-
Metalレイトレーシングのパフォーマンスを最大限に高める
レイトレーシングコードを簡素化し、Metal 3の機能を使用してパフォーマンスを向上させる方法を紹介します。さらに、レイトレーシングAppの調整に役立つGPUデバッグおよびプロファイリングツールについて解説します。また、加速構造のプリミティブごとのデータを使用して、インターセクションテストを高速化したり、シェーダーコードのメモリアクセスや間接参照を削減したりする方法についても解説します。加速構造のビルドや改修を高速化することで、ロード時間やフレームあたりのオーバーヘッドを削減することができるようになります。
リソース
関連ビデオ
Tech Talks
WWDC23
WWDC22
WWDC21
WWDC20
-
このビデオを検索
♪ ♪
こんにちは Yiです こんにちは Dominikです 私たちはGPU Softwareのエンジニアです 今日はMetalレイトレーシングAPIに 今年追加された レイトレーシングAppのパフォーマンスを最大化 のパフォーマンス拡張と 機能についてお話します レイトレーシングのはシーン上で跳ね返る 個々の光線をシミュレートします ゲームやオフライン レンダリングで写実的な反射 影 照度を表現するために使用されます そのためには多くの光線を シミュレートする必要があり このような用途では 高パフォーマンスが重要です 幸い Metalは全Apple製デバイスに最適化された レイトレーシングのサポートを内蔵しています レイトレーシングの仕組みを 簡単におさらいしましょう MetalのレイトレーシングAPIはcompute関数 などのシェーダー関数内から 利用することができます まずシーンに投射される 光線をいくつか生成します 次にインターセクタ-オブジェクトを作成し それを使って光線とシーンの ジオメトリの交差をチェック 後ほど今年追加された インターセクション検索を 高速化するための新機能を説明します この処理はアクセラ-レーション構造という 特殊なデータ構造に依存しており この構造もシーン内の ジオメトリを表現している また高速化構造に焦点を当てた いくつかの新機能と 性能向上についてお話します インターセクターは各光線が 当たったプリミティブを 記述した交差結果オブジェクトを返します 交差結果は出力画像に書込む 色の生成に使用される また再度プロセスを経た 追加レイの生産にも利用できる この作業を繰り返すことで 光の反射をシミュレートできます Metalのレイトレーシング API基本を学びたい方は 過去のWWDCセッションをご覧になってください WWDC20で初めてMetalの レイトレーシングAPIを紹介 昨年はモーションブラーへの 対応等新機能を紹介しました 今日は3つのことをお話しします まずAppでのレイトレーシングの性能を 向上させることができる 新機能についてお伝えします
次に加速度構造APIに追加した 改良と機能についてお話します
最後にDominikからレイトレーシングのための GPUツールの改良についてお伝えします 今年はレイトレーシングの性能向上と コードの簡素化を目的とした 3つの新機能が追加されました プリミティブデータ単位での取得 交差関数テーブルからのバッファの取得 間接コマンドバッファからの レイトレーシングのサポート
まずプリミティブ単位の データから見てみましょう Appは通常 シーンのプリミティブの関連データ 頂点カラー 法線 テクスチャ座標 などを持っています
今年は各プリミティブの少量のデータを 加速度構造体に直接保存する 機能を追加しました これより少ないメモリ間接参照と キャッシュミスで パフォーマンスを向上させることができます またプリミティブに関連する データを検索するために 複雑な補助データ構造を 保存する必要がなくなります
例を見ていきましょう
アルファテストは三角形の数を増やすことなく 透明なジオメトリに複雑さを 加えるための手法です 三角形にマッピングされた テクスチャのアルファ チャンネルを使用 レイが 三角形に当たるか否かを判断
三角形がレイに当たった時に カスタム交差関数を呼出す ようインターセクターを 設定する必要があります
目標は三角形に関する テクスチャからサンプリング アルファ値が通過するレイを 許容するかのテストです そのためにはテクスチャオブジェクトと UV座標という2つの情報が必要です アルファテストの実装ではこの情報を得るため メタルデバイスのメモリに ある多数の中間バッファに アクセスする必要があります
まずプリミティブに関連するテクスチャを ある種のマテリアル構造に 格納することになります
