-
高速リンク:ビルドと起動時間の改善
Appでのビルドやランタイムのリンクパフォーマンスを向上させる方法をご確認ください。Appのリンクパフォーマンスを向上させるリンキング、オプション、最新情報について、舞台裏をご紹介します。
リソース
関連ビデオ
WWDC23
WWDC22
-
このビデオを検索
♪ ♪
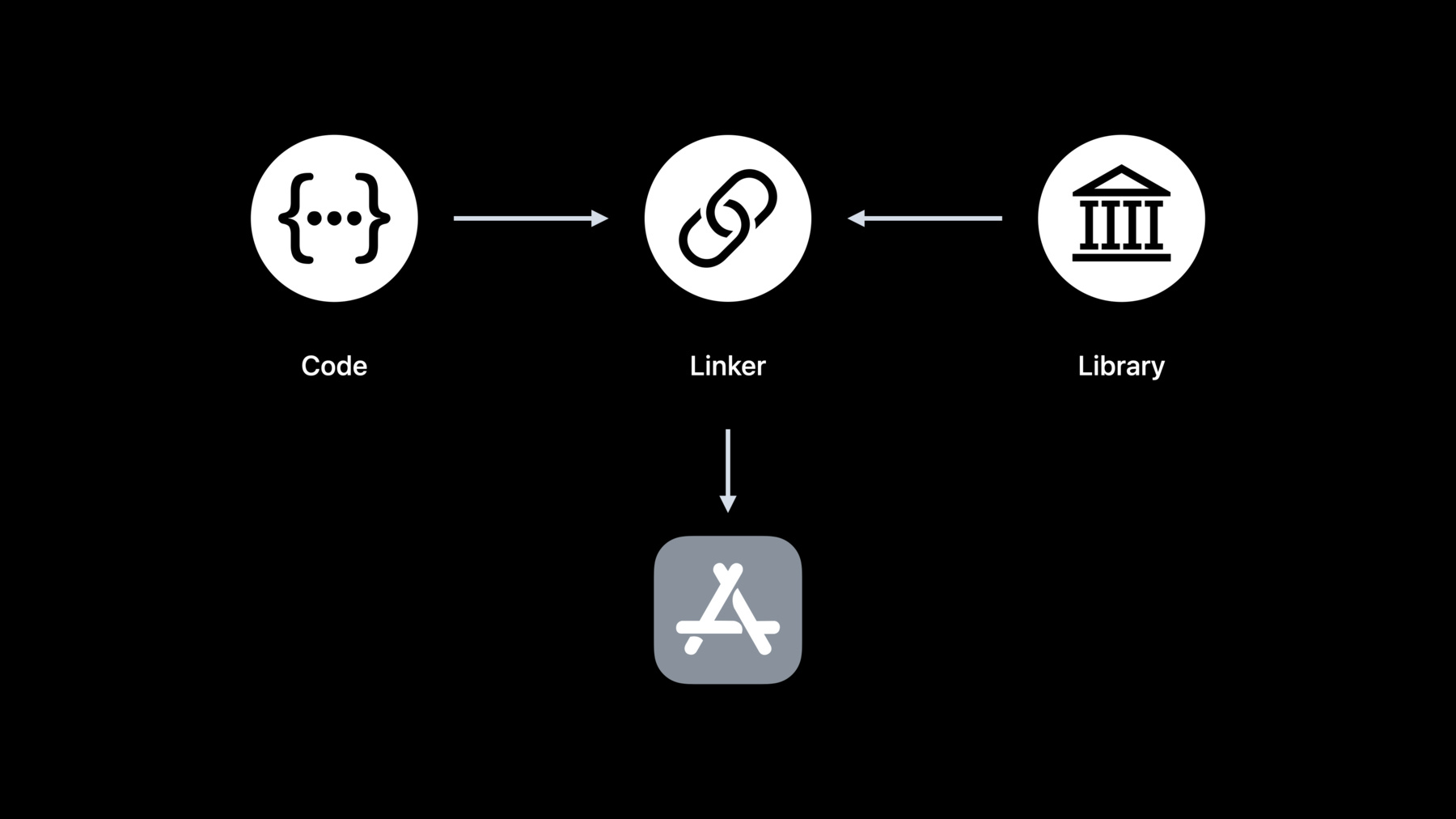
こんにちは Linkerチームの リードエンジニアのNick Kledzikです 今日は 高速なリンクの方法を 紹介したいと思います Appleがリンクを 改善するために行ったこと そしてリンク時に実際に 何が起こっているかを理解し Appのリンクパフォーマンスを 改善するヒントをご紹介します では リンクとは 何でしょう? みなさんは自分でコードを書き 他の誰かが書いたコードも ライブラリやフレームワーク の形で使っていますね みなさんのコードがこのライブラリを 使うには リンカが必要です リンクには 実は 2つの種類があります Appをビルドする際に発生する 「スタティックリンク」です これは Appのビルド時間や Appの最終的な大きさに 影響を与える 可能性があります そして「ダイナミックリンク」です これは Appが起動したときに 発生します よって 顧客がApp起動までの待ち時間に 影響を与える可能性があります この回では スタティックリンクと ダイナミックリンク 両方をお話します まず スタティックリンクとは何か そしてその由来を いくつかの例を 挙げて定義します 次に Appleのスタティックリンカ であるld64の新機能を公開します 次に このようなスタティックリンクの 背景を踏まえて スタティックリンクの ベストプラクティスを詳しく説明します 後半は ダイナミックリンク について説明します ダイナミックリンクとは何か どこから来たのか ダイナミックリンク中に何が起こって いるのかを紹介します 次に 今年のdyldの 新情報をお伝えします 続いて Appのダイナミックリンク 時間のパフォーマンスを 向上させるために できることをお話しします そして最後に カーテンの裏側を覗くのに役立つ 2つの新ツールを ご紹介します バイナリに何が入っているのか ダイナミックリンク時に 何が起こっているのかを 確認ができるようになります スタティックリンクを理解するため その始まりに 話を戻しましょう 当初 プログラムはシンプルで ソースファイルは1つだけでした ビルドも簡単でした 1つのソースファイルに対し コンパイラを走らせ 実行プログラムを 生成しただけです しかし 全ソースコードを 1つのファイルに まとめても スケールアップにはつながりません 複数のソースファイルを 使ってビルドする方法は? 単に大きなテキストファイルを 編集したくないだけではありません ビルドのたびにすべての 関数を再コンパイルする 必要はありません 彼らは コンパイラを 2つに分けました まずはソースコードを 新しい中間的な 「リロケータブルオブジェクト」 ファイルにコンパイルします 次に リロケータブルな .oファイルを読み込んで 実行可能な プログラムを生成します ここでは 2番目の部分を「ld」 スタティックリンカと呼ぶことにします これで スタティックリンクの由来が わかったと思います ソフトウエアの進化に伴い .oファイルの受け渡しが行われました しかしそれが 面倒くさくなったのです 一連の.oファイルを 「ライブラリ」に パッケージングできたら と考えたのです 当時 ファイルを束ねるには アーカイブツール 