-
MLX:Appleシリコンでの大規模言語モデルの実行
MLX LMは、Appleシリコン上での大規模言語モデルによる処理を簡単かつ効率的に行えるように設計されています。Mac上で最先端の大規模言語モデルのファインチューニングと推論を実行する方法、およびSwiftで開発したアプリやプロジェクトにそれらモデルをシームレスに統合する方法について説明します。
関連する章
- 0:00 - イントロダクション
- 3:07 - MLX LMの概要
- 3:51 - テキストの生成
- 8:42 - 量子化
- 11:39 - ファインチューニング
- 17:02 - MLXSwiftでのLLM
リソース
- MLX Swift Examples
- MLX Examples
- MLX Swift
- MLX LM - Python API
- MLX Explore - Python API
- MLX Framework
- MLX Llama Inference
- MLX
関連ビデオ
WWDC25
-
このビデオを検索
こんにちは MLXチームのエンジニア Angelosです ここでは Appleシリコンでの 大規模言語モデルの 実行に適したMLXについて説明します MLXでは 推論や大規模モデルの ファインチューニングを Macから直接実行できます いずれもCLIアプリを使うか PythonまたはSwiftから実行できます MLXについて簡単に説明すると Apple シリコンで 機械学習を実行するための専用の オープンソースライブラリです Metalを利用してGPUを高速化し さらにユニファイドメモリを活用して CPUとGPUの処理で同じデータを 同時に利用できるようにします MLXはどの言語でも使用できます Python、Swift、C++、Cの APIが用意されています 詳しくは「Get Started with MLX for Apple Silicon」セッションをご覧ください Appleシリコンで大規模言語モデルを 実行する場合 MLXのパワフルな新機能により Macで1行のコマンドを入力するだけで 最先端の最新モデルを実行できます DeepSeek AIの最新モデルを 読み込んでみましょう 6,770億ものパラメータを持つモデルです
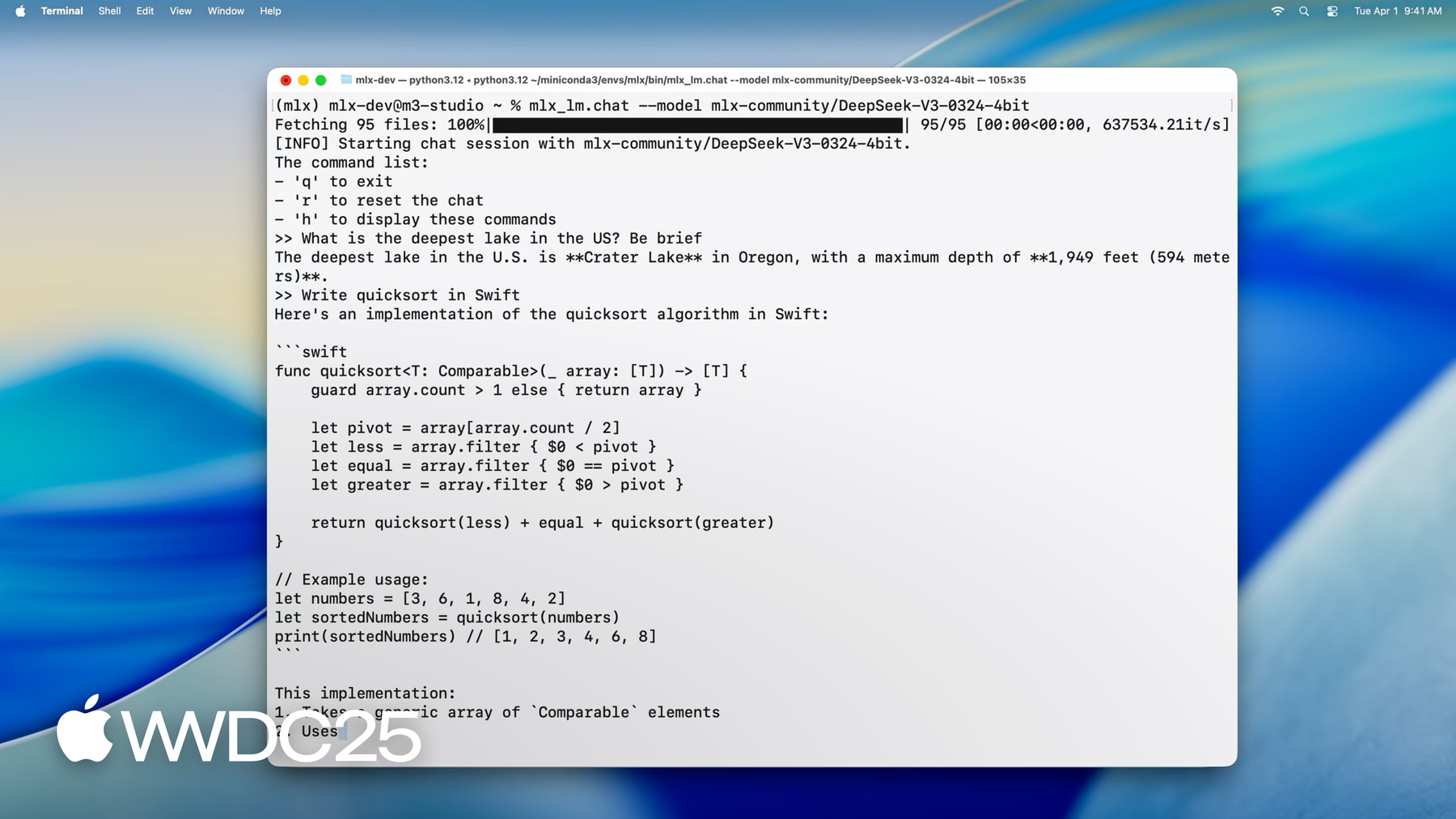
4.5bpwに量子化した場合でも モデルの重みだけで 約380GBのメモリが必要になります これに対応するため ここでは512GBもの ユニファイドメモリを搭載した M3 Ultraを使用します 一般向けでは類を見ない容量です モデルが読み込まれました 操作を開始できます 例えば このように質問できます 「アメリカで一番深い湖はどこですか」
コードを記述させることもできます
ご覧のように MLXならリアルタイムで スムーズにやり取りができ 読むより速い速度でコードが生成されます 膨大な数のパラメータを含むモデルでも Macのデスクトップ上で ローカルに実行できます 何ができるかわかったところで 次はMLXを使って このパワフルなモデルを Mac上で実行する方法を説明します まず MLX LMについて説明します Pythonライブラリと 一連のコマンドラインアプリがあり 大規模言語モデルの要件をすべて満たし 幅広い用途に対応した 堅牢性と汎用性に 優れたソリューションです
次に MLX LMを使用した テキスト生成について説明します Pythonまたはターミナルから テキストを簡単に生成する方法を ご紹介します 次に Hugging Faceから モデルをダウンロードして 量子化し デバイスでの推論を 高速化する方法をお見せします
MLXでできることは 推論だけではありません そこで次に MLX LMを使い 言語モデルを独自データで ファインチューニングします 具体的には 低ランクアダプタの トレーニングを行います これをモデルに取り込むことで デプロイが容易になり 推論を高速化できます 最後に説明するのは SwiftからMLXを利用する方法です わずか数行のコードで 大規模言語モデルを Swiftアプリに組み込むことができます
MLXで言語モデルを使用する 最も簡単な方法は MLX LMを使うことです MLX LMはMLXをベースとした Pythonパッケージで 大規模言語モデルの 実行やテストを目的としています モデルのファインチューニングや テキスト生成用の コマンドラインツールが用意されており コードを記述する必要はありません 詳細な制御が必要な場合は Python APIを使用して 生成やトレーニングプロセスを 必要に応じてカスタマイズできます また Hugging Faceと緊密に統合されており 何千ものモデルをインターネットから 簡単にダウンロードしたり 独自のモデルをアップロードして 共有したりできます
始めるのは簡単です pip install mlx-lmを実行するだけです