いくつかの素材が緩衝材に 詰め込まれることになる プリミティブ毎に材料構造を 保存するのは容量が多く プリミティブ数が増えるので 現実的ではありません 代わりに各プリミティブの 材料IDだけバッファに保存 それを使って素材を検索することになります 次にUVを計算するため各頂点のUVを 別のバッファからロードして 補間する必要があります 次にインスタンス化された ジオメトリを使うとします 各インスタンスに独自素材と UVマッピングを持たせる時 それをサポートするため インスタンスデータバッファに UVとMaterialIDバッファへのポインタを格納し 関数に別レベルの間接性を 追加することになります この方法は複雑なバッファ 設定を維持する必要があり データ到達まで何重もの インダイレクトが必要となる またキャッシュミスが発生し 性能に悪影響を与える可能性があります この図を実装するために 必要なコードを見ましょう プリミティブデータを使って 段階的に簡略化する方法を紹介します アルファテスト交差点機能の オリジナル実装です この関数は三角形にレイが当ると呼び出され メモリからインスタンス データ読込する事から始める インスタンスが使用するUV およびマテリアルバッファへ ポインタを格納するバッファです 次にUVバッファから UV座標をロードし補間する これもメモリの負荷です そして別のバッファから 素材インデックスをロード 最後にこの関数は素材をロードし 対応するテクスチャをサンプリングします この時点で関数は必要なアルファ値を手に入れ それを閾値と比較できるようになります ではコードを簡略化し プリミティブデータ単位で パフォーマンスを向上させる方法を紹介します 何層にもわたる複雑な バッファを使用する代わりに 交差関数が各プリミティブに対して 必要とするデータのみを 加速度構造体に直接格納すればよいのです この例では各プリミティブの テクスチャとUV座標を含む 構造体を作成することができます 加速度構造体を構築する時に このデータを提供し 交差関数はレイがプリミティブに当たった時 そのデータへのポインタを受け取るだけです プリミティブデータには何でも格納できますが サイズを小さくしておくと 最高性能を引き出せます まず交差点関数の入力から説明します すべてにアクセスできるようになると 実装の自由度が増しますが GPUのレジスタ使用量が増える可能性もあります プリミティブデータでは 全バッファにアクセスでなく プリミティブデータポインタ のみアクセスすればよい これはアクセラレーション構造に 直接保存するデータです この場合各プリミティブは 独自テクスチャオブジェクト とそのすべての頂点のUVを持つことになります 次に素材バッファとインスタンス データバッファからのロードです どちらも不要になります 代わりにプリミティブデータポインタから 1回だけロードを行えます 本機能で必要なデバイス メモリアクセスはこれのみ 次はUVです 取得したポインタを デリファレンスする代わりに プリミティブデータ構造毎の データにアクセスするのみ このコードの変更はささいなことですが 追加のメモリ負荷を防ぐには重要です 最後に素材特性です 必要なのはテクスチャの部分だけなので プリミティブのテクスチャを プリミティブ単位の データ構造に直接エンコード することができます つまり素材や素材インデックスバッファに アクセスする必要はもうないのです 追加のメモリ再参照のコストをかけずに 単純にテクスチャを 直接使用することができます このようにプリミティブ-データを使用すると 交点コードが非常にシンプルになります 高コストのメモリアクセスは プリミティブデータポインタ からの1回のロードに置き換えられます その上コードがよりシンプル になり従いやすくなりました 次に加速度構造体にプリミティブデータを 格納する方法を紹介します 交差点関数からアクセスする 前に行う必要があります アクセラレーション構造ジオメトリ ディスクリプタの いくつかのフィールドを 設定する必要があります まずデータが格納される メタルバッファを設定します 次にプリミティブに格納する データサイズを指定します データがバッファに密に格納されていない場合 またはバッファの先頭から 始まっていない場合は ストライドとオフセットを 指定することもできます それ以外 デフォルトの値は 0なので設定は不要です 交差点関数で主成分毎の データ使用方法については すでにご覧になったとおりです 単にポインタとして関数に渡されるだけです それだけでなくデータには どこからでもアクセス可能 中にはインターセクターが 返す最終的な交点結果も含む 交差クエリを使用する場合 プリミティブデータは 交点候補と交点コミット メントの両方が利用可能 つまり交点テストだけで なくシェーディングにも プリミティブ単位のデータを使用できるのです プリミティブデータはメモリアクセスや インダイレクトの数を 減らすことで交差点コードと シェーディングコードの両方 の性能を向上させられる 実際あるテストAppでは プリミティブ単位のデータを 使用することで10%から 16%の性能向上が見れました パフォーマンスやコード品質が どのように改善されるのか 早く試して頂きたいです 今年はMetalシェーディング 言語にレイトレーシングの カーネルを簡素化するため 別の機能も追加されました Appは交差関数とメインの レイトレーシングカーネルの 両方に同じバインディングの セットを渡すことがあります 例えばレイトレーシングのサンプルコードでは 球体をレンダリングするため 交差関数を使用しています この交差点関数は各球体に関する情報を含む リソースバッファにアクセスする このバッファを交差点関数に渡すために Appはバッファを交差点 関数テーブルにバインドする しかしレイトレーシング カーネルもリソースバッファ にアクセスするためAppは バッファをそこにもバインド 今年シェーディング言語Metal では交差関数テーブルに 束縛されたバッファにアクセスできます この新機能によりカーネル用 