「ar」を使うのが標準でした バックアップや 配布に使われました そこで ワークフローは こうなりました 複数の.oファイルをアーカイブに 「ar」することができ リンカはアーカイブファイルから 直接.oファイルを読み出す方法を 知るために 強化されています これは 共通のコードを共有 するための大きな改善点でした 当時はライブラリやアーカイブ と呼ばれていました 現在では スタティックライブラリ と呼んでいます しかし最終的なプログラムには ライブラリから何千もの関数がコピーされ たとえそのうちいくつかのみが 使われるだけであっても 大きなものになってしまいます そこで 巧妙な 最適化が加えられます リンカはスタティックライブラリの 全.oファイルを使用する代わり 未定義のシンボルが 解決される場合のみ スタティックライブラリの .oファイルを使用します 誰かが大きなlibc.aという スタティックライブラリを作り そこにCの標準ライブラリの 関数を全部入れれば良いのです どのプログラムも1つの libc.a とリンクができましたが 各プログラムは必要とする libc の部分のみを取得できます 私たちは今日も このモデルを採用しています しかし スタティックライブラリから 選択的にロードすることは分かりづらく 多くのプログラマを つまずかせます スタティックライブラリの選択的 読み込みをもう少しわかりやすくするため 簡単なシナリオを 用意しました main.cでは mainという関数があり fooという関数を呼び出します foo.cには barを呼び出す fooがあります bar.cでは barの実装と同時に 使われていなかった 別の関数の実装もあります 最後にbaz.cの中に undefという関数を 呼び出すbazという関数があります 次に それぞれを独自の .o ファイルにコンパイルします foo bar undefは 未定義なので グレーのボックスが ないのがわかると思います つまり シンボルの使用であって 定義ではありません bar.oとbaz.oを組み合わせ スタティックライブラリにしましょう 次に2つの.o ファイルと スタティックライブラリをリンクします 何が起こるのか 順を追って見ていきましょう まず リンカはコマンドライン順に ファイルを処理します 最初に見つかるのはmain.oです 最初に見つけるのは シンボルテーブルにある main.oです しかし mainが未定義の「foo」 を持つことも発見されました 次にリンカは コマンドラインの 次のファイルであるfoo.oを解析します このファイルでは 「foo」の定義を追加しています つまり fooは 未定義ではなくなります しかしfoo.oをロードすると 「bar」の未定義シンボルが追加されます コマンドライン上のすべての .oファイルがロードされたので リンカは未定義のシンボルが 残っていないかをチェックします この場合「bar」は 未定義のままなので リンカはコマンドラインで ライブラリの検索を開始し 不足している未定義シンボル「bar」 を満たすライブラリがあるか確認します リンカはスタティックライブラリの bar.oが「bar」を定義することを発見します そこでリンカはアーカイブから bar.oをロードします その時点で未定義の シンボルはなくなり リンカはライブラリの 処理を停止します リンカは次の段階へ進み プログラムに含まれる すべての関数とデータに アドレスを割り当てます すべての関数とデータを 出力ファイルにコピーします できました!