では 言語モデルの最も一般的な ユースケースを見ていきましょう テキスト生成です
こちらは ターミナルから 言語モデルを使って テキストを生成するコマンドライン ツールで コードの記述は不要です Hugging Faceのモデルまたはローカルパスと テキストプロンプトを指定すれば あとは自動的に処理されます 必要に応じて モデルをダウンロードし プロンプトを実行して 生成された応答を出力します 説明だけでなく 実際にこのコマンドを 実行してみましょう
ほんの数秒で Swiftで クイックソートを実装できます
モデルの動作を調整するには フラグを追加して サンプリング温度、top-p、 最大トークン数などを指定します 標準的なテキスト生成の場合と同様です 使用できるオプションを確認するには いつでも mlx_lm.generate --help を実行できます アイデアのプロトタイピングやコードの生成 モデルでできることを確かめたい場合も ここから始めるのが最も簡単です mlx_lm.generatを使えば 簡単にコマンドラインから テキストを生成できることをお見せしました しかし MLX LMの本当の強みは ターミナルツールに限定されないところです また クリーンで柔軟なPython APIがあり 詳細な制御が必要な場合や 大規模なワークフローに 生成機能を組み込む 必要がある場合に適しています それでは同様のテキスト生成を Pythonのコードを数行記述して 実行してみましょう
まず loadとgenerateの2つの ユーティリティをインポートします loadは名前のとおり モデルの 読み込み関連の処理を行います ローカルディスクまたは Hugging Faceから直接 指定されたモデルを取得し modelオブジェクトと tokenizerを設定します 次に generateを呼び出します この関数は トークン生成ループを実行し テキスト出力を返します この出力をPythonで処理したり ログに記録したり 別のシステムに入力したりできます
このloadとgenerateの 2つのステップだけで CLIと同じ機能を実現できます しかも Pythonなら柔軟性があり 細かな制御ができます MLX LMのPython APIの 強力な長所をもう1つ紹介します loadで取得したモデルは 固定のインターフェイスでのみ やり取りできる不透明な オブジェクトではありません 完全に構造化されたMLXニューラル ネットワークなので 内容を調べたり アーキテクチャを確認したり 変更したりできます 簡単なデモをお見せしましょう
まずprintで モデルを構成する レイヤーの一覧を出力します
transformerスタックの内訳が レイヤーごとに表示されます モデルのパラメータも確認できます このモデルが学習した重みやバイアスです
ネットワークの特定の部分 例えば最初のレイヤーの self-attentionモジュールを 調べたい場合は それも可能です
このような透明性の高さは デバッグや学習に加え レイヤーの入れ替え、カスタムの ファインチューニングルーチン、 低レベルモデルの手術などを テストする場合にも役立ちます
1つプロンプトでテキストを 生成する方法を見てきました では 会話を続けたい場合はどうでしょうか つまり 前のプロンプトに基づいて 新しいプロンプトを生成し 複数回にわたって応答を生成する場合です ここでキーバリューキャッシュ (KVキャッシュ)が出てきます 言語モデルでは アテンションメカニズムを使って 入力トークンを処理し 生成では それまでに生成された すべてのトークンに対する アテンションを繰り返し計算します 長いプロンプトやマルチターンの場合 負荷が高くなる可能性があります KVキャッシュはこれを解決するため キーと値の形で 前段階の中間結果を保存します
すべてをゼロから計算し直すのではなく このキャッシュを再利用することで 時間と計算処理を節約します MLX LMでは KVキャッシュを簡単に使用できます
先ほどのPythonの例で続けましょう KVキャッシュを明示的に作成し 複数回の生成に再利用できるようにします
まず make_prompt_cache関数で cacheオブジェクトを作成します これは 履歴を編集したり 後で使うために保存したり 会話間でシームレスに 置き換えたりする場合に利用できます
これをgenerate関数に渡します 新しいトークンが生成されると キャッシュが更新されます 各呼び出しは前回終了時点から続行され コンテキストが維持されます これは チャットボットや バーチャルアシスタントなど 履歴の追跡管理が必要な インタラクティブな アプリの構築に役立ちます