バッファをバインドする 手間を省き代わりに交差関数テーブルから 直接アクセスすることが できるようになりました これは交差関数表の get_bufferメソッドを呼出し そのポインタ型を指定することで可能です また表示テーブルをタイプ別 アクセスすることも可能です 間接コマンドバッファはGPU作業をGPU上で 独立エンコード GPU駆動 パイプライン基本要素を表す 間接コマンドバッファや GPU駆動のレンダリングについては WWDC2019「Metalによる最新のレンダリング」 をご覧いただくことをお勧めします レイトレーシングサポートを 有効にするのは簡単です ディスクリプタにsupportRayTracing フラグを設定するだけです 間接コマンドバッファは グラフィック関数 計算関数を ディスパッチ 関数から通常 通りレイトレーシングを利用 以上が今年追加された新機能 概要でお客様のAppで レイトレーシングの性能向上に役立つものです 次に加速度構造について説明します いくつかの性能改善を実施し 加速度構造の構築に 重点を置いた機能を追加しました どのような用途に使われるか おさらいしましょう アクセラレーション構造とは レイトレーシング処理を 高速化するためのデータ構造です これは再帰的に空間を 分割することでどの三角形が レイと交差する可能性が 高いか素早く見つけられます 複雑なシーンの構築をサポートするためMetalは プリミティブとインスタンスの2種類の アクセラレーション構造をサポートしています 個々のジオメトリはプリミティブな 加速度構造で表現される 平面や立方体等単純な物から 球体や三角形のメッシュの ような複雑なものまで さまざまなものがあります instance acceleration構造を用い 複雑なシーンを作成できます インスタンス加速度構造体は プリミティブ加速度構造体の コピーを作成します シーン内の各オブジェクトに 対し変換行列を定義します 次に変換行列の配列と プリミティブアクセラレーション構造を使って インスタンスアクセラレーション構造を 構築する これが加速度構造を用い 静的なシーンの構築方法です 次にゲームのような動的なAppでは 加速度構造体がどのように 使われるかを見てみましょう
まずゲームを初めて起動する時や 新しいレベルをロードするときには いくつかのタスクが必要です これはモデルやテクスチャの 読込み等通常作業も含みます レイトレーシングでは 使用する全モデルについて プリミティブな加速度構造を 構築する必要もあります main rendering loopの時間を 節約するためロード時に プリミティブアクセラレーション構造を 構築することをお勧めします インスタンスアクセラレーション構造を 使い必要に応じオブジェクトを シーンに追加したり削除できます Appの読込みが完了したら メインループに入ります フレーム毎 ラスタライズ レイトレーシング ポスト プロセッシングを組合わせ シーンをレンダリングします しかしゲームは非常に動的であるため おそらく加速度構造の一部を 更新する必要があります これは通常スキニングされた キャラクター等の変形モデル アニメーションモデルの 再フィッティングを含みます 既存の加速度センサーの構造を換装することは フルリビルドより速い事から こんなケースでお勧めです またインスタンスアクセラレーション構造の 完全な再構築を行う必要です 最終フレーム以降にオブジェクトが追加または 削除されたり移動している 可能性があるためです この場合加速度構造体は1つしかなく通常 せいぜい数千のオブジェクト しか含まれていないため 完全なリビルドを行うことは問題ないでしょう 今年はこれら全ケースで 性能向上が実現しました まずAppleSilicon上で アクセラレーション構造の ビルドが最大2.3倍高速化されました 2つ目はリフィッティングが 38%高速化されたことです
ロードタイム フレーム毎の オーバーヘッド両方で削減 しかしさらに良い点があります Appによっては何百 何千 という小さなプリミティブな 加速度構造を構築するものもあります 小さなビルドはGPUを満杯 にする個々の作業を行わず 結果としてGPU使用率が低い時間が長くなります そのためAppleSilicon上では 可能な限り自動的に 複数のビルドが並行して 行われるようになりました この結果並列に実行した場合最大で2.8倍の 高速ビルドが可能となります これによりロードタイムをより短縮できます またこれはビルドだけでなく コンパクト化や再フィット等 加速度構造のすべての操作に 適用されるためフレームごとの オーバーヘッドも削減されます この最適化の恩恵を確実に受けるためには いくつかのガイドラインを守る必要があります 以下は加速度構造の配列を構築する例です 並行してビルドするため多く のビルドで同じ加速度構造 コマンドエンコーダを使用する必要があります 同じバッファを使用する ビルドは並行実行できません したがい各ビルドで同じ スクラッチバッファではなく 小さなバッファのプールで ループ確認が必要です
以上が加速度構造を構築するために行った 性能向上の内容です また加速度構造をより簡単により効率的に 構築するための3つの新機能を追加しました
頂点フォーマットの追加 変換行列サポート ヒープから アクセラレーション構造体の 割り当てなどである