出力プログラム の出来上がりです baz.oはスタティックライブラリに いましたがプログラムにはロードされません リンカがスタティックライブラリから 選択的にロードする方法のため ロードされなかったのです これは自明ではありませんが スタティックライブラリの重要な点です これで スタティックリンクとライブラリの 基本が理解できたと思います 次に ld64として知られる Appleスタティックリンカに関する 最近の改善点 について説明します ご要望の多かった ld64の最適化に 今年も時間を費やしました そして今年のリンカは... 多くのプロジェクトで 2倍の速さを実現します どうして こんなことができたのか? 開発マシンのコアをより有効に 活用できるようになりました 複数のコアを使い リンカ作業を 並行して行える箇所が 多数見つかりました 入力から出力ファイルへの コンテンツのコピー LINKEDITの各部分の 並列ビルド UUID計算とコードサインハッシュ を並列で行うよう 変更すること などが含まれます 次に いくつかのアルゴリズム の改良を行いました C++のstring_viewオブジェクトで 各シンボルの文字列スライスを 表現するように変更すると exports-trie builderが 非常にうまく機能 することがわかりました また バイナリのUUIDを 計算する際に ハードウェア アクセラレーションを使う 最新の暗号ライブラリで その他のアルゴリズムも 改善しました
リンカの性能向上に 取り組む中で 一部Appでリンク時間に影響を与える 設定上の問題に気づきました 次に リンク時間を改善するため プロジェクトで何ができるかお話します 5つの話題を取り上げます スタティックライブラリ を使用すべきかどうか リンク時間に大きな影響を与える よく知られていない3つの選択肢 最後に知られていないスタティックリンクの 動作について説明します 最初は スタティックライブラリに ビルドするソースファイルを アクティブに 作業している場合 ビルド時間の遅れを 導入しているということです ファイルが コンパイルされた後 スタティックライブラリ全体を 目次を含めて 再ビルドしなければ ならないからです これでは 余計な I/Oが増えるだけです スタティックライブラリは 安定したコードに最も適しています つまり 積極的に変更されない コードなのです ビルド時間を短縮するために アクティブな開発中のコードを スタティックライブラリからの 移動を検討する必要があります アーカイブからの 選択的読み込みを紹介しましたね しかし その欠点はリンカの 速度が遅くなることです これは ビルドの 再現性を高め 伝統的なスタティックライブラリの セマンティクスに従うために スタティックライブラリを固定された 直列順序で処理する必要があるためです ld64の並列化の利点のいくつかは スタティックライブラリで 使えないということです しかし この歴史的動作が本当に 必要でない場合は リンカオプションを使用して ビルドを高速化できます そのリンカオプションは 「all load」と呼ばれています 全スタティックライブラリから.oファイルを ブラインドで読み込むよう指示します この機能は Appがすべての スタティックライブラリから コンテンツの大部分を選択的に 読み込むような場合に便利です all_loadを使用すると リンカはすべてのスタティックライブラリと その内容を並行して 解析することができます しかしみなさんのAppが 同じシンボルを実装した 複数のスタティック ライブラリを持っていて どの実装を使うかをスタティック ライブラリのコマンドラインの順序に 依存させるような 