ではここで モデルの量子化の話をしましょう テキストを生成し モデルをインタラクティブに操作する方法を 見てきました しかし実際には 機能だけでなく 効率性も重要になります モデルは通常 float32やfloat16など トレーニングされた場合と 同じ精度でリリースされます 精度は確保されますが 大規模で低速のため 小型デバイスでは問題が生じます そこで量子化の出番です
量子化により Int8や4ビットまで モデルの精度を落とすと メモリの使用量を減らして 推論を高速化でき 多くの場合 品質にはほとんど影響しません しかし通常は 量子化には別のツールや 変換用スクリプトが必要で 互換性の問題が伴います 量子化が組み込まれているMLXなら はるかに簡単です 様々なレベルにモデルを圧縮して すぐに推論やトレーニングに使用でき 特別な設定は必要ありません 実際に見てみましょう
MLXで量子化する またはモデルを変換するには mlx_lm.convertコマンドを使用します このコマンドにより Hugging Faceからモデルをダウンロードし 別の精度に変換して ローカルに保存する 処理が1ステップで実行されます この例では オリジナルの 16ビットのMistralモデルを取得し 4bpwに量子化します
その結果 モデルのサイズが 大幅に小さくなり 実行速度が速く メモリ使用量が少なくなります 変換されたモデルは 指定したフォルダに保存され 同じMLX LMツール使って すぐに推論やトレーニングを実行できます
量子化したモデルを他の人と共有するには リポジトリ名を指定すれば 簡単にHugging Faceにアップロードできます 速度の最適化や容量の節約 コミュニティへの貢献のすべてを このコマンド1つで実行できます
テキストの生成と同様 Python APIを使用することで モデルの変換や量子化を 柔軟に行うことができます 複雑なことはありません 実際に MLX LMでは Pythonから モデルの様々な部分に 様々な量子化の設定を簡単に適用できます
例えば 最後の埋め込み投射層については 量子化の影響を受けやすい傾向があるため 高精度を維持するのが一般的です この例では それらのレイヤーは 6ビットに量子化し 他のレイヤーでは4ビットを使用することで 品質と効率性を両立させています それにはquant_predicate関数を指定します これは小さな関数で 各レイヤーを受け取って そこに 使用する量子化パラメータを返します それ以外はまったく同じです convertを呼び出して Hugging Faceのパスと 出力先のローカルディレクトリを指定すると モデルのダウンロードや 量子化した結果の保存など 残りの処理はMLXで実行されます このようなきめ細かい制御は モデルの圧縮を試す場合や パフォーマンスと精度の妥協点を 見極める際に非常に役立ちます
ここまでは 大規模言語モデルを使って テキストを生成する方法、 それらを量子化して推論の高速化と モデルの軽量化を 実現する方法を説明しました しかし MLXはこれだけでなく トレーニングなどにも役立ちます MLX LMにより 独自データを使って 大規模言語モデルを Mac上でファインチューニングできます データをデバイスの外部に持ち出す 必要がない点が重要です 何より 1行もコードを記述する 必要がありません では ファインチューニングを 見てみましょう
大規模言語モデルは通常 インターネット上にある 大量の汎用的なデータセットで トレーニングされます 幅広い知識が得られますが 特定分野の専門性に欠けたり 特定のタスクに必要な用語や表現が 不足したりする可能性があります そのようなモデルを 新しいコンテキストに適応させるのが ファインチューニングです 特定分野の小規模なデータセットでさらに トレーニングして新しい機能を加えたり 特定のニーズに合わせて 応答をカスタマイズしたりできます 従来 このプロセスはクラウドで 行われていましたが コストが増える上 プライバシーや 機微性の観点で 理想的ではない場合も多くありました MLXなら 大規模言語モデルの ファインチューニングを Macでローカルに実行できます クラウドは 不要で データは外部に送信されません 効率的かつセキュアで MLXのワークフローに シームレスに組み込めます
MLX LMは2種類のファインチューニングに 対応します モデル全体の ファインチューニングと 低ランクアダプタのトレーニングです フルファインチューニングでは 事前 トレーニング済みモデルの全パラメータが 更新され 最大限の柔軟性が得られますが リソースの消費量も増えます これに対して 低ランクアダプタの トレーニングでは 少数の新しいパラメータをモデルに追加して それだけのトレーニングを行い 元のネットワークはそのまま維持します そのため トレーニングは高速軽量になり メモリ効率も向上する場合が多く ローカルハードウェアに適します 実際にやってみましょう カスタムデータセットで Mistralモデルのファイン チューニングを行います MLX LMでファインチューニングを 実行するのが 簡単なことをお見せします 必要なのは1つのコマンドと いくつかの引数だけです ファインチューニングするモデル、 データセットへのパス、 トレーニング期間を指定します 量子化はMLXに深く組み込まれているため mlx_lm.loraコマンドでは 量子化されたモデルのアダプタも トレーニングできます これにより ファインチューニングの効果を 損なうことなく メモリ使用量が劇的に減少します