まず頂点フォーマットから説明しましょう 一般的な性能最適化は頂点データに量子化または 低精度なフォーマットを使用することで メモリ使用量を少なくすることです 今年はさまざまな頂点フォーマットから 加速度構造を構築することができます これは半精度浮動-小数点フォーマット 平面ジオメトリ用の2成分 頂点フォーマット 通常の 正規化された整数-フォーマットが含まれます これまでのアクセラレーション構造では 3要素の全精度浮動小数点数の 頂点データが必要でした この例ではAppは半精度頂点フォーマットの 頂点データを持っています このデータは加速度構造を 構築するためだけに解凍され 一時的なバッファにコピーされる必要があります 新しい頂点フォーマット-機能により アクセラレーション構造ビルドは サポートされる任意の フォーマットで頂点データを 消費できるようになり 一時的なコピーを作成する必要がなくなりました 頂点フォーマットの設定は これ以上ないほど簡単です ジオメトリディスクリプタに プロパティを設定するだけです 次に変換行列について説明します この機能は新しい頂点 フォーマットを補完するもので アクセラレーション構造を構築する前に 頂点データをあらかじめ 変換しておくことができます 例えば正規化されたフォーマットで保存された 複雑なメッシュを解凍する際などです このシーンでレッサーパンダを モデルに見てみましょう 圧縮されたフォーマットを 使用するためジオメトリを 正規化するにはメッシュを取得 その境界を計算し それらを0から1の範囲に スケーリングする必要があります 正規化後の整数頂点フォーマットを 使用しメッシュを保存することで ディスクやメモリにかかる容量を削減できます 実行時に各頂点の最終位置までのスケールと オフセットを行うマトリックスを提供します その行列を適用すると元の モデルを取り出すことができます では変換行列を渡す加速度構造を 設定する方法を説明します まずトランスフォーム-バッファを作成します 1つの方法はスケールと オフセットの変換行列を含む MTLPackedFloat4x3オブジェクトを 作成することです 次にマトリックス保持に十分な 大きさのメタルバッファを作成 そして最後にその行列を バッファにコピーします 次にアクセラレーション構造を設定します まず三角形のジオメトリディ スクリプターを作成します 次に変換用マトリックス-バッファを指定します そして最後にバッファオフセットです 以上で変換行列の設定は完了です これら行列は単純な アクセラレーション構造を組み合わせ レイトレーシング性能の向上に使用できます シーンの例を見てみましょう ここでは箱と球はすべて比較的単純なメッシュです これはこのグループの アクセラレーション構造を シーン前面に最適化する 機会を提供するものです インスタンスアクセラレーション 構造に注目すると 光線が当たるインスタンスごとに オーバーヘッドが発生します レイを変換しインスタンスからプリミティブ アクセラレーション構造への 切替えにコストがかかります これはインスタンスが 重なっている時に発生します インスタンス数を減らすため 箱と球の両方を含む単一の プリミティブアクセラレーション 構造を生成できます そのためにはオブジェクト毎に ジオメトリディスクリプタを 作成しそれぞれに変換行列を 持たせることができます その結果プリミティブ アクセラレーション構造は インスタンスアクセラレーション構造の インスタンスとなり箱と球を含む その結果アクセラレーション構造が より良いものになるはずです コードで設定する方法を見てみましょう
球の形状を定義する ディスクリプタから始めます 次にプリミティブアクセラレーション- 構造として 頂点バッファ インデックスバッファ その他の プロパティを通常通り設定します 違いは球体のコピーに使用する変換行列を含む 変換バッファも指定することです
ボックスの場合複数の ジオメトリディスクリプタが 頂点とインデックスバッファを共有しています コピー毎に異なる変換 バッファを指定するだけです 最後にプリミティブアクセラレーション 構造の記述子を作成する際 すべてのジオメトリ記述子を追加します この結果プリミティブ アクセラレーション構造が生成され IDトランスフォームを使用し シーンにインスタンス化できます プリミティブアクセラレーション-構造は別々の アクセラレーション構造より構築時間が 短く交差も速くなります
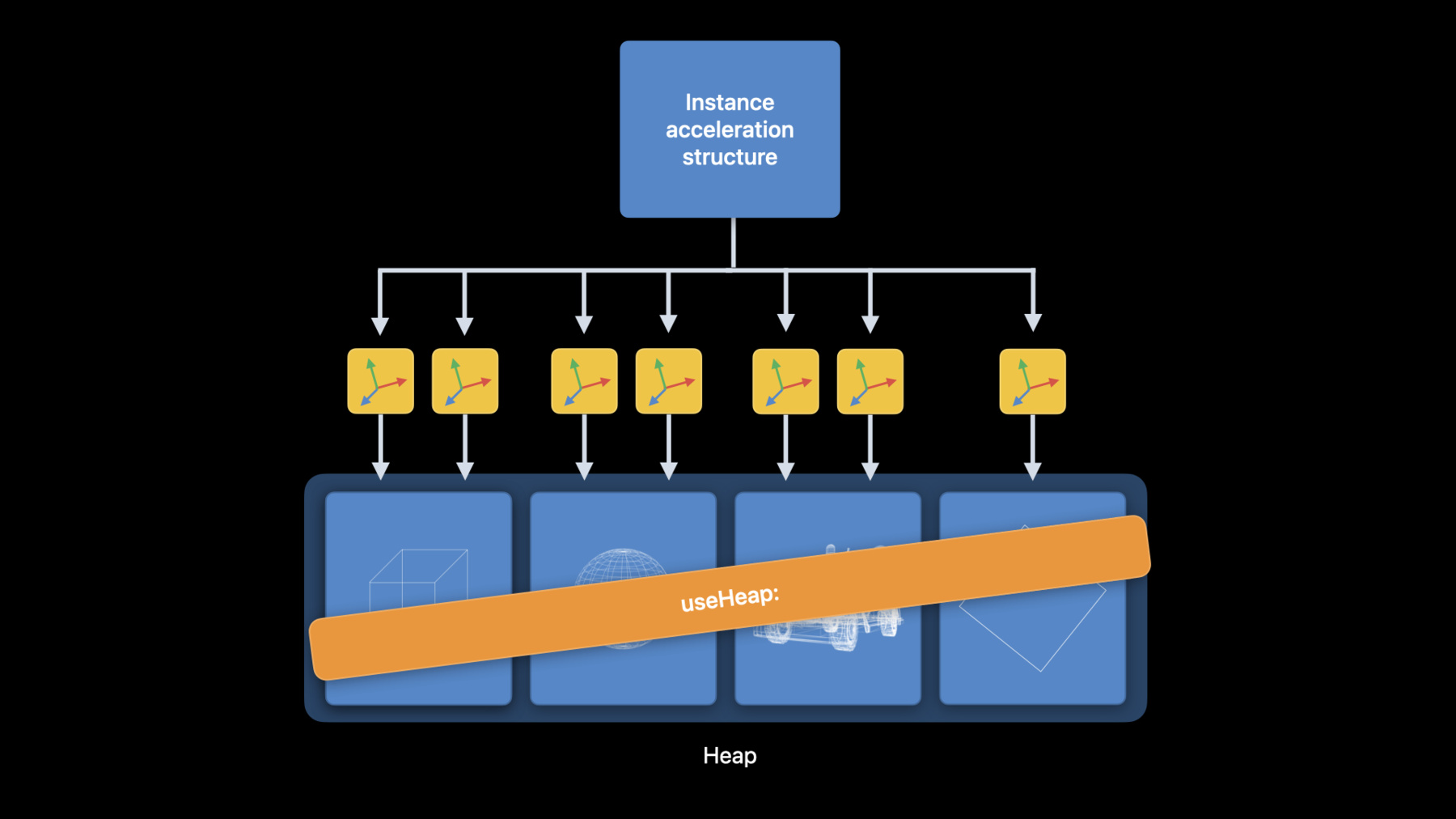
最後にアクセラレーション構造のヒープ確保は 最も要望の多かった機能の一つです この機能によりアクセラレーション 機構の割り当てを より自由にコントロール できるようになりました また割当て間でヒープ メモリを再利用できるため 高価なバッファの割当てを 回避することができます ヒープはインスタンスアクセラ レーション構造体を使用する際 useResource:メソッドの呼出しを 減らす事で性能向上も可能です 例のシーンに戻ると インスタンスアクセラレーション構造体は プリミティブアクセラレーション構造体を 間接的に参照している つまりコマンドエンコーダーで インスタンスアクセラレーション構造を 使用したい時はその都度 プリミティブアクセラレーション構造毎に useResource:メソッドを呼出す必要があります 