巧妙なトリックをするなら このオプションは みなさん向けではありません なぜなら リンカはすべての 実装を読み込むので 通常のスタティックリンクモード で見つかったシンボルの セマンティクスが 得られるとは限らないからです all_loadのもう一つの欠点は 「使われていない」コードが追加されるため プログラムが大きくなる 可能性があることです それを補うため リンカオプションの -dead_stripを使えます こレはリンカが到達不可能な コードとデータを削除します デッドストリップアルゴリズム は高速で 通常 出力ファイルのサイズを小さくして 元を取ることができます しかし もし-all_load と -dead_strip の使用に興味があるなら オプションがある場合と ない場合でリンカの時間を計り 特定のケースに勝てるかを 確認すべきです 次のリンカオプションは -no_exported_symbolsです ここで少し背景を説明します リンカが生成する LINKEDITセグメントの1つに エクスポートされるシンボル名 アドレス フラグを符号化した プレフィックスツリーである exports trieがあります すべてのdylibはエクスポートされた シンボルを持つ必要がありますが メインAppのバイナリは通常 エクスポートされたシンボルを必要としません つまり 通常は何もメイン実行ファイル にあるシンボルを調べないのです その場合 Appのターゲットに -no_exported_symbolsを使うと LINKEDIT でのトライデータ構造 の作成をスキップでき リンク時間が改善されます しかし Appがメイン実行ファイルに リンクするプラグインをロードする場合 またはAppでxctestをホスト環境として 使い xctestバンドルを実行する場合 Appはそのすべての エクスポートを持つ必要があり その構成では-no_exported_symbols を使えないことを 意味します 出力のトライが大きい場合にのみ それを抑制するのは理にかなっています ここで紹介するdyld_info コマンドを実行すると エクスポートされたシンボルの 数を数えることができます ある大規模Appでは 約100万個の シンボルがエクスポートされました リンカはそのシンボル数分の エクスポートトライを構築するのに 2〜3秒かかりました そこで -no_exported_symbolsを 追加することで そのAppのリンク時間を 2~3秒短縮することが できました dyld_infoツールについては 後半で詳しく説明します 次のオプションは -no_deduplicateです 数年前 私たちはリンカに 新しいパスを追加し 同じ命令で異なる名前を持つ 関数をマージするようにしました C++のテンプレート拡張で たくさん手に入ることがわかりました しかしこれは 高価なアルゴリズムです リンカは重複を探すため すべての関数の命令を再帰的に ハッシュ化する 必要があります そのため リンカはweak-def シンボルしか見ないように アルゴリズムを 限定しています C++コンパイラが インライン化 されていないテンプレート拡張のために 出力するものです さて de-dupはサイズの 最適化であり Debugビルドは高速ビルドが 目的で サイズには関係ありません そのため Xcodeのデフォルトでは Debug構成のリンカに -no_deduplicateを渡すことで 重複排除の最適化を無効にしています また clang link line を -O0 で実行すると clang はリンカに no-dedup オプションを渡します 要約すると もしみなさんが C++を使い カスタムビルド つまりXcodeで非標準の 設定を使用しているか 他のビルドシステムを 使用しているなら リンク時間改善のためデバッグビルドに -no_deduplicateを追加させるべきです 先ほど説明したオプションは ldに対する実際のコマンドライン引数です Xcodeを使用する場合 プロダクトの ビルド設定を変更する必要があります ビルド設定の中にある 「Other Linker Flags」を探します