この例では Mistralの4ビット量子化 バージョンにトレーニングを行います 完全精度バージョンと比較して モデルの重みに対するメモリ使用量が 約3.5倍削減されます そのため大規模モデルでも ファインチューニングが可能で Mac上で効率的に行えます この1行のコマンドですぐに トレーニングを実行できます 初心者の方でも簡単です ただし パフォーマンスの微調整が必要な場合は トレーニングプロセスをより詳細に 制御できる必要があります その場合にトレーニング 設定ファイルを使用します MLX LMは設定ファイルに対応しており トレーニングを様々な観点から きめ細かく制御できます 例えば パスサイズ、 学習率スケジュール、 最適化の設定、評価間隔などがあります 特定のデータセットやハードウェア 最適化の目標に応じて トレーニングの設定をカスタマイズでき アダプタの効果を最大限に高められます 実際のファインチューニングと モデルの知識の更新について確認しましょう まず Mistral 7Bに直近の スーパーボウルの勝者を尋ねます
予想通り 正しい回答ですが 古い情報です モデルのナレッジカットオフにより 最近のイベントは把握していません ファインチューニングを行えば わずか数分でこの問題に対処できます 最新のスーパーボウルに関する 質問と回答を含む 小規模なデータセットでトレーニングして モデルの知識を 更新すると 正しく答えられるようになります
モデルをわずか数分 ファインチューニングするだけで チームや選手、得点などに関する 最新の情報を回答できるようになります
アダプタをトレーニングしたので MLX LMを使って ベースモデルに取り込みます これにより デプロイや 共有がしやすくなります 自己完結型の1つのモデルになり 配布や使用が容易になるからです
取り込みのプロセスでは アダプタを元の重みと結合します その結果 アーキテクチャとパラメータ数は 事前トレーニング済みのバージョンと同じで 機能だけが更新されたモデルが得られます 外から見れば他のモデルと 同様の振る舞いで ファインチューニングされた知識が 組み込まれた状態です
アダプタをモデルに取り込むには mlx_lm.fuseコマンドを使用します 結合後の重みの計算と 指定されたパスへの結果の保存が すべて1つのステップで実行されます 量子化解除や再量子化を 手動で行う必要はありません MLXによって自動で処理され トレーニング中に使用したのと 同じ量子化が維持されます ファインチューニングした新しいモデルを 他の人と共有するのも簡単です Hugging Faceのリポジトリ名を 指定するだけで 結合後のモデルがアップロードされ 使用できるようになります Pythonを使ってテキストの生成と大規模言語 モデルのファインチューニングを行いました しかし MLXがひときわ優れているのは Swiftでもシンプルかつ柔軟に 同様のことが行える点です MLXにより Swiftで大規模言語モデルを いかに簡単に使用できるかをご覧ください
こちらは Swiftで 量子化した Mistralモデルを読み込み テキストを生成する場合の例です 全体でわずか28行のコードです 最初に MLXと言語モデルライブラリを インポートします 次に modelコンテナを作成します これはモデルとトークナイザーへの 同時アクセスを安全に管理するアクターです 次に 入力を準備します プロンプトをトークン化し モデルが理解できる数値形式に変換します 最後に 生成ループを実行し 結果を出力します 先ほどのPythonと同様です 同じワークフローで 同じ機能ですが 完全にSwiftネイティブのコードです 次に モデルで複数回のやり取りにわたる 会話の履歴を保持する方法を確認しましょう 先ほどPythonで行ったのと同じです Swiftではさらに数行の コードが必要になります 基本的な考え方は同じです キーバリューキャッシュを 明示的に作成して 複数の生成で再利用できるようにします これは1行追加するだけでできます 難しいことはありません やり取りをより正確に管理するため TokenIteratorも使用します これにより キーバリューキャッシュを直接設定し 生成をステップごとに制御できます この設定により 柔軟な対応が可能になり 複数ターンの会話や高度なプロンプトを すべてSwiftで処理できます このセッションでは コードまたは ターミナルコマンドを使用し MLXで 推論、トレーニング、量子化を 簡単に行えることを見てきました