大規模なシーンではインスタンス アクセラレーション構造を使用する度 useResource:を何千回も呼び出す 必要がある可能性があります 多くのuseResource:コールが ある事を把握していれば useResources:を呼んでAPIコールの 回数を減らせますが それでもアクセラレーション構造の 配列を維持する必要があり Metalは配列を介してループする必要があります その代わりこれらのプリミティブ アクセラレーション構造を すべて同じヒープから 割り当てることができます インスタンスアクセラレーション構造を 使用する場合 useHeap:メソッドを1回呼び出すだけで 全プリミティブアクセラレーション構造を 参照することができます useResource:の呼び出しを useHeap:の単一呼び出しに 置き換えるだけでAppで性能向上が見られました それではヒープからアクセラレーション構造を 割当てる方法について見てみましょう ディスクリプタを入力とする ヒープ上のメソッドを呼出すことで アクセラレーション構造体を 直接割り当てられる ディスクリプターを使用して 割当てを行わない場合 ヒープからアクセラレーション構造を 割り当てるためのサイズと アライメントの要件は Metalデバイスが決定します ディスクリプタまたは アクセラレーション構造サイズを 提供する事でMetalデバイスから この情報を取得できます 最終的なサイズが決まればヒープから アクセラレーション構造を 割り当てることができます ヒープを使用する際には いくつかの注意点があります まずuseHeap:を呼び出し レイトレーシングパスの間 ヒープ内の全アクセラレーション構造を 常駐させる事をお忘れなく デフォルトではMetalはヒープから 割当てたリソースを追跡しません リソースハザードの追跡をオプトインするか 手動で同期を管理するかのどちらかです コマンドエンコーダ間の同期にはMTLFencesを コマンドバッファ間の同期には MTLEventsを使用できます 以上が今年度のMetalレイト レーシングAPIの新機能と 性能向上の内容です 次にDominikがレイト レーシングAppを開発する際 生産性を向上させるXcodeのMetalツールの 改善について説明します ありがとう Yi Xcode14のMetalツールには 多くの機能強化がありますが ここではレイトレーシングAppの開発時に特に 有用なものを紹介したい と思います Metalデバッガーを始めとし アクセラレーション構造ビューアー シェーダープロファイラー シェーダーデバッガーの改良について説明します そしてランタイムの Shader Validation(シェーダー検証)で締め括ります
まずアクセラレーション構造 ビューアーを見てみましょう Metalデバッガーのアクセラレーション 構造ビューアーでは アクセラレーション構造を 構成する全メッシュの ジオメトリとインスタンスを 詳細に確認できます
Xcode14ではプリミティブまたは インスタンスモーションによる アクセラレーション構造のデバッグと プリミティブ単位の データをインスペクタで視覚化する 新ハイライトモードがサポートされました 実際に見てみましょう アクセラレーション構造を モーションで使用している場合 ボトムバーにスクラバーが 表示され異なる時間での アクセラレーション構造を 見れるようになりました スクラバーの右側には 「再生」ボタンがあります これを利用しアニメーションを ループ再生できます ではアクセラレーション構造で 個々のプリミティブを 検査する方法を紹介しましょう 新しいプリミティブデータAPIを 使用している場合 特に便利です このためだけに新しいハイライト モードが用意されています プリミティブハイライトモードでは 全プリミティブデータにアクセスできます
また特定のプリミティブを選択 詳細な検査を行えます
左サイドバーではデータ行の 横に矢印が表示されています
矢印をクリックすると そのプリミティブに対応する データを表示する ポップオーバーが表示されます アクセラレーション構造 ビューアーの追加により アクセラレーション構造を 構成するすべての要素に プリミティブまでフルアクセス できるようになりました 次にシェーダープロファイラーの 改良点について説明します シェーダープロファイラーは パイプラインごとの 実行タイミングコストを提供し シェーダー性能に関する洞察を与えます Apple GPUではソースレベルでより細かく 命令カテゴリに分散した行ごと 実行コストを表示します Xcode14ではGPUキャプチャーの プロファイリングが更新 交差関数 可視関数 ダイナミック ライブラリーがサポートされました
ここで交差関数を使った レイトレーシングカーネルをご紹介 交差点関数の内部で行ごとの プロファイリング結果を 表示できるようになりました これにはコストに寄与する インストラクションカテゴリーの 内訳が含まれます
可視関数のプロファイリングも 同じように動作します
また同様にリンクされたダイナミック ライブラリのシェーダコードも 詳細なプロファイリング情報を 取得できるようになりました このようにパイプラインの 性能をコード一行に至るまで 完全に把握できるようになりました