all_loadに 設定する内容です 「Dead Code Stripping」の オプションもここにあります そして-no_exported_symbols があります そして これが -no_deduplicateです
では スタティックライブラリの 使用時に経験する ある驚きについて 説明します 最初の驚きは Appがリンクしている スタティックライブラリにビルドするソースコードが 最終的なAppに 含まれていない場合です 例えば 何かの関数に 「使用属性」を追加したり Objective-Cの カテゴリがあるとか リンカは 選択的にロードするため スタティックライブラリの これらのオブジェクトファイルが リンク時に必要となる 何らかのシンボルを定義していなければ これらのオブジェクトファイルは リンカにロードされません もうひとつ興味深いのは スタティックライブラリ とデッドストリップの 相互作用です 通常 シンボルの 欠落や重複があると リンカは エラーになります しかし デッドストリップを 行うとリンカは mainから始まるすべてのコードと データの到達可能性パスを実行し もし欠落したシンボルが到達不可能な コードに由来することが判明すれば リンカは欠落シンボルエラー を抑止するのです 同様に スタティックライブラリ のシンボルが重複している場合 リンカは最初のものを選び エラーになりません スタティックライブラリの利用で 最後に驚くのは 1つのスタティックライブラリが複数の フレームワークに組み込まれている場合です それぞれのフレームワークは 単独で問題なく動作しますが ある時点で あるAppが両方の フレームワークを使用すると 複数の定義のためにランタイムに 奇妙な問題が発生します 最もよく目にするケースは 同じクラス名の複数の インスタンスに関するObjective-C のランタイムの警告です 全体として スタティックライブラリは強力ですが 落とし穴を避けるためには スタティックライブラリを理解する必要があります これでスタティックリンクは終了です さて 次は ダイナミックリンクについてです まずスタティックライブラリ によるスタティックリンクの原図を見てみましょう 時間の経過とともに ソースコードの数が増えていく中で どのようにスケールアップ していくかを考えてみましょう より多くの ライブラリが利用できるようになれば 最終的なプログラムの規模が 大きくなる可能性が あることは明らかです プログラムを構築するスタティックリンク時間も 経過とともに長くなっていくのです
これらのライブラリがどう 作られているのかを見てみましょう 切り替えをしたら どうでしょう? 「ar」を「ld」に変更し 出力ライブラリは実行可能な バイナリになりました これが90年代のダイナミック ライブラリの始まりです 略語として ダイナミックライブラリを 「dylibs」と呼びます 他のプラットフォームでは DSOまたはDLLと呼ばれます ではいったい何が 起こっているのでしょうか? それがスケーラビリティに どう役立っているのでしょうか?