ここで使用したのは 上位の言語モデルAPIから 下層で下支えするMetalカーネルに至るまで すべてオープンソースです MLXには PythonおよびSwiftの 高レベルのAPIが用意され C、C++、 Python、Swiftで主要な処理を実行できます 柔軟性に優れ スタック全体を制御できます Apple製ハードウェアで言語モデルや 機械学習のワークフローを 実行するための強力な フレームワークとなっています この次のステップについてお話します ここでは MLX LMの主な機能を 紹介しましたが その他にも様々なことが可能です Appleのドキュメントでは 分散推論と分散トレーニング、 学習済み量子化、 カスタムトレーニングループなどの 高度な機能について説明しています MLXとMLX Swiftのサンプルリポジトリに 用意されているプロジェクトを使って 拡散モデルによる画像生成、音声認識、 言語モデル全体のトレーニングなどの タスクを試すことができます 独自のAIアプリを開発する場合でも 機能を確認したい場合でも 数回クリックするだけで 必要なものが見つかります MLXと大規模言語モデルの パワーを活かして Appleのハードウェア上で すばらしい体験を実現してください
-
-
1:12 - Running DeepSeek AI's model with MLX LM
mlx_lm.chat --model mlx-community/DeepSeek-V3-0324-4bit -
3:51 - Text generation with MLX LM
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" -
4:35 - Changing the model's behavior with flags
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" \ --top-p 0.5 \ --temp 0.2 \ --max-tokens 1024 -
4:48 - Getting help for MLX LM
mlx_lm.generate --help -
5:26 - MLX LM Python API
# Using MLX LM from Python from mlx_lm import load, generate # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) # Generate the text text = generate(model, tokenizer, prompt=prompt, verbose=True) -
6:24 - Inspecting model architecture
from mlx_lm import load, generate model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") print(model) print(model.parameters()) print(model.layers[0].self_attn) -
8:01 - Generation with KV cache
from mlx_lm import load, generate from mlx_lm.models.cache import make_prompt_cache # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) cache = make_prompt_cache(model) # Generate the text text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, verbose=True) -
9:37 - Quantization
mlx_lm.convert --hf-path "mistralai/Mistral-7B-Instruct-v0.3" \ --mlx-path "./mistral-7b-v0.3-4bit" \ --dtype float16 \ --quantize --q-bits 4 --q-group-size 64 -
10:33 - Model quantization with MLX LM in Python