シェーダーデバッガーに移ります シェーダーデバッガーは シェーダーコードの正確性を デバッグするためのユニークで非常に 生産性の高いワークフローを提供します シェーダープロファイラーと同様に リンク関数やダイナミックライブラリの デバッグを可能にするために サポートを拡張しました ここに可視関数テーブルを介して リンクされた可視関数を 呼び出すレイトレーシング-カーネルがあります
カーネルの実行を可視関数コードまで追いかけ コードが期待通りに動くかどうかを 検証できるようになったのです
またダイナミックライブラリの デバッグも同様です またパイプラインにリンク されている実行済みの ダイナミックライブラリに ジャンプイン・アウトも可能です これら追加機能により パイプラインにリンクされた 関数やライブラリに またがるシェーダーの実行を 完全に把握できるようになりました
さてキャプチャしシェーダー デバッガーに飛込む前に 実行時にシェーダー検証を 有効にすると良いでしょう
シェーダ検証はGPUの ランタイムエラーを診断する 優れた方法でアウトオブ バウンドメモリアクセス Nullテクスチャ読込みなどの問題を捕捉します Xcodeでシェーダー検証を 有効にするには「スキームの編集」 ダイアログから「実行」アクションを 選択し「診断」タブで 「シェーダー検証」チェックボックスに チェックを入れるだけです これで準備は万端です Metal3ではスタックオーバー フロー検出機能が追加され 未定義の動作になるような問題を すばやく見つけられるようになりました Metalシェーダーにおける関数スタックと スタックオーバーフローの 問題を簡単に説明します コールスタックとはMetalが シェーダー関数で使用する ローカルデータの値を格納する デバイスメモリ内の領域です 呼出される関数が コンパイル時にわからない場合 Metalはスタックに必要なメモリ量を 推定するためにあなたの助けを必要とします コンパイル時に不明な関数の 呼出しの例としては レイトレーシングの交差関数が考えられる カスタム交差関数を使用する場合 そのスペースを確保するため 最大呼出しスタック深度を 1に設定する必要があります これはデフォルトの値なので これ以上必要なことはありません しかしテーブル関数を使って 可視関数に呼び出す場合 これもコンパイル時に不明な 関数呼び出しの一例となります この例のように交差関数から このような呼び出しを行うと コールスタックは2階層になります
またダイナミックライブラリの呼び出しや 関数ポインタを使ったローカル関数の 呼び出しもその一例である この例ではコールスタックが4階層あり シェーダーのコンパイル時に 解決できない異なるタイプの 関数への呼び出しがネストされています Metalが適切な量のメモリを 確保し適切に設定するため 呼出しスタックの最大深度を 4に指定する必要があります 重要な事はコールスタッフ 深度の最大値をプログラムに対し 低く設定しすぎた場合 スタックオーバーフローが発生 未定義動作になる可能性があるという事です しかしシェーダー検証が 有効な状態で実行していれば そのような状況は早期に発見されXcodeに スタックオーバーフロー発生 場所に関する情報が表示される その後シェーダーコードを修正したり パイプラインディスクリプタの 最大呼び出しスタック深度を 調整したりできます Xcode14のMetalツールに対する これらの新しい改善はすべて レイトレーシングAppの パフォーマンスと正確さに ついて全体像と洞察が 得られることを保証します デバッグとプロファイリングの ためにMetalツールを最大限 活用する方法については 他のセッションをご覧ください
このセッションはAppのため Metalレイトレーシングの 性能を最大化する為に必要な すべてを説明してきました プリミティブデータなどの新機能を使って より高性能を引出しコードを 簡素化する方法を話しました アクセラレーション構造をこれまで以上に速く 便利に構築するための最適化技術や 機能についても説明しました 最後にXcode14のMetalツールの新機能を すべて網羅し開発中により深い洞察を 得ることができるようにしました ご視聴ありがとうございます
-
-
4:04 - Alpha testing with intersection functions
float alpha = texture.sample(sampler, UV).w; return alpha >= 0.5f; -
5:46 - Alpha testing intersection function