重要なのはスタティックリンカ はダイナミックライブラリ とのリンクを異なる 方法で扱うことです リンカはライブラリから最終的な プログラムにコードをコピーするのではなく 一種の約束を 記録するだけです つまりダイナミックライブラリから 使用されるシンボル名と 実行時にそのライブラリの パスがどうなるかを記録します これはどのような 利点があるのでしょうか? つまり プログラムファイルのサイズは 自分でコントロールできます コードと 実行時に必要な ダイナミックライブラリのリストが 含まれているだけです プログラム中にライブラリコードの コピーを取得することはなくなりました プログラムのスタティックリンク時間 はコードのサイズに比例し リンクするdylibの数には 依存しなくなりました またVirtual Memoryシステムも 陽の目を浴びます 複数のプロセスで同じ ダイナミックライブラリが使用されている場合 仮想記憶システムはそのディライブを 使用するすべてのプロセスで そのディライブのために同じ RAMの物理ページを再使用します ダイナミックライブラリがどのように始まり どんな問題を解決するかを紹介しました しかしその「メリット」に対する 「コスト」はどうでしょうか まずダイナミックライブラリを 使用するメリットとして ビルド時間の 短縮が挙げられます しかしその代償として Appの起動が遅くなりました 起動が単に1つのプログラムファイルを 読み込むだけではなくなったからです これで すべてのdylibもロードされ 一緒に接続される必要があります つまり ビルド時から起動時までの リンクコストの 一部を先送り しただけなのです 第二にダイナミックライブラリベースの プログラムではダーティページが多くなります スタティックライブラリの場合リンカ はすべてのスタティックライブラリの 全グローバルをメイン実行ファイル内の 同じDATAページに配置します しかしdylibsでは 各ライブラリに DATAページが用意されています 最後に ダイナミックリンクのもう一つのコストは 新しいものを導入する必要があることです ダイナミックリンカです! ビルド時に実行ファイルに記録された 約束事を覚えていますか? あとはライブラリを読み込むという 約束を実行時に果たすものが必要です そのための 動的リンカであるdyldです ではダイナミックリンクが実行時に どう機能するか掘り下げてみましょう 実行バイナリは 通常少なくとも TEXT DATA LINKEDITの各セグメントに 分割されます セグメントは常にOSの ページサイズの倍数です 各セグメントには異なる パーミッションが設定されます 例えば TEXTセグメントには 「execute」権限があります CPUはページ上のバイトを マシンコードの命令として扱えます 実行時にdyldは 各セグメントに 対応したパーミッションで 実行ファイルをメモリに mmap()する必要があります セグメントはページサイズで ページアラインされているため 仮想メモリシステムにとっては プログラムやdylibファイルをVMレンジの バッキングストアとして 設定するだけでよく 簡単なことです つまり これらのページで 何らかのメモリアクセスが発生し ページフォルトが発生 VMシステムがファイルの 適切なサブレンジを 読み込んで必要なRAMページを その内容で埋めるまで RAMには 何もロードされません しかし ただマッピングするだけでは 十分ではありません 何らかの方法で プログラムを dylibに「配線」する必要があります そのため私たちは「fix ups」 という概念を設けています
この図では プログラムが使用する dylibの部分を指す ポインタが設定されて いるのがわかります フィックスアップとは何か 掘り下げて考えてみましょう mach-oファイルを 紹介します TEXTは不変のものです 事実 コードサイニングに基づいた システムでなければなりません では malloc()を呼び出す関数 があった場合はどうでしょうか どうしてそんなことが できるのでしょう? プログラムのビルド時に_mallocの 相対アドレスが分かりません スタティックリンカは mallocがdylibにあることを見抜き 呼び出し先を 変換してしまったのです 呼び出し先は リンカが同じ TEXTセグメントで合成した スタブへの 呼び出しとなるため ビルド時に 相対アドレスがわかり BL命令を正しく 形成することができます どのように役立つかというと スタブがDATAからポインタをロードし その場所に ジャンプします 実行時にTEXTを変更する 必要がなくなり DATAだけがdyldで 変更されるようになりました dyldを理解する秘訣は dyldが行うすべての修正が dyldがDATAにポインタを セットしているだけなことです
