabet.txt --scorer_path=kenlm.scorer >/dev/null 2>&1 mlmodel = ct.convert(tf_model, outputs=outputs) inspect_inputs(mlmodel,tf_model) input_dict = {} input_dict["input_node"] = mfccs input_dict["input_lengths"] = np.array([mfccs.shape[1]]).astype(np.float32) input_dict["previous_state_c"] = np.zeros([1, 2048]).astype(np.float32) # Initializing cell state input_dict["previous_state_h"] = np.zeros([1, 2048]).astype(np.float32) # Initializing hidden state probs = mlmodel.predict(input_dict)["logits"] transcription = postprocessing(probs) print(transcription[0][1]) -
21:52 - Deep Speech Demo Recap: Convert with input type
import coremltools as ct input = ct.TensorType(name="input_node", shape=(1, 16, 19, 26)) model = ct.convert(tf_model, outputs=outputs, inputs=[input]) -
26:26 - MIL Builder API sample
from coremltools.converters.mil import Builder as mb @mb.program(input_specs=[mb.TensorSpec(shape=(1, 100, 100, 3))]) def prog(x): x = mb.relu(x=x) x = mb.transpose(x=x, perm=[0, 3, 1, 2]) x = mb.reduce_mean(x=x, axes=[2, 3], keep_dims=False) x = mb.log(x=x) return x -
28:20 - Converting with composite ops
import coremltools as ct from transformers import TFT5Model model = TFT5Model.from_pretrained('t5-small') mlmodel = ct.convert(model) # Einsum Notation $$ \Large "bnqd,bnkd \rightarrow bnqk" $$ $$ \large C(b, n, q, k) = \sum_d A(b, n, q, d) \times B(b, n, k, d) $$ $$ \Large C = AB^{T}$$ from coremltools.converters.mil import Builder as mb from coremltools.converters.mil import register_tf_op @register_tf_op def Einsum(context, node): assert node.attr['equation'] == 'bnqd,bnkd->bnqk' a = context[node.inputs[0]] b = context[node.inputs[1]] x = mb.matmul(x=a, y=b, transpose_x=False, transpose_y=True, name=node.name) context.add(node.name, x) mlmodel = ct.convert(model) print(mlmodel) -
29:50 - Recap: Custom operation
@register_tf_op def Einsum(context, node): assert node.attr['equation'] == 'bnqd,bnkd->bnqk' a = context[node.inputs[0]] b = context[node.inputs[1]] x = mb.matmul(x=a, y=b, transpose_x=False, transpose_y=True, name=node.name) context.add(node.name, x) -
29:50 - Deep Speech demo utilities
import numpy as np import pandas as pd import tensorflow as tf from tensorflow.python.ops import gen_audio_ops as contrib_audio from deepspeech_training.util.text import Alphabet from ds_ctcdecoder import ctc_beam_search_decoder, Scorer ## Preprocessing + Postprocessing functions are constructed using code in DeepSpeech repository: https://github.com/mozilla/DeepSpeech audio_window_samples = 512 audio_step_samples = 320 n_input = 26 audio_sample_rate = 16000 context = 9 lm_alpha = 0.931289039105002 lm_beta = 1.1834137581510284 scorer_path = "./kenlm.scorer" beam_width = 1024 cutoff_prob = 1.0 cutoff_top_n = 300 alphabet = Alphabet("./alphabet.txt") scorer = Scorer(lm_alpha, lm_beta, scorer_path, alphabet) def audiofile_to_features(wav_filename): samples = tf.io.read_file(wav_filename) decoded = contrib_audio.decode_wav(samples, desired_channels=1) spectrogram = contrib_audio.audio_spectrogram(decoded.audio, window_size=audio_window_samples, stride=audio_step_samples, magnitude_squared=True) mfccs = contrib_audio.mfcc(spectrogram = spectrogram, sample_rate = decoded.sample_rate, dct_coefficient_count=n_input, upper_frequency_limit=audio_sample_rate/2) mfccs = tf.reshape(mfccs, [-1, n_input]) return mfccs, tf.shape(input=mfccs)[0] def create_overlapping_windows(batch_x): batch_size = tf.shape(input=batch_x)[0] window_width = 2 * context + 1 num_channels = n_input eye_filter = tf.constant(np.eye(window_width * num_channels) .reshape(window_width, num_channels, window_width * num_channels), tf.float32) # Create overlapping windows batch_x = tf.nn.conv1d(input=batch_x, filters=eye_filter, stride=1, padding='SAME') batch_x = tf.reshape(batch_x, [batch_size, -1, window_width, num_channels]) return batch_x sess = tf.Session(graph=tf.Graph()) with sess.graph.as_default() as g: path = tf.placeholder(tf.string) _features, _ = audiofile_to_features(path) _features = tf.expand_dims(_features, 0) _features = create_overlapping_windows(_features) def preprocessing(input_file_path): return _features.eval(session=sess, feed_dict={path: input_file_path}) def postprocessing(logits): logits = np.squeeze(logits) decoded = ctc_beam_search_decoder(logits, alphabet, beam_width, scorer=scorer, cutoff_prob=cutoff_prob, cutoff_top_n=cutoff_top_n) return decoded def inspect_tf_outputs(path): with open(path, 'rb') as f: serialized = f.read() gdef = tf.GraphDef() gdef.ParseFromString(serialized) with tf.Graph().as_default() as g: tf.import_graph_def(gdef, name="") output_nodes = [] for op in g.get_operations(): if op.type == "Const": continue if all([len(g.get_tensor_by_name(tensor.name).consumers()) == 0 for tensor in op.outputs]): output_nodes.append(op.name) return output_nodes def inspect_inputs(mlmodel, tfmodel): names = [] ranks = [] shapes = [] spec = mlmodel.get_spec() with open(tfmodel, 'rb') as f: serialized = f.read() gdef = tf.GraphDef() gdef.ParseFromString(serialized) with tf.Graph().as_default() as g: tf.import_graph_def(gdef, name="") for tensor in spec.description.input: name = tensor.name shape = tensor.type.multiArrayType.shape if tensor.type.multiArrayType.shapeRange: for dim, size in enumerate(tensor.type.multiArrayType.shapeRange.sizeRanges): if size.upperBound == -1: shape[dim] = -1 elif size.lowerBound < size.upperBound: shape[dim] = -1 elif size.lowerBound == size.upperBound: assert shape[dim] == size.lowerBound else: raise TypeError("Invalid shape range") coreml_shape = tuple(None if i == -1 else i for i in shape) tf_shape = tuple(g.get_tensor_by_name(name + ":0").shape.as_list()) shapes.append({"Core ML shape": coreml_shape, "TF shape": tf_shape}) names.append(name) ranks.append(len(coreml_shape)) columns = [shapes[i] for i in np.argsort(ranks)[::-1]] indices = [names[i] for i in np.argsort(ranks)[::-1]] return pd.DataFrame(columns, index= indices)
-