from mlx_lm.convert import convert # We can choose a different quantization per layer def mixed_quantization(layer_path, layer, model_config): if "lm_head" in layer_path or "embed_tokens" in layer_path: return {"bits": 6, "group_size": 64} elif hasattr(layer, "to_quantized"): return {"bits": 4, "group_size": 64} else: return False # Convert can be used to change precision, quantize and upload models to HF convert( hf_path="mistralai/Mistral-7B-Instruct-v0.3", mlx_path="./mistral-7b-v0.3-mixed-4-6-bit", quantize=True, quant_predicate=mixed_quantization ) -
13:37 - Model fine-tuning
mlx_lm.lora --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --train --data /path/to/our/data/folder --iters 300 --batch-size 16 -
15:06 - Prompting before fine-tuning
mlx_lm.generate --model "./mistral-7b-v0.3-4bit" \ --prompt "Who won the latest super bowl?" -
15:34 - Fine-tuning to learn new knowledge
mlx_lm.lora --model "./mistral-7b-v0.3-4bit" --train --data ./data --iters 300 --batch-size 8 --mask-prompt --learning-rate 1e-5 -
15:48 - Prompting after fine-tuning
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Who won the latest super bowl?" \ --adapter "adapters" -
16:29 - Fusing models
mlx_lm.fuse --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --adapter-path "path/to/trained/adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" \ --upload-repo "my-name/fused-mistral-7b-v0.3-4bit" # Fusing our fine-tuned model adapters mlx_lm.fuse --model "./mistral-7b-v0.3-4bit" \ --adapter-path "adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" -
17:14 - LLMs in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Generate the text let params = GenerateParameters(temperature: 0.0) let tokenStream = try generate(input: input, parameters: params, context: context) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } } -
18:00 - Generation with KV cache in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Create the key-value cache let generateParameters = GenerateParameters() let cache = context.model.newCache(parameters: generateParameters) // Low level token iterator let tokenIter = try TokenIterator(input: input, model: context.model, cache: cache, parameters: generateParameters) let tokenStream = generate(input: input, context: context, iterator: tokenIter) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } }
-