dyldが行うフィックスアップについて もう少し掘り下げてみましょう LINKEDITのどこかに dyldがどんな フィックスアップをドライブするか に必要な情報があります フィックスアップには 2種類あります 1つ目は リベースと呼ばれるもので ディライブやAppが自分自身の 中を指すポインタを持つ場合です 現在はASLRという セキュリティ機能があり dyldはランダムなアドレスで dylibをロードします その内部ポインタは ビルド時に 設定するだけではダメだという事です 代わりに dyldは起動時にポインタを 調整するか「リベース」する必要があります ディスク上でこれらのポインタは dylibがアドレスゼロで ロードされた場合の ターゲットアドレスを含みます LINKEDITが記録する必要があるのは 各リベース先の場所だけです Dyld はリベースの各位置に dylib の実際のロードアドレスを 追加するだけで それらを正しく 修正することができます
2つ目のフィックスアップの 種類はバインドです バインドは シンボリックな参照です つまり そのターゲットは 記号名で 数値ではありません 例えば 関数 「malloc」 へのポインタです 文字列「_malloc」は実際には LINKEDIT に格納されており dyld はその文字列を使って libSystem.dylib の exportトリエでmallocの実際の アドレスを探します そして dyldはその値をバインドで 指定された場所に保存します 今年私たちは フィックスアップの 新しいエンコード方法として 「chained fixups」 を発表しました
第一のメリットは LINKEDITを小さくできることです LINKEDITは 全フィックスアップ箇所 を保存するのではなく 各DATAページ最初のフィックスアップ箇所と インポートしたシンボルのリストだけを 保存する新フォーマットなので より小さくなっています そして残りの情報は 最終的にフィックスアップが設定される 場所にあるDATAセグメント 自体にエンコードされます この新形式は修理箇所が 「連鎖」していることから chained fixupsと 名付けられました LINKEDITには 最初の修正箇所が書かれているだけで DATAの64ビットポインタ位置には 次の修正箇所への オフセットが含まれている ビットがあります フィックスアップがバインドか リベースかを示すビットも入っています バインドであれば 残りのビットは シンボルのインデックスとなります リベースであれば 残りのビットは 画像内のターゲットの オフセットとなります 最後に 連鎖したフィックスアップのランタイム サポートはiOS13.4以降に存在しています デプロイメント対象が iOS 13.4 以降であれば 今日からこの新しいフォーマットを 使用することができます また 連鎖したフィックスアップの フォーマットは 今年発表するOSの 新機能を可能にします しかしそれを理解するには dyldの仕組みを話す必要があります
Dyldはメインの実行ファイル (みなさんのApp)から始まります そのmach-oを解析して 依存する dylibs つまり どの約束されたダイナミックライブラリが 必要かを見つけます それらのディライブを見つけ mmap()します それぞれについて そのmach-o構造を再帰的に解析し 必要に応じて追加の dylibを読み込みます すべてがロードされると dyldは必要なすべての バインドシンボルを探し出し フィックスアップを行う際に それらのアドレスを使用します 最後に すべてのフィックスアップ が終わると dyldはイニシャライザを ボトムアップで実行します 5年前 私たちは新しい dyld技術を発表しました 上の緑で示した手順は Appを 起動する度に同じなことに気づきました そのため プログラムと dylibsを変更しない限り 緑で示したステップは すべて初回起動時にキャッシュされ 次回以降の起動時に 再利用することが可能でした 今年は dyldのさらなる 性能向上を発表しています dyldの新機能である 「ページインリンク」を発表します 起動時にdyld がすべてのdylib に 修正プログラムを適用する代わりに カーネルはページイン時に遅延し DATAページに 修正プログラムを適用できるようになりました mmap()された領域のあるページで あるアドレスが最初に使われると カーネルがそのページを読むきっかけ になるというのは従来通りです しかし現在では それがDATAページであれば カーネルはそのページが必要とする 修正も適用するようになっています 10年以上前からOSのdylibをdyldの 共有キャッシュでページインリンクするという 特殊なケースを 採用しています 今年はそれを一般化し 誰でも利用可能にしました これにより ダーティメモリの削減と 起動時間の短縮を実現しました DATA_CONSTページは クリーンであるため TEXTページと同様に 退避 再作成が可能で メモリの圧迫を 軽減することができます このページイン連携機能は 今後リリースされるiOS macOS watchOSに 搭載される予定です しかしページインリンクは 連鎖した フィックスアップバイナリにのみ機能します これは 連鎖した フィックスアップでは フィックスアップ情報の ほとんどがディスク上の DATAセグメントでエンコードされるため