[[intersection(triangle, raytracing::triangle_data, raytracing::instancing)]] bool alphaTestIntersection(float2 coordinates [[barycentric_coord]], unsigned int primitiveIndex [[primitive_id]], unsigned int instanceIndex [[instance_id]], device GlobalData *globalData [[buffer(1)]], device InstanceData *instanceData [[buffer(0)]]) { device Material *materials = globalData->materials; InstanceData instance = instanceData[instanceIndex]; float2 UV = calculateSamplingCoords(coordinates, instance.uvs[primitiveIndex * 3 + 0], instance.uvs[primitiveIndex * 3 + 1], instance.uvs[primitiveIndex * 3 + 2]); int materialIndex = instance.materialIndices[primitiveIndex]; float alpha = materials[materialIndex].texture.sample(sam, UV).w; return alpha >= 0.5f; } -
6:48 - Primitive Data
struct PrimitiveData { texture2d<float> texture; float2 uvs[3]; }; -
7:08 - Alpha testing intersection function using per-primitive data
// Alpha testing intersection function [[intersection(triangle, raytracing::triangle_data, raytracing::instancing)]] bool alphaTestIntersection(float2 coordinates [[barycentric_coord]], const device PrimitiveData *primitiveData [[primitive_data]]) { PrimitiveData ppd = *primitiveData; float2 UV = calculateSamplingCoords(coordinates, ppd.uvs[0], ppd.uvs[1], ppd.uvs[2]); float alpha = ppd.texture.sample(sam, UV).w; return alpha >= 0.5f; } -
8:54 - Setting up per-primitive data
geometryDescriptor.primitiveDataBuffer = primitiveDataBuffer geometryDescriptor.primitiveDataElementSize = MemoryLayout<PrimitiveData>.size geometryDescriptor.primitiveDataStride = MemoryLayout<PrimitiveData>.stride geometryDescriptor.primitiveDataBufferOffset = primitiveDataOffset -
9:18 - Using per-primitive data
// Intersection function argument: const device void *primitiveData [[primitive_data]] // Intersection result: primitiveData = intersection.primitive_data; // Intersection query: primitiveData = query.get_candidate_primitive_data(); primitiveData = query.get_committed_primitive_data(); -
11:08 - Buffers from intersection function tables
device int *buffer = intersectionFunctionTable.get_buffer<device int *>(index); visible_function_table<uint(uint)> table = intersectionFunctionTable.get_visible_function_table<uint(uint)>(index); uint result = table[0](parameter); -
11:36 - Ray tracing from indirect command buffers
let icbDescriptor = MTLIndirectCommandBufferDescriptor() icbDescriptor.supportRayTracing = true -
15:43 - Parallel acceleration structure builds
for (index, accelerationStructure) in accelerationStructures.enumerated() { encoder.build(accelerationStructure: accelerationStructure, descriptor: descriptors[index], scratchBuffer: scratchBuffers[index % numScratchBuffers], scratchBufferOffset: 0) } -