ページイン時にカーネルが 利用できるようになるためです 注意点として dyldは起動時のみ この機構を使用することです それ以降にdlopen()されたdylibは ページインリンクを取得しません この場合 dyldは従来の方法をとり dlopenの呼び出し中に 修正を適用します それを踏まえてdyldの ワークフロー図に戻りましょう 5年前からdyldは初回起動時に その作業をキャッシュし 以降の起動時に 再利用することで上記のステップを 緑に最適化しています 現在dyld は「apply fixup」ステップを 実際にfixupsを行わず カーネルに 遅延的に行わせることで 修正物を適用するステップを 最適化することができます dyldの新機能を ご覧いただいたところで ダイナミックリンクのベストプラクティス について説明します ダイナミックリンクのパフォーマンスを 向上させるためにできることは? 先ほど示したように dyldはすでにダイナミックリンクの ほとんどのステップを 高速化しています コントロールできるひとつは ディライブの数です dylibが多ければ多いほど dyldはそれらを ロードするのに多くの仕事をします 逆に言えば dylibの数が少ないほど dyldが行うべき作業も少なくなります 次に見るのは スタティックイニシャライザで これは常に実行されるコードで プリメインのことです 例えば スタティックイニシャライザで I/Oやネットワーキングを行わないことです 数ミリ秒以上 かかるようなことは 決してイニシャライザで 行うべきではありません ご存知のように 世界はより複雑化しており ユーザはより多くの 機能を求めています なのでその機能をすべて ライブラリで 管理するのは理にかなっています 目標はダイナミックライブラリとスタティックライブラリの 間のスイートスポットを見つけることです スタティックライブラリが多すぎると ビルドとデバッグの 反復サイクルが遅くなってしまいます 一方 ダイナミック ライブラリが多すぎると 起動時間が遅くなり お客様に気づかれてしまいます しかし今年は ld64を高速化し スイートスポットが 変わったかもしれません より多くの スタティックライブラリを使用したり より多くのソースファイルを 直接Appで使用したりしても 同じ時間でビルドできます 最後に インストールされている ベースがうまくいっている場合 新しいデプロイメント ターゲットにアップデートすると ツールで連鎖的な修正プログラム を生成できるため バイナリが小さくなり 起動時間が改善されます 最後に皆さんに 知っておいていただきたいのは リンクプロセスの内側を 覗くための2つの新しいツールです 最初のツールは dyld_usageです dyldが何をしているのか その痕跡を得るために使えます このツールはmacOS にしかありませんが シミュレータで起動したAppや Mac Catalyst用にビルドされたAppの場合は このツールを使ってトレース することが可能です 以下は macOS上のTextEditに 対して実行した例です
上の数行でわかる通り 起動には全体で 15msでしたが ページインリンクのおかげで フィックスアップには 1msしかかかりませんでした 現在 時間の大半はスタティックイニシャライザ に費やされています
次のツールはdyld_infoです ディスクと現在の dyldキャッシュの両方にある バイナリを検査するために 使用することができます このツールには選択肢が多くありますが 出力とフィックスアップの 表示方法を紹介します -fixupオプションは dyldが 処理する 全fixupの場所と ターゲットを表示します ファイルが旧式のフィックスアップでも 新しい連鎖式フィックスアップでも 出力は同じです -exportsオプションを指定すると dylibに含まれる出力されたシンボルと 各シンボルのdylibの開始点からの オフセットが表示されます この場合 dyldキャッシュ にあるdylibである Foundation.framework の情報が表示されます ディスク上に ファイルはありませんが dyld_infoツールはdyldと同コードを使うため ファイルを見つけることができます
スタティックライブラリとダイナミックライブラリの 歴史とトレードオフを理解した上で 自分のAppが 何を行っているかを見直し スイートスポットを 見つけたかどうかを 判断する必要があります 次に 大規模なApp を使用していて ビルドのリンクに 時間がかかっている場合は 新しい高速リンカを搭載した Xcode 14を試してみてください それでもスタティックリンクを もっと高速化したい場合は 私が詳しく説明した 3つのリンカオプションを調べ みなさんのビルドで意味を成すかどうかを確認し リンク時間を改善してください 最後に Appや組み込まれた構成を iOS 13.4 以降でビルドして 連鎖的な修正を 可能にすることもできます そして iOS 16でAppが小さくなり 起動が速くなったかを確認します ご視聴ありがとうございました 素敵なWWDCをお過ごしください
-