17:28 - Setting vertex formats
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() geometryDescriptor.vertexFormat = .uint1010102Normalized -
18:29 - Creating transformation matrix buffer
var scaleTransform = MTLPackedFloat4x3(columns: ( MTLPackedFloat3Make( scale.x, 0.0, 0.0), MTLPackedFloat3Make( 0.0, scale.y, 0.0), MTLPackedFloat3Make( 0.0, 0.0, scale.z), MTLPackedFloat3Make(offset.x, offset.y, offset.z)) let transformBuffer = device.makeBuffer(length: MemoryLayout<MTLPackedFloat4x3>.size, options: .storageModeShared)! transformBuffer.contents().copyMemory(from: &scaleTransform, byteCount: MemoryLayout<MTLPackedFloat4x3>.size) -
18:51 - Setting transformation matrix buffer on geometry descriptor
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() geometryDescriptor.transformationMatrixBuffer = transformBuffer geometryDescriptor.transformationMatrixBufferOffset = 0 -
20:12 - Merging instances using transformation matrices
let sphereGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() sphereGeometryDescriptor.vertexBuffer = sphereVertexBuffer sphereGeometryDescriptor.indexBuffer = sphereIndexBuffer sphereGeometryDescriptor.transformationMatrixBuffer = sphereTransformBuffer let redBoxGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() redBoxGeometryDescriptor.vertexBuffer = boxVertexBuffer redBoxGeometryDescriptor.indexBuffer = boxIndexBuffer redBoxGeometryDescriptor.transformationMatrixBuffer = redBoxTransformBuffer let blueBoxGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() blueBoxGeometryDescriptor.vertexBuffer = boxVertexBuffer blueBoxGeometryDescriptor.indexBuffer = boxIndexBuffer blueBoxGeometryDescriptor.transformationMatrixBuffer = blueBoxTransformBuffer let primitiveASDescriptor = MTLPrimitiveAccelerationStructureDescriptor() primitiveASDescriptor.geometryDescriptors = [sphereGeometryDescriptor, redBoxGeometryDescriptor, blueBoxGeometryDescriptor] -
22:33 - Heap acceleration structure allocation
let heap = device.makeHeap(descriptor: heapDescriptor)! let accelerationStructure = heap.makeAccelerationStructure(descriptor: descriptor) let sizeAndAlign = device.heapAccelerationStructureSizeAndAlign(descriptor: descriptor) let accelerationStructure = heap.makeAccelerationStructure(size: sizeAndAlign.size)
-